
モデルの学習はうまくいったのに、本番データでは精度がガクッと落ちる…。 そんなとき、原因は「モデル」ではなく「データの分布のズレ」にあるかもしれません。
本記事では、学習データと本番データの違いを検出する手法「Adversarial Validation」を、アンサンブル回帰モデルを用いて実践的に解説します。 LightGBMを使ったコピペOKのPythonコード付きで、ズレの可視化からSHAPによる要因分析まで、ステップバイステップで紹介します。
🧠 学習時は高精度でも、本番で失速する理由は?
よくある“本番で精度が出ない”問題
モデルの学習はうまくいってる。クロスバリデーションでも高いスコアが出てる。 なのに、いざ本番データで予測してみると――「あれ?全然当たらない…」。
この「学習時」は高精度なのに、本番で失速する”という現象、実務ではよくある悩みのひとつです。 原因はさまざまですが、その中でも特に見落とされがちなのが「データの分布のズレ」です。
- 学習データではR²が0.9なのに、本番では0.4しか出ない
- クロスバリデーションでは安定していたのに、提出データでは大外れ
- モデルを変えても改善しない、特徴量を増やしても効果がない
こうしたとき、つい「モデルが悪いのかも」「特徴量が足りないのかも」と考えがちですが、 そもそも学習データと本番データの“性質”が違っていたら、モデルは正しく学習できません。
分布のズレがもたらす影響とは?
たとえば、学習データでは「特徴量A」が0〜100の範囲に分布していたのに、 本番データでは「特徴量A」が50〜150に偏っていたらどうなるでしょう?
モデルは「0〜100の世界」でしか学んでいないので、 「50〜150の世界」での予測には自信が持てません。
このような“見えないズレ”が、予測精度の低下を引き起こすのです。
そこで登場するのが、今回紹介するAdversarial Validationです。 この手法を使えば、学習データと本番データの違いを“分類問題として可視化”できます。
Adversarial Validation(敵対的検証)とは?
Adversarial Validation(敵対的検証)は、 学習データと本番データの“分布の違い”を検出するためのテクニックです。
やってることはシンプルで 「このデータは学習用か?本番用か?」を分類するモデルを作るだけです。
普通にグラフで分布を書いたらダメなの?
確かに「分布の違いを見たい」なら、グラフを重ねて確認するのが手軽です。ただし、グラフで可視化できるのはせいぜい2〜3次元まで。実際のデータは、数十〜数百の特徴量を持つ高次元空間に存在しており、単純なグラフではその全体像を捉えるのは困難です。
特に、アンサンブル学習のような高度なモデルは、複数の特徴量が絡み合う複雑なパターンを学習します。こうした相互作用をグラフで表現するのは現実的ではありません。
なぜ“分類モデル”でズレを検出できるの?
考え方は以下の通りです。
- 学習データにラベル0、本番データにラベル1を付けて、1つのデータセットにまとめる
- それを使って分類モデル(たとえばLightGBM)を学習させる
- モデルが「これは学習データ」「これは本番データ」と高精度で区別できるなら、両者は“違う”ということ!
逆に、分類精度がランダム(AUC ≒ 0.5)なら、 学習と本番の分布はほぼ同じと判断できます。
どんなときに使うの?
Adversarial Validation は、以下の用途で用います。
- モデルの精度が本番で急に落ちたとき
- クロスバリデーションでは良かったのに、未知データで通用しないとき
- 特徴量の分布が本番とズレていないか確認したいとき
どの特徴量がズレの原因かも特定可能
Adversarial Validationは、ただズレを検出するだけじゃなく、 「どの特徴量がズレの原因か?」を特定することも可能です。
これには、SHAP(Shapley値)を使って分類モデルの出力を解釈するのが効果的です。。
Adversarial Validationの実行手順
この章では、Adversarial Validatioの実行手順をソースコード付きで紹介します。
下記のプログラムでダミーデータが生成できますので、ご自身で試してみたい場合はご活用ください。
# ====================================================
# ダミーのテストデータを作成
# ====================================================
# 再現性のための乱数シード
np.random.seed(42)
# 学習データ(正規分布)
train_size = 1000
train = pd.DataFrame({
'feature_1': np.random.normal(loc=0, scale=1, size=train_size),
'feature_2': np.random.normal(loc=5, scale=2, size=train_size),
'feature_3': np.random.binomial(1, 0.3, size=train_size)
})
# 本番データ(少し分布をずらす)
test_size = 1000
test = pd.DataFrame({
'feature_1': np.random.normal(loc=0.5, scale=1.2, size=test_size), # 平均と分散を少し変える
'feature_2': np.random.normal(loc=4.5, scale=2.5, size=test_size),
'feature_3': np.random.binomial(1, 0.5, size=test_size) # 確率を変える
})
データとライブラリのセットアップ
まず初めに、学習データと本番データを準備します。ここでは、単純に分布を確認したいだけなので、正解データは不要です。逆に学習データに正解データが含まれている場合は、除外しておきましょう。
併せて、必要なライブラリをインポートしておきましょう。
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
import shap
import matplotlib.pyplot as plt今回は学習データと本番データを用意しましたが、たとえば特定の期間や設備などで精度が出ない場合、そのデータを使って分布を確認することもできます。
学習データと本番データを識別するためのラベルを付ける
次に、学習データに is_train = 1、本番データに is_train = 0 のラベルを付けて結合します。
# ====================================================
# 学習データと本番データを識別するためのラベルを付ける
# ====================================================
train['is_train'] = 1
test['is_train'] = 0
df = pd.concat([train, test], axis=0)Adversarial Validationを実装する(LightGBM使用)
結合ができたら、それを用いて分類モデルを作成します。今回はLightGBMを使いましたが、これは以下の特徴があるからです。
- 高次元・非線形な特徴量に強い:複雑な特徴量の相互作用を捉えるのが得意です
- 高速かつ高精度:大量のデータでも学習が速く、精度も高いです
- SHAPとの相性が良い:ズレの原因分析に使うSHAP値の計算が高速で安定しています
# ====================================================
# Adversarial Validationを実装する
# ====================================================
X = df.drop(columns=['is_train'])
y = df['is_train']
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=42)
# 分類モデルを学習させる
model = lgb.LGBMClassifier()
model.fit(X_train, y_train)
# ROC-AUC でズレを大きさを定量化する
y_pred = model.predict_proba(X_val)[:, 1]
auc = roc_auc_score(y_val, y_pred)
print(f"Adversarial AUC: {auc:.4f}")AUC(「Area Under the Curve)が 0.5 に近い場合、学習データと本番データの分布がほぼ同じと言えるため、精度低下の原因は他にあります。
AUCの値が0.5より大きい場合、2つの分布が異なるといえるため、分布が原因であることが濃厚になります。

LightGBMに限らず、XGBoostやCatBoost、ランダムフォレストなどの他の決定木ベースの手法でも同様のアプローチは可能です。 ただし、SHAPの可視化や学習速度を重視するなら、LightGBMが特に扱いやすいです。
SHAPで「ズレの原因」を可視化する
SHAPは、機械学習モデルの予測に対する各特徴量の貢献度を定量化する手法です。 Adversarial Validationでは、「このデータは学習用か?本番用か?」という分類モデルを作るので、 SHAPを使えば「どの特徴量がその判別に効いているか」が分かります。
下記プログラムを実行するとsummary plot(散布図)、bar plot(重要度ランキング)、上位特徴量の密度分布グラフが続けて表示されます。
# ====================================================
# SHAPで「ズレの原因」を可視化する
# ====================================================
# SHAP値を取得
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_val)
# リストかどうかで分岐
if isinstance(shap_values, list):
shap_to_plot = shap_values[1] # クラス1のSHAP値
else:
shap_to_plot = shap_values # そのまま使う
# 可視化
shap.summary_plot(shap_to_plot, X_val)
shap.summary_plot(shap_to_plot, X_val, plot_type="bar"summary plot(散布図)
これは SHAP summary plot(散布図タイプ) と呼ばれるもので、 「各特徴量がモデルの予測にどれだけ影響を与えたか」を、全サンプル分まとめて可視化したものです。
特徴量ごとの重要度だけでなく、どのような値がどの方向に影響しているかも読み取れるのが特徴です。
広がりが大きい特徴量は、モデルがその特徴量を強く使っている証拠であり、左右に偏っている特徴量は、分布のズレの原因になっている可能性が高いといえます。
- Y軸:特徴量の名前
上にあるほど、モデルにとって重要(=SHAP値の影響が大きい) - X軸:SHAP値(モデル出力への影響)
右に行くほど「学習データらしい」と判断される方向
左に行くほど「本番データらしい」と判断される方向 - 色:その特徴量の値
赤=値が高い、青=値が低い
色と位置の関係を見ることで、「どんな値のときにどちらに分類されやすいか」がわかる

bar plot(重要度ランキング)
これは、各特徴量がモデルの出力にどれだけ影響を与えたかの“平均的な大きさ”を棒グラフで表したものです。
棒が長い特徴量ほど、モデルがよく使っている(たとえば feature_1 の棒が一番長ければ、モデルは feature_1 を最も重視している)ということです
値の大小だけでなく、相対的な差にも注目します(feature_1 と feature_2 の差が大きければ、feature_1 の方が圧倒的に重要)。
- Y軸:特徴量の名前
上にあるほど、モデルにとって重要な特徴量。 - X軸:mean(|SHAP value|)
各特徴量のSHAP値の絶対値の平均。
「モデル出力に対して、どれだけ強く影響を与えたか」の平均的な大きさ。

上位の特徴量の密度分布
SHAPで重要とされた特徴量が、実際にどれくらい分布ズレしているかを、密度分布グラフの重ね合わせで可視化します。
# ====================================================
# 上位の特徴量の密度分布を比較する
# ====================================================
# 上位の特徴量を取り出す
top_features_cnt = 3
top_features = importance_df['feature'].head(top_features_cnt).tolist()
# サブプロットの準備(横に並べる)
fig, axes = plt.subplots(1, top_features_cnt, figsize=(20, 4), sharey=True)
# 各特徴量について分布を描画
for i, feature in enumerate(top_features):
ax = axes[i]
sns.kdeplot(data=train, x=feature, label='Train', fill=True, common_norm=False, ax=ax)
sns.kdeplot(data=test, x=feature, label='Test', fill=True, common_norm=False, ax=ax)
ax.set_title(feature)
ax.set_xlabel('')
if i == 0:
ax.set_ylabel('Density')
else:
ax.set_ylabel('')
ax.legend()
plt.suptitle('Top 5 Features by SHAP Importance: Distribution Comparison', fontsize=14)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()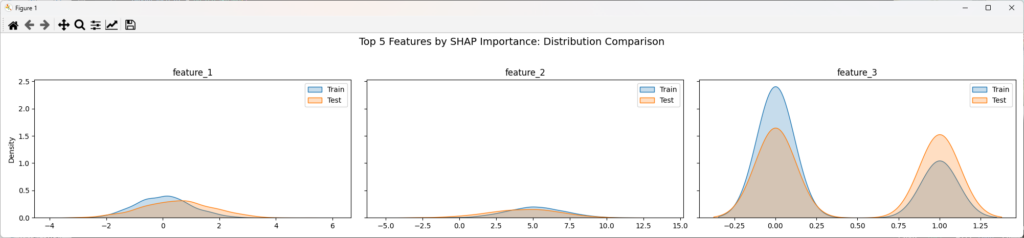
分布の違いを考慮したモデルの改善方法
本章では、Adversarial Validation(敵対的検証)によって訓練データとテストデータの分布に差異があることが判明した際、モデルの精度向上に効果のある対策を紹介します。
特徴量の見直し(Feature Selection)
AdversarialモデルのFeature Importance(特徴量の重要度)を確認すると、訓練データとテストデータの分布の違いに強く影響している特徴量が浮かび上がってきます。スコアの高い特徴量は、両者を区別するうえで特に重要であり、分布のズレの主な原因となっている可能性があります。
- 特徴量を除外する
分布のズレが大きく、モデルの汎化を妨げていると判断される場合は、思い切ってその特徴量を使わない選択も検討しましょう。 - 変換によって分布を整える
対数変換やビニング、標準化などの前処理を行うことで、訓練・テスト間の分布差を緩和できることがあります。
特に注意したいのが、カテゴリ変数や日付由来の特徴量です。これらはデータの収集時期や環境によって大きく偏りが出やすく、分布のズレを引き起こす主な原因となることがあります。 そのため、単に重要度が高いからといってすぐに除外するのではなく、「なぜその特徴がズレているのか?」を丁寧に分析することが大切です。
サンプリング調整
分布の違いは、本番で現れるパターンが訓練データに十分含まれていないことを示しているのかもしれません。 このようなズレを補正するために有効なのが、サンプリングの調整です。
具体的には、Adversarialモデルの出力(=各サンプルがどれだけテストデータに似ているかを示すスコア)を活用し、訓練データに重みをつけたり、再サンプリングを行ったりします。
たとえば、次のようなアプローチが考えられます:
- テストデータに似た訓練サンプルを多めに使う
Adversarialモデルの予測確率が高い(=テストデータに近い)サンプルを優先的に学習に使うことで、訓練データの分布をテストデータに近づけることができます。 - テストデータと大きく異なるサンプルを除外する
本番環境では登場しないような訓練データを除外することで、モデルが不要なパターンに過学習するのを防ぐことができます。
このアプローチは、特にデータの収集時期や取得元が異なる場合に効果を発揮します。 「どの訓練データが本番に近いのか?」という視点でデータを見直すことで、モデルの汎化性能を大きく向上させることができるのです。
ドメイン適応(Domain Adaptation)
分布の違いが構造的に大きく、単純な特徴量の除外やサンプリング調整だけでは対応しきれない場合、ドメイン適応(Domain Adaptation)の手法を検討するのが効果的です。
ドメイン適応とは、訓練データ(ソースドメイン)とテストデータ(ターゲットドメイン)の特徴空間を揃えることで、モデルが両者にまたがってうまく機能するようにするアプローチです。
代表的な手法には以下のようなものがあります。
- CORAL(CORrelation ALignment) 訓練データとテストデータの共分散行列を一致させることで、特徴量の分布を整える手法です。シンプルながら効果的で、前処理としても導入しやすいのが特徴です。
- DANN(Domain-Adversarial Neural Network) ニューラルネットワークを用いた手法で、特徴抽出器が「どちらのドメインかを判別できない」ように学習させることで、ドメイン間のギャップを埋めます。より高度なアプローチですが、深層学習モデルとの相性が良く、強力な適応性能を発揮します。
これらの手法は、特にデータの収集条件が大きく異なる場合や、未知の環境への適応が求められるタスクで有効です。 分布の違いを「補正する」のではなく、「吸収して学習する」発想が、ドメイン適応の強みです。
データの前処理を統一する
分布の違いが見えるとき、それが本質的なデータの違いではなく、前処理の不一致によって生じているケースも少なくありません。 そのため、まず確認すべきなのが、訓練データとテストデータに対して同じ前処理が適用されているかどうかです。
特に注意したいポイントは以下の通りです。
- カテゴリ変数のエンコーディング 訓練データとテストデータでカテゴリの出現順や種類が異なると、エンコーディング結果にズレが生じ、分布の違いとして現れてしまいます。
- 欠損値の補完方法 平均値や中央値で補完する場合、それぞれのデータセットで統計量が異なると、補完後の値にも差が出てしまいます。
- スケーリングや正規化 訓練データの統計量だけでスケーリングを行い、テストデータには別の基準を使ってしまうと、特徴量のスケールがずれてしまいます。
こうした前処理のズレは、Adversarial Validationで「分布が違う」と判定される大きな原因になります。 そのため、前処理のロジックは必ず一貫性を持たせ、訓練・テストの両方に同じ処理を適用することが重要です。
モデルの評価方法を工夫する
分布の違いに気づいたとき、見直すべきなのはデータそのものだけではありません。 モデルの評価方法、特にクロスバリデーションの分割方法にも工夫が必要です。
一般的なKFoldでは、データをランダムに分割するため、訓練データとテストデータの分布が実際の本番環境と異なる可能性があります。これでは、モデルの汎化性能を正しく評価できません。
そこで、以下のような分割方法を検討します。
- TimeSeriesSplit
時系列データの場合、未来の情報が過去に漏れないように、時間の流れを保ったまま分割する必要があります。TimeSeriesSplitを使えば、過去のデータで学習し、未来のデータで検証するという現実的なシナリオを再現できます。 - StratifiedKFold
ターゲット変数や重要なカテゴリの分布が偏っている場合は、StratifiedKFoldを使って、各分割でその分布を保つようにしましょう。これにより、評価結果のばらつきを抑え、より安定した性能指標が得られます。
評価方法を工夫することで、「本番での振る舞いに近い形でモデルを検証する」ことができ、過信や過小評価を防ぐことができます。 分布の違いに気づいたときこそ、評価の設計を見直す良い機会です。
AdversarialValidatorを簡単に扱える便利クラス
ここまでに掲載したソースコードをクラス(AdversarialValidator)にまとめました。DataFrameに学習データと本番データを指定することで、簡単にAUCの結果とグラフ化が行えます。
学習データに正解データや、その他不要なデータ(カラム)が含まれている場合、exclude_columns のリストに指定することで除外できます。
使い方は以下の通りです。
# 目的変数を除外してクラスを初期化
validator = AdversarialValidator(train_df=train, test_df=test, exclude_columns=['target'])
# モデル学習とAUC・SHAP計算
validator.fit()
# 上位特徴量の分布を比較
validator.plot_feature_distributions(top_n=3)ソースコード一式
AdversarialValidatorクラスのソースコードは以下の通りです。このままコピペしてお使いいただけます。
class AdversarialValidator:
def __init__(self, train_df, test_df, exclude_columns=None):
"""
Adversarial Validation を行うためのクラス。
Parameters:
----------
train_df : pd.DataFrame
学習データ(目的変数を含んでいてもOK)
test_df : pd.DataFrame
本番データ(目的変数は含まれていない想定)
exclude_columns : list of str, optional
結合・学習時に除外するカラム(例:目的変数 'target' など)
"""
self.exclude_columns = exclude_columns or []
self.train = train_df.copy()
self.test = test_df.copy()
# 学習データと本番データにラベルを付ける
self.train['is_train'] = 1
self.test['is_train'] = 0
# 除外カラムを除いた共通の特徴量だけを使う
self.features = [col for col in self.train.columns if col not in self.exclude_columns + ['is_train']]
self.df = pd.concat([
self.train[self.features + ['is_train']],
self.test[self.features + ['is_train']]
], ignore_index=True)
# モデル・SHAP関連の初期化
self.model = None
self.auc = None
self.shap_values = None
self.X_val = None
self.shap_importance = None
self.importance_df = None
def fit(self):
"""
Adversarial Validation モデルを学習し、AUCとSHAP値を計算する。
"""
# 特徴量とラベルに分割
X = self.df.drop(columns=['is_train'])
y = self.df['is_train']
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=42)
# LightGBMで分類モデルを学習
self.model = lgb.LGBMClassifier()
self.model.fit(X_train, y_train)
# AUCで分布のズレを定量化
y_pred = self.model.predict_proba(X_val)[:, 1]
self.auc = roc_auc_score(y_val, y_pred)
print(f"Adversarial AUC: {self.auc:.4f}")
# SHAP値を計算
explainer = shap.TreeExplainer(self.model)
shap_values = explainer.shap_values(X_val)
self.shap_values = shap_values[1] if isinstance(shap_values, list) else shap_values
self.X_val = X_val
# 特徴量ごとの平均絶対SHAP値を計算
self.shap_importance = np.abs(self.shap_values).mean(axis=0)
self.importance_df = pd.DataFrame({
'feature': X_val.columns,
'importance': self.shap_importance
}).sort_values(by='importance', ascending=False)
def plot_feature_distributions(self, top_n=3):
"""
SHAPで重要とされた上位特徴量の分布を、学習データと本番データで比較表示する。
Parameters:
----------
top_n : int
可視化する上位特徴量の数(デフォルトは3)
"""
top_features = self.importance_df['feature'].head(top_n).tolist()
fig, axes = plt.subplots(1, top_n, figsize=(6 * top_n, 4), sharey=True)
for i, feature in enumerate(top_features):
ax = axes[i] if top_n > 1 else axes
sns.kdeplot(data=self.train, x=feature, label='Train', fill=True, common_norm=False, ax=ax)
sns.kdeplot(data=self.test, x=feature, label='Test', fill=True, common_norm=False, ax=ax)
ax.set_title(feature)
ax.set_xlabel('')
if i == 0:
ax.set_ylabel('Density')
else:
ax.set_ylabel('')
ax.legend()
plt.suptitle(f'Top {top_n} Features by SHAP Importance: Distribution Comparison', fontsize=14)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()
まとめ
モデルの精度が本番で落ちる・・・ その原因の多くは、学習データと本番データの分布のズレにあります。
本記事では、学習データと本番データの分布のズレを検出・可視化する手法「Adversarial Validation」について紹介しました。
AUCによるズレの定量評価から、SHAPを用いたズレの原因特定、さらに分布の重ね合わせによる直感的な可視化まで、モデルの精度低下の“見えない原因”を明らかにするための実践的なアプローチを解説しました。
モデルの性能を最大限に引き出すには、まずデータの健全性を見極めることが不可欠です。
本記事が、アンサンブル学習による回帰モデルの精度向上に少しでもお役に立てば幸いです。








コメント