
オートエンコーダ(AutoEncoder)は、機械学習における異常検知手法の一つで、特に複雑な時系列データや高次元データの中から、再現しづらい=異常なパターンを検出できる点で注目されています。
このアルゴリズムは、データを一度圧縮(エンコード)し、そこから元の形に復元(デコード)するという構造を持ちます。正常なデータは高精度で復元できますが、異常なデータは再構成誤差が大きくなるため、その誤差を指標に異常を検出するというユニークなアプローチを取っています。
製造業においても、オートエンコーダは品質管理や設備保全における異常検知の手段として活用されており、センサーデータの中で通常とは異なる挙動やパターンの変化を早期に発見することができます。これにより、異常の兆候を見逃さず、予防保全や品質向上につなげることが可能です。
この記事では、オートエンコーダの基本構造から製造業での応用、さらに具体的な実装方法まで、コピペで使えるサンプルコード付きで解説します。
オートエンコーダ(AutoEncoder)とは?
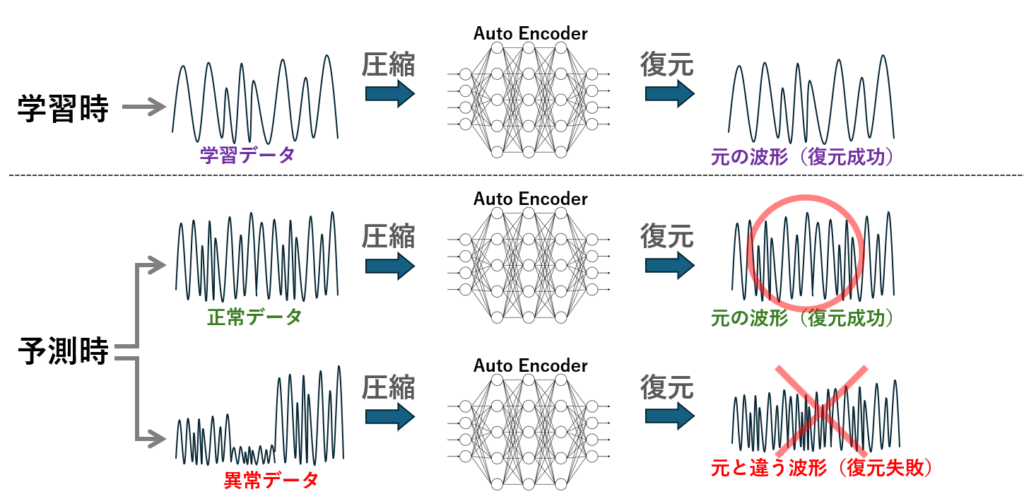
オートエンコーダは、異常検知に用いられるニューラルネットワークの一種で、入力データを圧縮し、再構成するというプロセスを通じて、データの特徴を学習します。
このモデルは、まず入力データを低次元の潜在空間に変換(エンコード)し、そこから元のデータに近い形に復元(デコード)します。正常なデータで学習されたオートエンコーダは、正常データを高精度で再構成できますが、異常なデータはうまく再現できず、再構成誤差が大きくなるという性質があります。
一般的に、異常なデータは学習時に登場しないため、モデルがそのパターンを再現できず、再構成誤差(例:平均二乗誤差)が大きくなることで異常として識別されます。
オートエンコーダは、学習済みモデルを保存しておけば、新しいデータに対しても再構成誤差を計算することで異常検知が可能です。これは、LOFのように全ての学習データを保持する必要がある手法とは異なり、モデルの再利用性や運用性に優れているという利点があります。
また、LSTMなどの時系列モデルと組み合わせることで、時間的な依存関係を考慮した異常検知も可能になります。
メリット
- パターン学習に強い:正常データの特徴を自動的に学習し、複雑なパターンや非線形な構造にも対応可能。
- 高次元データに強い:ニューラルネットワークの表現力を活かし、多数の特徴量を持つデータでも効果的に異常を検出できる。
- 再利用性:学習済みモデルを保存して、新しいデータに対しても再構成誤差で異常検知が可能。
- 柔軟な拡張性:LSTMやCNNなどと組み合わせることで、時系列や画像など多様なデータ形式に対応できる。
デメリット
- 学習に時間がかかる:ニューラルネットワークの学習には計算資源と時間が必要。
- 異常の定義が曖昧:再構成誤差の閾値設定が難しく、誤検知や見逃しのリスクがある。
- 過学習のリスク:異常データを含んだまま学習すると、異常も「正常」として再構成してしまう可能性がある。
- 解釈性が低い:LOFのように「なぜ異常か」を定量的に説明するのが難しい。
オートエンコーダに適したデータ
オートエンコーダは、正常なパターンを学習し、それと異なる構造を持つデータを検出するのに適しています。
- 製造業のセンサーデータにおいて、通常とは異なる波形や周期の乱れが現れるケース
- ネットワークトラフィックの中で、通常と異なる通信パターンや頻度が発生するケース
- 金融取引において、過去の取引履歴と異なる不自然な動きが見られるケース
このように、オートエンコーダは「再構成できない=異常」という視点で、パターンの逸脱を捉えるのが得意な手法です。
オートエンコーダーの製造業における用途
オートエンコーダは「正常なパターンを学習し、それと異なる挙動を検出する」ことに長けたアルゴリズムです。製造業の現場では、センサーや工程データが複雑に絡み合い、単純な閾値やルールベースでは見逃される異常が多く存在します。オートエンコーダは、そうした「再現できないパターン」を捉えることで、異常の兆候を早期に検出することができます。
- 設備の微細な異常検知
振動や温度などのセンサーデータを時系列で学習させることで、通常の動作パターンをモデル化できます。異常が発生すると再構成誤差が大きくなり、故障の前兆となる微細な変化を早期に検出可能です。 - 製品品質のばらつき検出
製品の寸法や重量などの測定値を入力とし、正常品の特徴を学習。わずかに異なるパターンを持つ製品は再構成誤差が大きくなり、不良品の兆候として検出できます。全体的には正常に見える中の“隠れた異常”を見つけるのに有効です。 - プロセス条件の逸脱監視
温度・圧力・流量などの工程パラメータを連続的に監視し、通常運転の時系列パターンを学習。異常な操作や設定ミスが発生した際には、再構成誤差の急上昇として現れ、リアルタイムでの逸脱検知が可能になります。 - サプライチェーンの異常挙動
在庫や出荷データの時系列を学習し、通常の物流パターンを把握。突発的な供給遅延や異常な在庫変動など、再構成できない動きを異常として検出し、サプライチェーンの安定化に貢献します。 - エネルギー効率の改善
設備の電力消費や稼働ログを学習し、通常のエネルギー使用パターンをモデル化。異常な消費や無駄な稼働が発生した場合、再構成誤差が増加し、エネルギーの無駄を可視化・削減する手がかりになります。
このように、オートエンコーダは「正常な状態を学習し、そこからの逸脱を検出する」という特性を活かして、製造業のさまざまな現場で異常検知に活用されています。
オートエンコーダの実装方法
モジュールのインストール
オートエンコーダを実装するには、Pythonと以下のライブラリが必要です。
pip install numpy pandas matplotlib scikit-learn tensorflow
もしエラーが出てうまくいかない場合は、Python 3.10 の環境を用意し、下記のようにバージョンを指定してインストールしてみてください。
注意:TensorFlowの対応バージョンについて 2025年12月現在、TensorFlow の安定版は Python 3.10 までに対応しています。 Python 3.11 や 3.12 では、DLL読み込みエラーなどが発生する可能性が高いため、非対応または非推奨です。 オートエンコーダなどを使用する場合は、Python 3.10 環境での実行を推奨します。
pip install -U pip
pip install tensorflow==2.15.0
pip install numpy==1.24.4
pip install protobuf==4.25.3
tensorflow は Microsoft の再配布パッケージが必要です。もしインストールされていない場合、下記のURLからインストーラーをダウンロードしてください。
サポートされている最新の Visual C++ 再頒布可能パッケージのダウンロード | Microsoft Learn

学習と異常検知
このサンプルでは、以下のステップで異常検知を行います。
- 正常データの生成
- オートエンコーダの構築と学習
- テストデータの投入
- 再構成誤差による異常判定
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam
# 1. 正常データの生成(2次元の3クラスタ)
np.random.seed(42)
X_train = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X_train + 2, X_train - 2, X_train]
# 2. オートエンコーダの構築
input_dim = X_train.shape[1]
encoding_dim = 2
input_layer = Input(shape=(input_dim,))
encoded = Dense(encoding_dim, activation='relu')(input_layer)
decoded = Dense(input_dim, activation='linear')(encoded)
autoencoder = Model(inputs=input_layer, outputs=decoded)
autoencoder.compile(optimizer=Adam(learning_rate=0.01), loss='mse')
# 3. 学習
autoencoder.fit(X_train, X_train, epochs=100, batch_size=16, verbose=0)
# 4. テストデータの生成(異常値を含む)
X_test = np.random.uniform(low=-4, high=4, size=(20, 2))
X_all = np.vstack([X_train, X_test])
# 5. 再構成誤差の計算
X_pred = autoencoder.predict(X_all)
mse = np.mean(np.square(X_all - X_pred), axis=1)
# 6. 異常判定(閾値は経験的に設定)
threshold = np.percentile(mse[:len(X_train)], 95)
y_pred = (mse > threshold).astype(int) # 1: 異常, 0: 正常
print("異常判定結果(1:異常, 0:正常):", y_pred[-20:].tolist())
実行結果は次の通りです。
10/10 [==============================] - 0s 619us/step
異常判定結果(1:異常, 0:正常): [1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0]
オートエンコーダによる異常検知では、再構成誤差(reconstruction error)をもとに、各データ点が正常か異常かを判定します。一般的に、再構成誤差が一定の閾値を超えた場合に「異常(1)」、それ以下であれば「正常(0)」とみなされます。
学習データを用いてモデルを訓練した場合、ほとんどの正常データは再構成誤差が小さくなり、正常(0)と判定されます。ただし、クラスタの境界付近や、学習時に十分に再現されなかったパターンについては、誤差が大きくなり、異常(1)と判定されることがあります。これは、オートエンコーダが訓練データの分布に強く依存するため、「再構成しづらい=未知のパターン」と判断されるためです。
一方で、テストデータとして投入された異常値は、学習データとは異なる特徴を持つため、再構成誤差が大きくなりやすく、多くが異常(1)と判定されます。オートエンコーダは入力を自己再構成する能力に基づいて異常を検出するため、学習時に見たことのないパターンをうまく再現できず、異常として扱うのです。
このように、オートエンコーダの異常判定では、正常データの中にも一部異常と判定される点が含まれることがありますが、これはモデルの再構成能力や訓練データの多様性に依存するため、ある程度は避けられません。実務での運用では、再構成誤差の閾値やネットワーク構造、学習データの選定などを調整することで、異常検知の精度を高めることが可能です。
可視化

上記のグラフは、学習データ(正常)とテストデータ(異常)を散布図としてプロットしたものです。
先ほどのプログラムの末尾に下記のコードを丸ごと挿入してもらえればグラフが描画されます。関数化しているので、コピペしてお使いいただけます。
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
def plot_ae_results(X_train, y_train_pred, X_test, y_test_pred):
"""
オートエンコーダによる異常検知結果を2次元散布図で可視化する
"""
plt.figure(figsize=(8, 8))
# 背景色(薄いブルー)
ax = plt.gca()
ax.set_facecolor("#eef7ff")
# -------- 学習データ(薄い色・丸) --------
plt.scatter(
X_train[y_train_pred == 0, 0],
X_train[y_train_pred == 0, 1],
c="#b6f2b6", # 薄い緑(正常)
marker="o",
s=60,
alpha=0.8,
edgecolor="black",
label="学習データ(正常)"
)
plt.scatter(
X_train[y_train_pred == 1, 0],
X_train[y_train_pred == 1, 1],
c="#ffb6b6", # 薄い赤(異常)
marker="o",
s=60,
alpha=0.8,
edgecolor="black",
label="学習データ(異常)"
)
# -------- テストデータ(濃い色・★) --------
plt.scatter(
X_test[y_test_pred == 0, 0],
X_test[y_test_pred == 0, 1],
c="darkgreen",
marker="*",
s=120,
alpha=0.95,
edgecolor="black",
linewidth=0.8,
label="テストデータ(正常)"
)
plt.scatter(
X_test[y_test_pred == 1, 0],
X_test[y_test_pred == 1, 1],
c="red",
marker="*",
s=120,
alpha=0.95,
edgecolor="black",
linewidth=0.8,
label="テストデータ(異常)"
)
plt.title("オートエンコーダ 異常検知結果")
plt.xlabel("特徴量 1")
plt.ylabel("特徴量 2")
plt.grid(True, alpha=0.3)
plt.legend()
plt.tight_layout()
plt.show()
# プロットを実行
y_pred_train = y_pred[:len(X_train)]
y_pred_test = y_pred[len(X_train):]
plot_ae_results(
X_train=X_train,
y_train_pred=y_pred_train,
X_test=X_test,
y_test_pred=y_pred_test
)
パラメータ調整とモデルの精度向上
オートエンコーダによる異常検知の精度は、ネットワーク構造・学習率・エポック数・閾値の設定など、複数のハイパーパラメータに大きく依存します。以下の要素を調整することで、異常検知性能を改善することが可能です。特に、データの分布や再構成誤差の傾向に応じた設計とチューニングが重要です。
| パラメータ名 | 説明 | 調整のポイント |
|---|---|---|
| encoding_dim | 中間層の次元数(圧縮の度合い) | 小さすぎると情報が失われ、大きすぎると異常を再構成してしまう。データの複雑さに応じて調整。 |
| activation | 活性化関数(例: 'relu', 'tanh') | 非線形性を導入する重要な要素。データの性質に応じて選択。 |
| optimizer / learning_rate | 学習率と最適化手法 | 学習の収束速度と安定性に影響。Adam + 適切な学習率(例: 0.001〜0.01)が一般的。 |
| epochs / batch_size | 学習回数とバッチサイズ | 過学習を防ぎつつ十分に学習させる。EarlyStoppingの導入も有効。 |
| threshold | 異常判定の再構成誤差の閾値 | 通常は学習データの誤差分布からパーセンタイルで設定(例: 95%)。 |
ハイパーパラメータの調整には、クロスバリデーションを活用するのが効果的です。 たとえば、GridSearchCV を用いることで、複数のパラメータの組み合わせを体系的に評価し、最適な構成を見つけることができます。
from sklearn.model_selection import GridSearchCV
from tensorflow.keras.wrappers.scikit_learn import KerasRegressor
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam
# モデル構築関数(KerasRegressor用)
def build_autoencoder(encoding_dim=2, learning_rate=0.01):
input_dim = X_train.shape[1]
input_layer = Input(shape=(input_dim,))
encoded = Dense(encoding_dim, activation='relu')(input_layer)
decoded = Dense(input_dim, activation='linear')(encoded)
autoencoder = Model(inputs=input_layer, outputs=decoded)
autoencoder.compile(optimizer=Adam(learning_rate=learning_rate), loss='mse')
return autoencoder
# ラッパーでKerasモデルをscikit-learn互換に
ae_regressor = KerasRegressor(build_fn=build_autoencoder, epochs=100, batch_size=16, verbose=0)
# 探索するパラメータの範囲
param_grid = {
'encoding_dim': [1, 2, 4],
'learning_rate': [0.001, 0.005, 0.01],
'epochs': [50, 100],
'batch_size': [8, 16, 32]
}
# グリッドサーチの実行
grid = GridSearchCV(estimator=ae_regressor, param_grid=param_grid, cv=3, scoring='neg_mean_squared_error', n_jobs=-1)
grid_result = grid.fit(X_train, X_train)
# 最適なパラメータを表示
print("Best parameters:", grid_result.best_params_)
オートエンコーダが簡単に使える自作クラス
オートエンコーダを簡単に使えるようにするために自作クラスとグラフ描画関数を作成しました。
このクラスのfit() メソッドは、1次元データが渡された場合、内部でreshape(-1, 1)で2次元に拡張しているため、問題なく処理できます。
異常検知を行うには
オートエンコーダは、学習済みモデルを固定して使うというよりも、常に新しいデータを入力して異常を検知する使い方が一般的です。 ここで「学習データ」と記載していますが、これは実際には異常検知の対象となるデータを指しており、モデルの学習と異常検知を同時に行うイメージで読み替えてください。
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ここにAutoEncoderUtilとグラフ描画関数のコードを張り付けるか、インポートしてください
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# --- 学習データの生成(3つのクラスター + 外れ値) ---
np.random.seed(42)
X_train_data = 0.5 * np.random.randn(100, 2)
X_train_data = np.r_[X_train_data + 1, X_train_data - 1, X_train_data]
# 異常値(外れ値)を追加
outliers = 3 * np.random.randn(10, 2) + 10
X_train_data = np.r_[X_train_data, outliers]
df_train = pd.DataFrame(X_train_data, columns=['feature1', 'feature2'])
# --- モデルの構築と学習 ---
detector = AutoEncoderUtil(df=df_train)
detector.fit(column=["feature1", "feature2"], epochs=50)
# --- 学習データに対する異常検知 ---
y_pred_train, loss, threshold = detector.predict(column=["feature1", "feature2"])
print("Train predictions (-1:異常, 1:正常):", y_pred_train)
# --- グラフの描画 ---
plot_ae_results(X_train_data, y_pred_train)
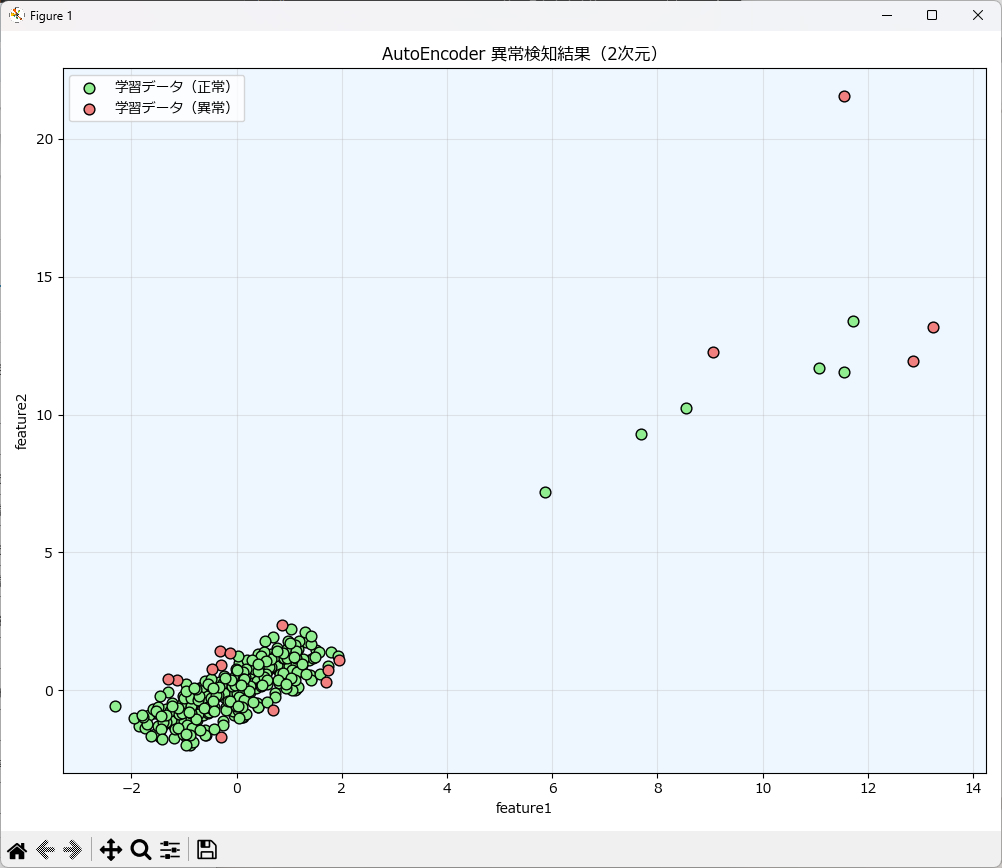
モデルを作成するには
モデルの学習と異常検知は明確に分かれており、学習時には fit()、異常検知時には predict() を使います。また、学習済みモデルと異常判定に使う閾値は、save_model() で保存し、load_model() で再利用することができます。
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ここにAutoEncoderUtilとグラフ描画関数のコードを張り付けるか、インポートしてください
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
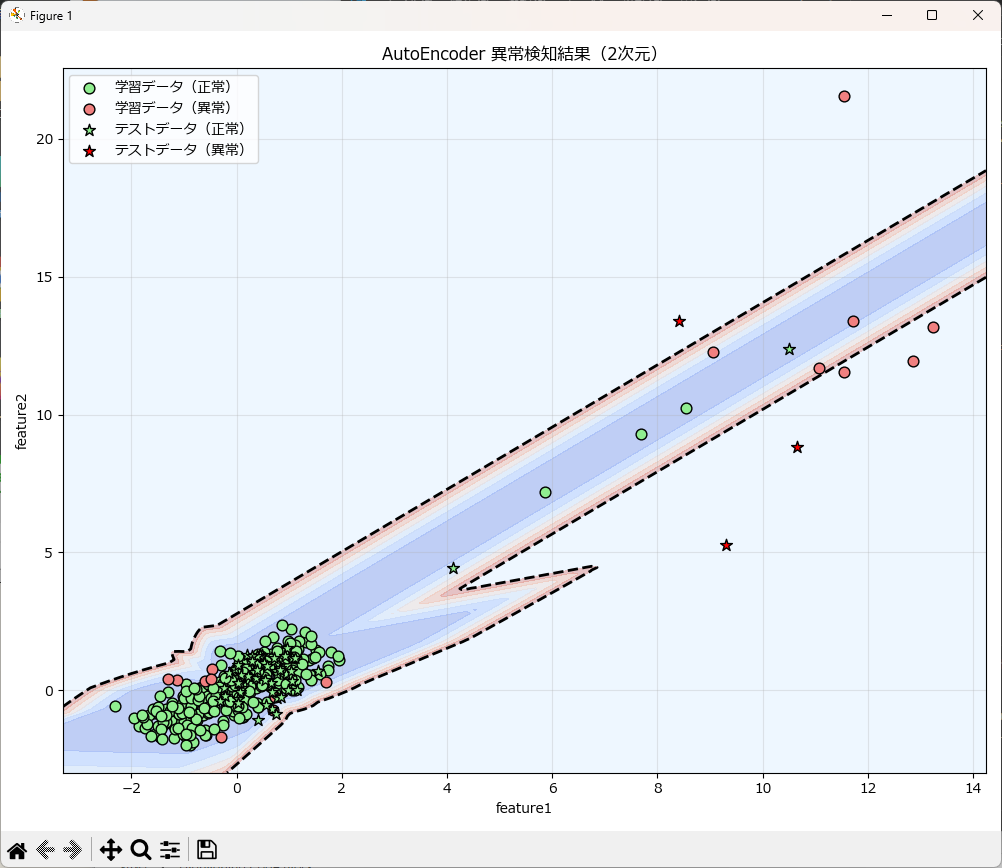
# --- 学習データの生成(3つのクラスター + 外れ値) ---
np.random.seed(42)
X_train_data = 0.5 * np.random.randn(100, 2)
X_train_data = np.r_[X_train_data + 1, X_train_data - 1, X_train_data]
# 異常値(外れ値)を追加
outliers = 3 * np.random.randn(10, 2) + 10
X_train_data = np.r_[X_train_data, outliers]
df_train = pd.DataFrame(X_train_data, columns=['feature1', 'feature2'])
# --- テストデータの生成(正常 + 異常) ---
np.random.seed(20)
X_test_normal = 0.5 * np.random.randn(50, 2) + 0.5
X_test_outliers = 3 * np.random.randn(5, 2) + 10
X_test_data = np.r_[X_test_normal, X_test_outliers]
df_test = pd.DataFrame(X_test_data, columns=['feature1', 'feature2'])
# --- モデルの構築と学習 ---
detector = AutoEncoderUtil(df=df_train)
detector.fit(column=["feature1", "feature2"], epochs=100, batch_size=16, lr=1e-3)
# --- 異常検知の実行 ---
y_pred_test, _, threshold = detector.predict(["feature1", "feature2"], df=df_test)
y_pred_train, _, _ = detector.predict(["feature1", "feature2"], df=df_train)
print(f"テストデータ中の異常値 (-1) の数: {np.sum(y_pred_test == -1)}")
print(f"テストデータ中の正常値 (1) の数: {np.sum(y_pred_test == 1)}")
# --- モデルの保存 ---
MODEL_PATH = 'ae_model.keras'
detector.save_model(MODEL_PATH)
# --- NumPy配列に変換(可視化用) ---
X_train = df_train[["feature1", "feature2"]].values
X_test = df_test[["feature1", "feature2"]].values
# --- 結果の可視化 ---
plot_ae_results(
X_train=X_train,
y_train_pred=y_pred_train,
X_test=X_test,
y_test_pred=y_pred_test,
model_util=detector,
threshold=threshold
)
新しいデータで異常検知するには
学習済みモデルをファイルに保存し、それを読み込んで利用することで新しいデータの異常検知が行えます。
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ここにAutoEncoderUtilとグラフ描画関数のコードを張り付けるか、インポートしてください
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# --- 学習データの生成 ---
np.random.seed(42)
X_train_data = 0.5 * np.random.randn(100, 2)
X_train_data = np.r_[X_train_data + 1, X_train_data - 1, X_train_data]
df_train = pd.DataFrame(X_train_data, columns=['feature1', 'feature2'])
X_train = df_train[['feature1', 'feature2']].values
# --- モデルの構築と学習 ---
detector = AutoEncoderUtil(df=df_train)
detector.fit(column=["feature1", "feature2"], epochs=100, batch_size=16, lr=1e-3)
# --- 学習データに対する異常検知 ---
y_pred_train, _, _ = detector.predict(["feature1", "feature2"], df=df_train)
# --- 学習データの結果を可視化 ---
plot_ae_results(
X_train=X_train,
y_train_pred=y_pred_train,
X_test=None,
y_test_pred=None,
model_util=detector
)
# --- モデルの保存 ---
MODEL_PATH = 'ae_model.keras'
detector.save_model(MODEL_PATH)
# --- モデルの再ロード ---
detector_loaded = AutoEncoderUtil()
detector_loaded.input_dim = 2 # 必要!モデル構築に使う
detector_loaded.load_model(MODEL_PATH)
# --- テストデータの生成 ---
np.random.seed(20)
X_test_data = np.random.uniform(low=-4, high=4, size=(100, 2))
df_test = pd.DataFrame(X_test_data, columns=['feature1', 'feature2'])
X_test = df_test[['feature1', 'feature2']].values
# --- テストデータに対する異常検知 ---
y_pred_test, _, _ = detector_loaded.predict(["feature1", "feature2"], df=df_test)
print("Test predictions:", y_pred_test)
# --- テストデータの結果を可視化 ---
plot_ae_results(
X_train=None,
y_train_pred=None,
X_test=X_test,
y_test_pred=y_pred_test,
model_util=detector_loaded
)
学習時の異常検知結果
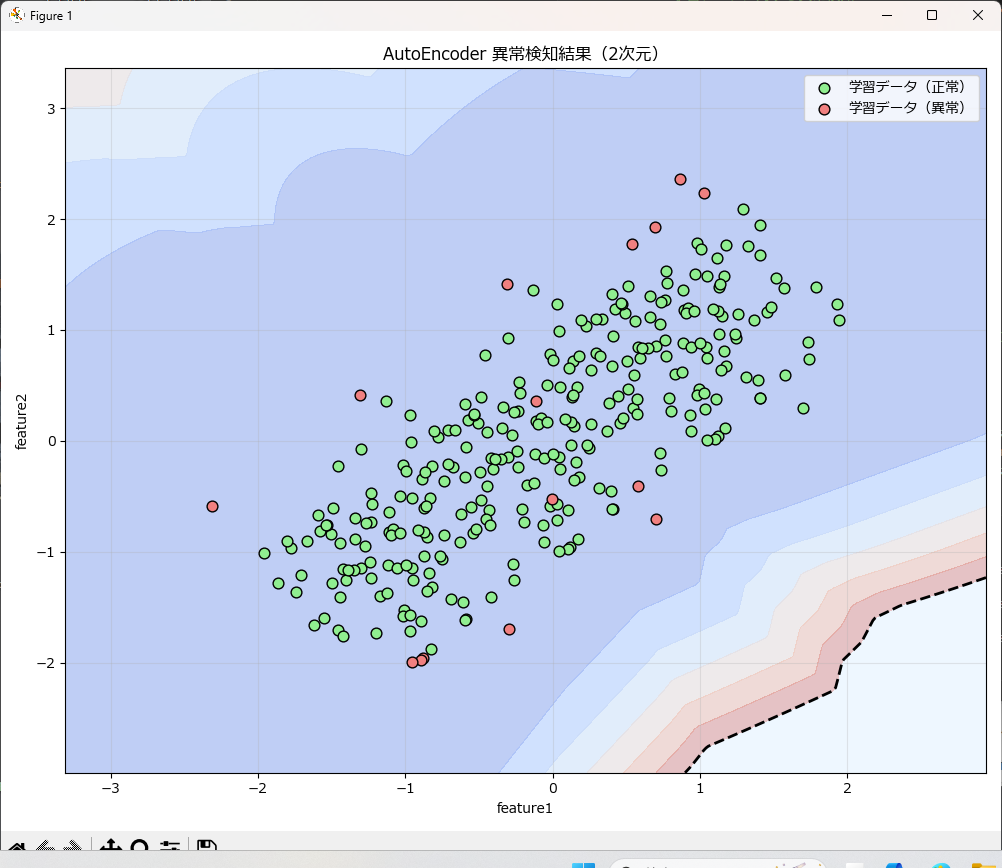
学習済みモデルに新しいデータで異常検知した結果
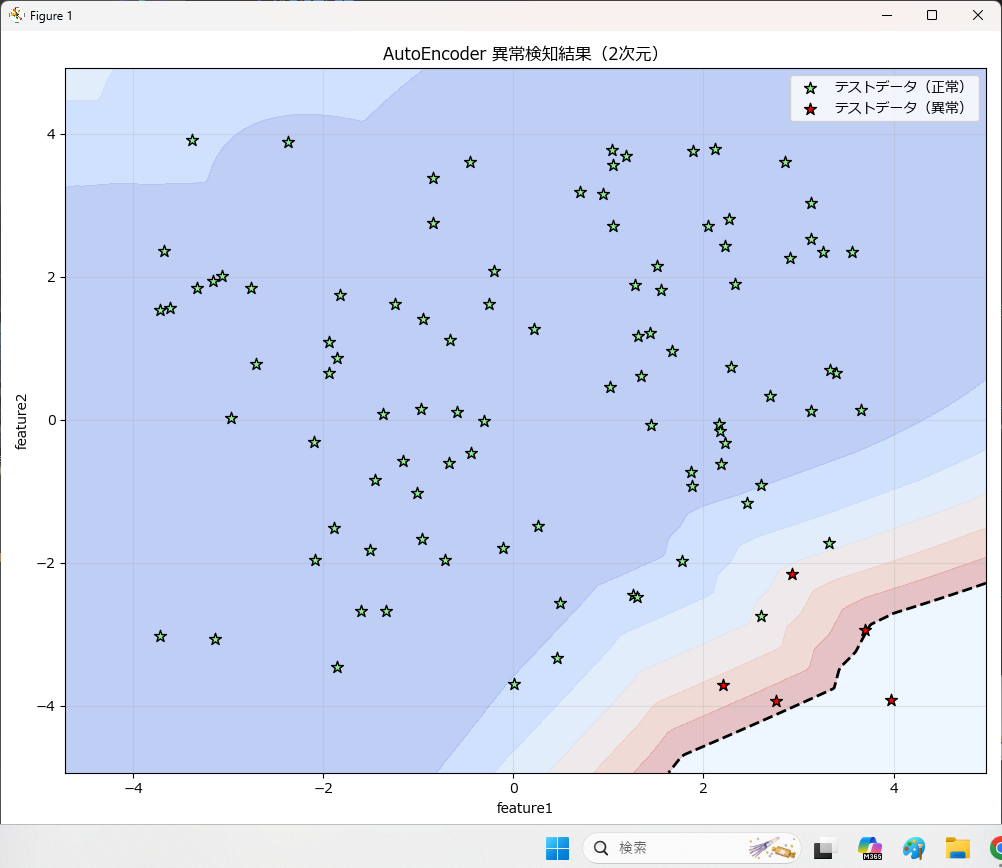
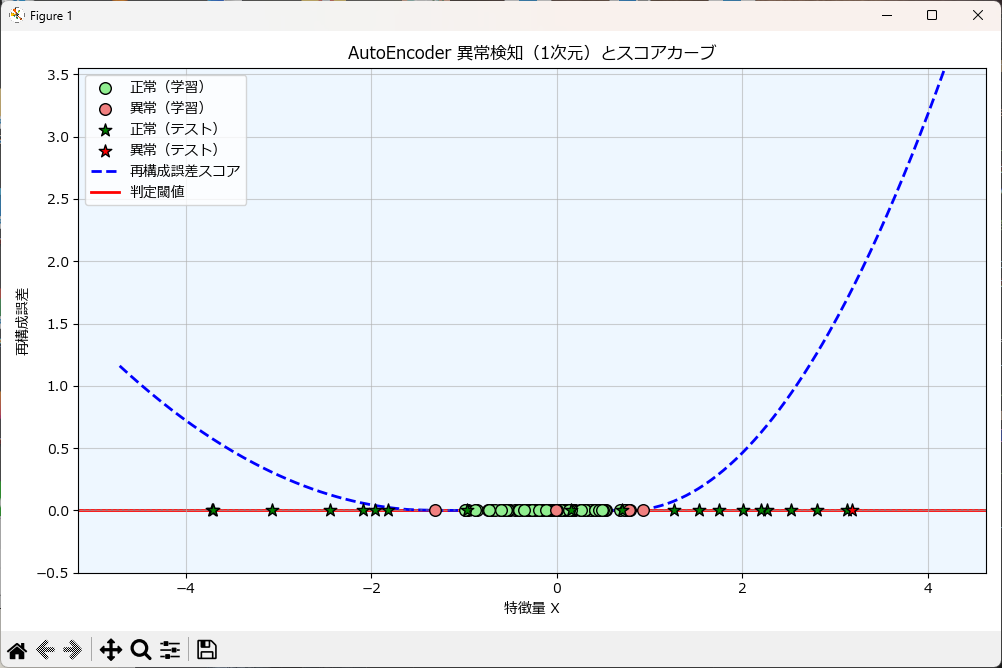
1次元の異常検知をするには
AutoEncoderUtilクラスの使い方は前述と全く同じですが、グラフ描画は plot_lof_results_1dを使用します。
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ここにAutoEncoderUtilとグラフ描画関数のコードを張り付けるか、インポートしてください
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# --- 学習データの生成(1次元) ---
np.random.seed(42)
X_train_data = 0.5 * np.random.randn(100).reshape(-1, 1)
df_train = pd.DataFrame(X_train_data, columns=['feature1'])
# --- モデルの構築と学習 ---
detector = AutoEncoderUtil(df=df_train)
detector.fit(column=["feature1"], epochs=100, batch_size=16, lr=1e-3)
# --- 学習データでの異常検知 ---
y_pred_train, errors_train, threshold = detector.predict(["feature1"], df=df_train)
print("Train predictions:", y_pred_train)
# --- テストデータの生成(異常を含む) ---
np.random.seed(20)
X_test_data = np.random.uniform(low=-4, high=4, size=(20,)).reshape(-1, 1)
df_test = pd.DataFrame(X_test_data, columns=['feature1'])
# --- テストデータでの異常検知 ---
y_pred_test, errors_test, _ = detector.predict(["feature1"], df=df_test)
print("Test predictions:", y_pred_test)
# --- NumPy配列に変換(プロット用) ---
X_train = df_train[["feature1"]].values
X_test = df_test[["feature1"]].values
# --- 1次元プロットで可視化 ---
plot_ae_results_1d(
X_train=X_train,
y_train_pred=y_pred_train,
X_test=X_test,
y_test_pred=y_pred_test,
model_util=detector,
threshold=threshold
)
AutoEncoderUtilクラスとグラフ描画関数リファレンス
| AutoEncoderUtilのグラフ描画関数 | 説明 |
|---|---|
| plot_ae_results_1d( X_train=None, y_pred_train=None, X_test=None, y_pred_test=None, model ) | 1次元データのオートエンコーダの結果をプロットする。学習データとテストデータを表示し、決定境界を描画する。 |
| plot_ae_results( X_train=None, y_pred_train=None, X_test=None, y_pred_test=None, model ) | 2次元データのオートエンコーダの結果をプロットする。学習データとテストデータを表示し、決定境界を描画する。 |
| AutoEncoderUtilのメソッド | 説明 |
|---|---|
| __init__(df=None, model_path=None) | クラスの初期化。データフレームまたは保存済みモデルのパスを受け取る。 |
| fit(column, epochs=50, batch_size=32, lr=1e-3) | オ指定したカラムのデータでオートエンコーダを構築・学習する。 |
| predict(column, df=None) | 指定したカラムのデータに対して再構成誤差を計算し、異常判定を行う。戻り値は (予測ラベル, 再構成誤差, 閾値)。 |
| read_csv(file_name, encoding="shift-jis") | CSVファイルを読み込み、内部の df にセットする。 |
| save_model(model_path) | 学習済みのモデルを指定パスに保存する(.keras など)。 |
| load_model(model_path=None) | モデルをファイルから読み込み、内部のモデルとしてセットする。model_path を省略すると、初期化時のパスを使用。 |
AutoEncoderUtilクラスとグラフ描画関数のソースコード
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import os
class AutoEncoderUtil:
def __init__(self, df=None, model_path=None):
self.df = df.copy() if df is not None else None
self.model = None
self.input_dim = None
if model_path:
self.load_model(model_path)
def build_model(self, input_dim):
input_layer = keras.Input(shape=(input_dim,))
encoded = layers.Dense(8, activation='relu')(input_layer)
encoded = layers.Dense(4, activation='relu')(encoded)
decoded = layers.Dense(8, activation='relu')(encoded)
output_layer = layers.Dense(input_dim)(decoded)
model = keras.Model(inputs=input_layer, outputs=output_layer)
model.compile(optimizer='adam', loss='mse')
return model
def fit(self, column, epochs=50, batch_size=32, lr=1e-3):
if self.df is None:
raise ValueError("DataFrameがセットされていません。")
X = self.df[column].values.astype(np.float32)
if X.ndim == 1:
X = X.reshape(-1, 1)
self.input_dim = X.shape[1]
self.model = self.build_model(self.input_dim)
# 学習率を指定してオプティマイザを作成
optimizer = keras.optimizers.Adam(learning_rate=lr)
self.model.compile(optimizer=optimizer, loss='mse')
self.model.fit(X, X, epochs=epochs, batch_size=batch_size, verbose=1)
print(f"学習完了!(lr={lr}, epochs={epochs}, batch_size={batch_size})")
def predict(self, column, df=None, threshold=None):
if self.model is None:
raise RuntimeError("モデルが学習またはロードされていません。")
if df is not None:
self.df = df
X = self.df[column].values.astype(np.float32)
if X.ndim == 1:
X = X.reshape(-1, 1)
reconstructed = self.model.predict(X, verbose=0)
loss = np.mean(np.square(X - reconstructed), axis=1)
if threshold is None:
threshold = np.percentile(loss, 95)
y_pred = np.where(loss > threshold, -1, 1)
return y_pred, loss, threshold
def save_model(self, path):
if self.model is None:
raise RuntimeError("モデルが学習されていません。")
self.model.save(path)
print(f"モデルを {path} に保存しました。")
def load_model(self, path):
if not os.path.exists(path):
raise FileNotFoundError(f"ファイルが見つかりません: {path}")
self.model = keras.models.load_model(path)
self.input_dim = self.model.input_shape[1]
print(f"モデルを {path} からロードしました。")
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
def plot_ae_results_1d(X_train=None, y_train_pred=None,
X_test=None, y_test_pred=None,
model_util=None, threshold=None):
"""
AutoEncoder の 1次元異常検知結果をプロット。
model_util: AutoEncoderUtil インスタンス
threshold: 再構成誤差のしきい値(Noneなら自動計算)
"""
plt.figure(figsize=(10, 6))
ax = plt.gca()
ax.set_facecolor("#eef7ff") # 背景色を設定!
# --- データ点の描画 ---
if X_train is not None and y_train_pred is not None:
X_train_flat = X_train.flatten()
plt.scatter(X_train_flat[y_train_pred == 1],
np.zeros_like(X_train_flat[y_train_pred == 1]),
c='lightgreen', edgecolors='k', s=70, label="正常(学習)", zorder=3)
plt.scatter(X_train_flat[y_train_pred == -1],
np.zeros_like(X_train_flat[y_train_pred == -1]),
c='lightcoral', edgecolors='k', s=70, label="異常(学習)", zorder=3)
if X_test is not None and y_test_pred is not None:
X_test_flat = X_test.flatten()
plt.scatter(X_test_flat[y_test_pred == 1],
np.zeros_like(X_test_flat[y_test_pred == 1]),
c='green', edgecolors='k', s=90, marker='*', label="正常(テスト)", zorder=4)
plt.scatter(X_test_flat[y_test_pred == -1],
np.zeros_like(X_test_flat[y_test_pred == -1]),
c='red', edgecolors='k', s=90, marker='*', label="異常(テスト)", zorder=4)
# --- スコアカーブの描画 ---
if model_util is not None and model_util.model is not None:
xx = np.concatenate([arr.flatten() for arr in [X_train, X_test] if arr is not None])
x_range = np.linspace(xx.min() - 1, xx.max() + 1, 400).reshape(-1, 1)
df_range = pd.DataFrame(x_range, columns=["feature"])
_, loss_scores, _ = model_util.predict(["feature"], df=df_range)
if threshold is None:
threshold = np.percentile(loss_scores, 95)
plt.plot(x_range, loss_scores, color='blue', linestyle='--', linewidth=2,
label="再構成誤差スコア", zorder=2)
plt.axhline(threshold, color='red', linestyle='-', linewidth=2,
label="判定閾値", zorder=1)
min_z, max_z = loss_scores.min(), loss_scores.max()
y_lim_min = min(min_z, -0.5)
y_lim_max = max(max_z, 0.5)
plt.ylim(y_lim_min, y_lim_max)
plt.axhline(0, color='gray', linestyle=':', alpha=0.5)
plt.title("AutoEncoder 異常検知(1次元)とスコアカーブ")
plt.xlabel("特徴量 X")
plt.ylabel("再構成誤差")
plt.grid(True, alpha=0.6)
plt.legend()
plt.tight_layout()
plt.show()
def plot_ae_results(X_train=None, y_train_pred=None,
X_test=None, y_test_pred=None,
model_util=None, threshold=None):
"""
AutoEncoder の 2次元異常検知結果をプロット。
model_util: AutoEncoderUtil インスタンス
threshold: 再構成誤差のしきい値(Noneなら自動計算)
"""
plt.figure(figsize=(10, 8))
ax = plt.gca()
ax.set_facecolor("#eef7ff") # 背景色を設定!
# --- データ結合と描画範囲の決定 ---
all_data = [arr for arr in [X_train, X_test] if arr is not None]
if not all_data:
print("プロットするデータがありません。")
return
X_all = np.concatenate(all_data)
x_min, x_max = X_all[:, 0].min() - 1, X_all[:, 0].max() + 1
y_min, y_max = X_all[:, 1].min() - 1, X_all[:, 1].max() + 1
# --- 背景スコアマップの描画 ---
if model_util is not None and model_util.model is not None:
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200),
np.linspace(y_min, y_max, 200))
grid = np.c_[xx.ravel(), yy.ravel()]
df_grid = pd.DataFrame(grid, columns=["feature1", "feature2"])
_, loss_grid, _ = model_util.predict(["feature1", "feature2"], df=df_grid)
Z = loss_grid.reshape(xx.shape)
if threshold is None:
threshold = np.percentile(loss_grid, 95)
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), threshold, 7),
cmap=plt.cm.coolwarm, alpha=0.3)
plt.contour(xx, yy, Z, levels=[threshold], colors='black', linewidths=2, linestyles='--')
# --- データ点の描画 ---
if X_train is not None and y_train_pred is not None:
plt.scatter(X_train[y_train_pred == 1, 0], X_train[y_train_pred == 1, 1],
c='lightgreen', edgecolors='k', s=60, label="学習データ(正常)", zorder=3)
plt.scatter(X_train[y_train_pred == -1, 0], X_train[y_train_pred == -1, 1],
c='lightcoral', edgecolors='k', s=60, label="学習データ(異常)", zorder=3)
if X_test is not None and y_test_pred is not None:
plt.scatter(X_test[y_test_pred == 1, 0], X_test[y_test_pred == 1, 1],
c='lightgreen', edgecolors='k', s=80, marker='*', label="テストデータ(正常)", zorder=4)
plt.scatter(X_test[y_test_pred == -1, 0], X_test[y_test_pred == -1, 1],
c='red', edgecolors='k', s=80, marker='*', label="テストデータ(異常)", zorder=4)
# --- グラフの体裁 ---
plt.title("AutoEncoder 異常検知結果(2次元)")
plt.xlabel("feature1")
plt.ylabel("feature2")
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.grid(True, alpha=0.3)
plt.legend()
plt.tight_layout()
plt.show()
# --- 学習データの生成(3つのクラスター + 外れ値) ---
np.random.seed(42)
X_train_data = 0.5 * np.random.randn(100, 2)
X_train_data = np.r_[X_train_data + 1, X_train_data - 1, X_train_data]まとめ
本記事では、近年注目を集める異常検知技術のなかでも、特にAutoEncoder(オートエンコーダ)を用いた手法の仕組みと、その強力な応用範囲について解説しました。
AutoEncoder は、教師なし学習に基づく異常検知アルゴリズムであり、特に製造業における設備保全(予知保全/PdM)や品質管理の自動化といった分野で幅広く活用されています。
AutoEncoder の最大の強みは、正常なデータの特徴を自己再構成する能力にあります。入力データを圧縮・復元する過程で、正常なパターンを学習し、それに基づいて再構成誤差を算出します。この誤差が大きいデータは「正常とは異なる」と判断され、異常として検出されます。
この特性により、AutoEncoder は複雑な非線形構造を持つデータや、高次元のセンサーデータに対しても高い柔軟性を持ち、特に異常状態が明示的に定義しづらいケース(例:機械の微細な劣化や突発的な異常挙動)において、優れた性能を発揮します。
この記事が、皆さんの異常検知タスクにおけるAutoEncoder活用の一助となれば幸いです。








コメント