
本記事は「【成功の秘訣】現場で使えるデータ分析手順を体系的に解説」で紹介した前処理(クレンジング)の具体的な手順と、前処理(クレンジング)で良く用いられる手法のPythonサンプルコードを紹介しています。
前処理(クレンジング)の目的

前処理(クレンジング)は、データ探索(事前分析)や探索的分析(EDA)で得られた知見をもとに、データの欠損値や異常値を処理し、データの品質を向上させることが目的です。
具体的には、以下の作業を行います。
- 欠損値の処理
- 異常値の処理
- データのスケーリング
- カテゴリーデータのエンコード
前処理(クレンジング)の手順

欠損値の処理
欠損値を含むデータは、DataFrameに実装されているメソッドを使うことで簡単に処理できます。
| 補完方法 | 補完方法 |
|---|---|
| 行ごと削除 | df.dropna(inplace=True) |
| ゼロ埋め (Zero Imputation) | df['column_name'].fillna(0, inplace=True) |
| 平均値補完 (Mean Imputation) | mean_value = df['column_name'].mean() df['column_name'].fillna(mean_value, inplace=True) |
| 中央値補完 (Median Imputation) | median_value = df['column_name'].median() df['column_name'].fillna(median_value, inplace=True) |
| 最頻値補完(Mode Imputation) | mode_value = df['column_name'].mode()[0] df['column_name'].fillna(mode_value, inplace=True) |
| 線形補完 (Linear Interpolation) | df['column_name'] = df['column_name'].interpolate(method='linear') |
| 前方埋め補完 (Forward Fill) | df['column_name'].fillna(method='ffill', inplace=True) |
| 後方埋め補完 (Backward Fill) | df['column_name'].fillna(method='bfill', inplace=True) |
| 機械学習モデル補完 (Imputation using Machine Learning models) | 回帰モデルやK近傍法を適用して補完する |
異常値の処理
統計学などの手法を用いて異常値を検出し、削除または別の値に置き換えます。異常値を検出する方法として、以下のものがよく使われます。
| Zスコア (Z-score) | Zスコアは、平均値からの標準偏差の数を使って変数の値を表現します。Zスコアは、標準正規分布(平均0、標準偏差1)において、平均値からの位置(どれだけ離れているか)を示す指標として用いられます。 |
|---|---|
| Tukeyの外れ値検出 (IQR法) | 四分位範囲(IQR)を用いて異常値を検出する手法です。IQRは第1四分位数と第3四分位数の差で、箱ひげ図でよく使用されます。 |
| 多変量異常値検出 | 複数複数の変数を考慮して異常値を検出する手法です。Mahalanobis距離などの手法が使用されます。 |
| 孤立した外れ値検出(Isolation Forest) | 決定木ベースの手法で、データセット内の異常値を特定します。データ内の孤立した異常値を検出するのに効果的です。 |
| DBSCAN | DBSCANは「Density-Based Spatial Clustering of Applications with Noise」の略で、密度に基づいたクラスタリング手法を用いて異常値を検出します。特に高密度領域から外れたデータポイントを異常値として特定します。 |
上記で特定した異常値をNaN(欠損値)に置き換えることで、欠損値と同じ処理で削除したり補完することが可能です。
column = "hoge"
z_scores = np.abs((df[column] - df[column].mean()) / df[column].std())
df[column] = df[column].mask(z_scores > threshold_sigma, NaN)データのスケーリング
スケーリングの目的は、特徴量の値を適切な範囲に変換することです。これにより、異なるスケールのデータ(例えば身長と体重など)が比較しやすくなります。また、外れ値の影響を軽減し、線形回帰やニューラルネットワークの学習効率を向上させる効果もあります。
| 正規化(Normalization) | データを0から1の範囲にスケーリングする手法です。 正規化は、データを0から1の範囲にスケーリングする手法です。最小値を0、最大値を1に変換することで、データを同じ尺度に揃えます。正規化は外れ値の影響を受けやすいという欠点がありますが、ニューラルネットワークなどのアルゴリズムに適しています。 |
|---|---|
| 標準化(Standardization) | 標準化は、データを平均が0、標準偏差が1となるように変換する手法です。 データの各値から平均を引き、標準偏差で割ることで、データを平均0、標準偏差1の正規分布に近い形に変換します。標準化は外れ値の影響を受けにくいという利点があり、線形回帰やロジスティック回帰などのアルゴリズムに適しています。 |
# 正規化(Normalization)のサンプル
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['column_name'] = scaler.fit_transform(df['column_name'])# 標準化(Standardization)のサンプル
import pandas as pd
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['column_name'] = scaler.fit_transform(df['column_name'] )カテゴリーデータのエンコード(カスタムエンコード)
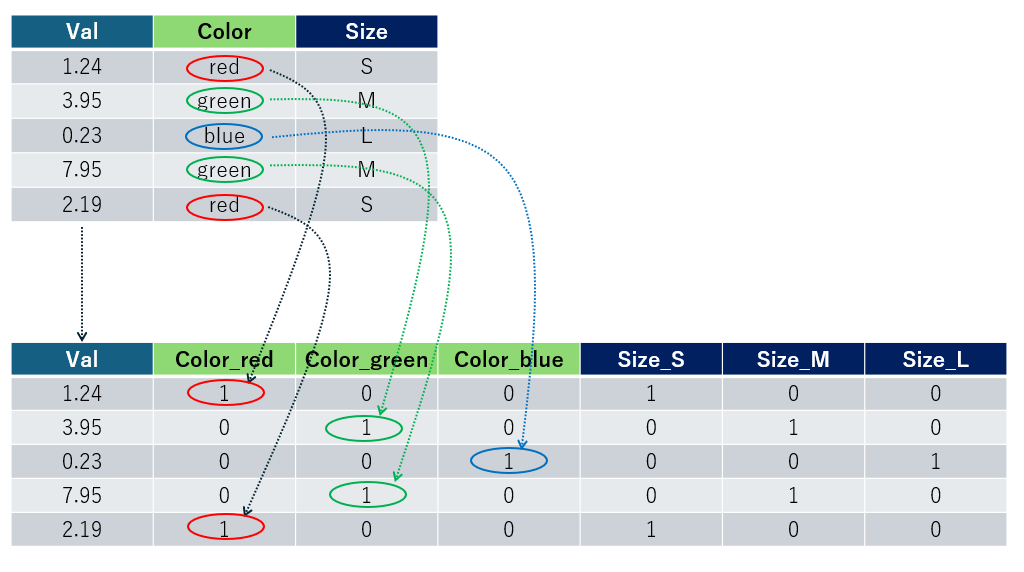
機械学習アルゴリズムで処理しやすいように、カテゴリー(例:"Man"や"Woman"、"Red"や"Yellow"などの文字列)が含まれたカラムの値を横展開する処理です。これは、使用する機械学習アルゴリズムに応じて実施されます。
実際のサンプルは、後述する「前処理(クレンジング)のプログラム4例」の「データのエンコード(カスタムエンコード)」で記載しています。
前処理(クレンジング)のプログラム4例
異常値の検出と置換
指定されたDataFrameのカラムに対して異常値を検出し、指定した値(value)で置換するサンプルです。Zスコア法とIQR法の2つの手法を用意しました。
なお、valueにNaNを指定することで、DataFrameが持つ欠損値補完メソッドを使用することができます。
import pandas as pd
import numpy as np
# Z-スコアによる異常値の検出と置換
def replace_outliers_with_value(df, columns, value, threshold_sigma=3):
for column in columns:
z_scores = np.abs((df[column] - df[column].mean()) / df[column].std())
df[column] = df[column].mask(z_scores > threshold_sigma, value)
return df
# IQRによる異常値の検出と置換
def replace_outliers_with_value_iqr(df, columns, value, threshold_iqr=1.5):
for column in columns:
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - threshold_iqr * IQR
upper_bound = Q3 + threshold_iqr * IQR
df[column] = df[column].mask((df[column] < lower_bound) | (df[column] > upper_bound), value)
return df正規化と標準化
指定されたDataFrameのカラムに対して、正規化または標準化を行う関数のサンプルです。
import pandas as pd
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 正規化の関数
def normalize_columns(df, columns):
scaler = MinMaxScaler()
df[columns] = scaler.fit_transform(df[columns])
return df
# 標準化の関数
def standardize_columns(df, columns):
scaler = StandardScaler()
df[columns] = scaler.fit_transform(df[columns])
return dfデータのエンコード(カスタムエンコード)
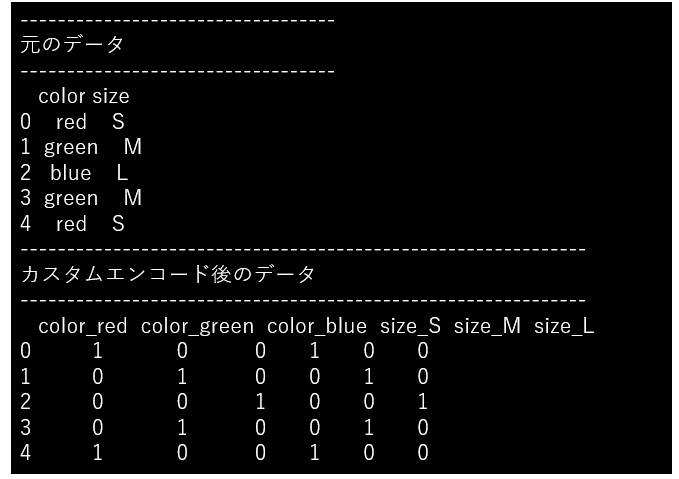
辞書で指定したエンコード情報に基づき、DataFrameのカテゴリカラムを横展開します。
import pandas as pd
def custom_encoding(df, encode_dict):
encoded_df = df.copy()
for column, categories in encode_dict.items():
for category in categories:
encoded_df[column + '_' + category] = (df[column] == category).astype(int)
encoded_df = encoded_df.drop(column, axis=1)
return encoded_df# サンプルデータの作成
data = {
'color': ['red', 'green', 'blue', 'green', 'red'],
'size': ['S', 'M', 'L', 'M', 'S']
}
df = pd.DataFrame(data)
# エンコード辞書
encode_dict = {'color': ['red', 'green', 'blue'], 'size': ['S', 'M', 'L']}
# カスタムエンコード
encoded_df = custom_encoding(df, encode_dict)
print("----------------------------------")
print("元のデータ")
print("----------------------------------")
print(df)
print("-------------------------------------------------------------")
print("カスタムエンコード後のデータ")
print("-------------------------------------------------------------")
print(encoded_df)まとめ
前処理(クレンジング)は、データ探索(事前分析)や探索的データ分析(EDA)による知見を活用し、データ品質の向上を目指すものです。
具体的な作業内容は以下の通りです:
- 欠損値の処理
- 異常値の処理
- データのスケーリング
- データのエンコード
本記事では、それぞれについて、具体的なPythonのサンプルコードを関数化して紹介しました。








コメント