バスケット分析(アソシエーション分析)は、顧客が一度の買い物で同時に購入する商品の組み合わせを解析し、商品間の関係性や購買行動のパターンを明らかにするデータ分析手法です。
小売業やマーケティング業界ではよく知られていますが、製造業においても、製品の不良原因や工程の最適化に有効な分析手法として活用されています。
今回は、Pythonを使用してバスケット分析を行う方法について説明します。
バスケット分析とは
バスケット分析とは、顧客が一度の購入で一緒に購入した商品のパターンを分析し、商品間の関連性や購買行動の傾向(パターン)を明らかにするデータマイニングの手法です。スーパーマーケットの買い物かご(バスケット)の中身から、どのような商品が一緒に購入されているのかを分析することから、この名が付いています。
製造業におけるバスケット分析は、小売業での買い物かごの内容を分析するのと同様に、製造工程における様々な要素を「バスケット」に見立て、それらの要素間の関連性を分析する手法です。例えば、
- 原材料の組み合わせ: どの原材料が一緒に使用されることが多いか
- 製造工程の順序: どの工程が連続して行われることが多いか
- 製品の不良原因: どの不良原因が一緒に発生しやすいのか
などを分析することで、製造プロセス全体の効率化や品質向上につなげることができます。
ちなみに、バスケット分析には、一般的にアプリオリアルゴリズムが使われます。
バスケット分析のことをアソシエーション分析と呼ぶことがあります。
しかし厳密には、バスケット分析はアソシエーション分析の一部として位置づけられています。
バスケット分析
目的: 主に小売業で、顧客が一度の買い物でどのような商品を一緒に購入するかを分析
対象: 購買データ(例:POSデータ)に限定
応用例: 「おむつとビール」のように、一見関連のなさそうな商品の組み合わせを見つけ出すことが可能
アソシエーション分析
目的: 広範なデータセットから事象間の関連性を見つけ出す
対象: 購買データに限らず、Webサイトの訪問履歴や問い合わせ履歴など、さまざまなデータが対象
応用例: ECサイトのレコメンドシステムや広告の最適化、顧客行動の分析など、幅広い分野で活用
製造業におけるバスケット分析のメリット
- 不良原因の特定:
複数の不良原因が同時に発生するパターンを特定し、根本原因の究明に役立てることができます。 - 工程の最適化:
工程間の関連性を分析し、工程順序の最適化や、不要な工程の削減に繋げることができます。 - 原材料の調達効率化:
頻繁に一緒に使用される原材料を特定し、調達計画の最適化に役立てることができます。 - 製品開発の支援:
新製品開発において、既存製品との共通点や相違点を分析し、開発期間の短縮やコスト削減に貢献できます。 - 設備故障の予兆検知:
特定の操作パターンと故障が連動している場合、故障の予兆を早期に捉え、予知保全に繋げることができます。 - 工程ボトルネックの特定:
特定の機械で頻繁に処理が滞っている場合、その原因を特定し、工程の改善に役立てることができます。 - 人為的なミス削減:
操作ミスと不良品発生の関連性を分析し、オペレーターへのフィードバックや、操作手順の改善に繋げることができます。 - 設備の最適利用:
設備の稼働状況と生産量の関係を分析し、設備の稼働率向上や、新たな設備投資の判断材料とすることができます。
Pythonでバスケット分析を行うための準備
バスケット分析を行うためには、pandas、mlxtend、numpy、matplotlib をインストールする必要があります。次のコマンドで、これらをインストールしてください。
pip install pandas
pip install mlxtend
pip install numpy
pip install matplotlib
バスケット分析の実行方法
以下は、自動車の整備部品をバスケット分析する場合のサンプルプログラムです。transactions には、分析対象となるデータをリスト形式で格納します。リストの各要素には、1回の整備で交換された部品群が含まれています。
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
# トランザクションデータ
transactions = [
['エンジン油', 'ブレーキ', 'タイヤ'], # 1回の整備で交換された部品群
['冷却水', 'エンジン油', 'タイヤ'], # 1回の整備で交換された部品群
['タイヤ', 'ブレーキ', 'エンジン油'], # 1回の整備で交換された部品群
]
# トランザクションデータをエンコード
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 頻出アイテムセットの抽出(戻り値はDataFrame)
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
# アソシエーションルールの生成(戻り値はDataFrame)
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1.0)
# 結果の表示
print("頻出アイテムセット:")
print(frequent_itemsets)
print("\nアソシエーションルール:")
print(rules)
実行すると次の内容が表示されます。frequent_itemsets、rules ともに DataFrame として結果が格納されています。
頻出アイテムセット:
support itemsets
0 1.000000 (エンジン油)
1 1.000000 (タイヤ)
2 0.666667 (ブレーキ)
3 1.000000 (エンジン油, タイヤ)
4 0.666667 (エンジン油, ブレーキ)
5 0.666667 (タイヤ, ブレーキ)
6 0.666667 (エンジン油, ブレーキ, タイヤ)
アソシエーションルール:
antecedents consequents antecedent support consequent support support confidence lift leverage conviction zhangs_metric
0 (エンジン油) (タイヤ) 1.000000 1.000000 1.000000 1.000000 1.0 0.0 inf 0.0
1 (タイヤ) (エンジン油) 1.000000 1.000000 1.000000 1.000000 1.0 0.0 inf 0.0
2 (エンジン油) (ブレーキ) 1.000000 0.666667 0.666667 0.666667 1.0 0.0 1.0 0.0
3 (ブレーキ) (エンジン油) 0.666667 1.000000 0.666667 1.000000 1.0 0.0 inf 0.0
4 (タイヤ) (ブレーキ) 1.000000 0.666667 0.666667 0.666667 1.0 0.0 1.0 0.0
5 (ブレーキ) (タイヤ) 0.666667 1.000000 0.666667 1.000000 1.0 0.0 inf 0.0
6 (エンジン油, ブレーキ) (タイヤ) 0.666667 1.000000 0.666667 1.000000 1.0 0.0 inf 0.0
7 (エンジン油, タイヤ) (ブレーキ) 1.000000 0.666667 0.666667 0.666667 1.0 0.0 1.0 0.0
8 (タイヤ, ブレーキ) (エンジン油) 0.666667 1.000000 0.666667 1.000000 1.0 0.0 inf 0.0
9 (エンジン油) (タイヤ, ブレーキ) 1.000000 0.666667 0.666667 0.666667 1.0 0.0 1.0 0.0
10 (ブレーキ) (エンジン油, タイヤ) 0.666667 1.000000 0.666667 1.000000 1.0 0.0 inf 0.0
11 (タイヤ) (エンジン油, ブレーキ) 1.000000 0.666667 0.666667 0.666667 1.0 0.0 1.0 0.0
頻出アイテムセットには、'support'と'itemsets' のカラムがあります。
一方、アソシエーションルールには、'antecedents', 'consequents', 'antecedent support', 'consequent support', 'support', 'confidence', 'lift', 'leverage', 'conviction', 'zhangs_metric' のカラムがあります。
アソシエーションルールの可視化
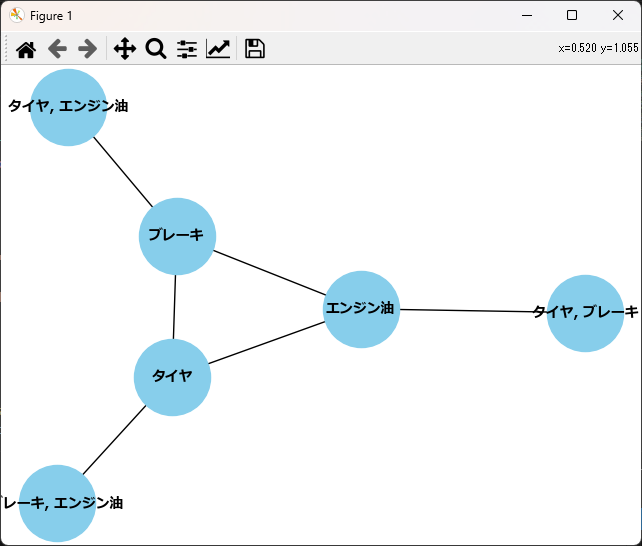
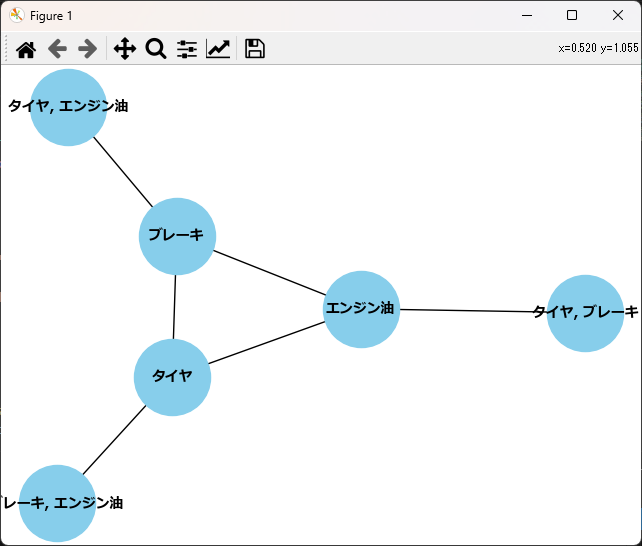
アソシエーションルールは、ネットワーク図を使って可視化することができます。
import matplotlib.pyplot as plt
import networkx as nx
~省略(ここに先ほど紹介したサンプルプログラムを挿入してください。~
# ネットワーク図の作成
G = nx.from_pandas_edgelist(rules, 'antecedents', 'consequents', ['support', 'confidence', 'lift'])
labels = {node: ', '.join(list(node)) for node in G.nodes()}
pos = nx.spring_layout(G)
nx.draw(G, pos, labels=labels,with_labels=True, node_size=3000, node_color="skyblue", font_size=10, font_color="black", font_weight="bold",font_family='Meiryo')
plt.savefig("d:/aaa.png")
plt.show()
ノードが中心に位置している場合、これらのアイテムが他の多くのアイテムと強く関連していることを示しています。逆に、外側に位置しているノードは、他のアイテムとの関連性が比較的弱いことを示しています。
今回の例では、「ブレーキ」、「エンジン油」、「タイヤ」が中心にあるため、他の多くのアイテムと強く関連していると解釈できます。
バスケット分析結果の見方(評価ポイント)
頻出アイテムセット(support itemsets)
support(支持度)は確率ではなく、あるアイテムセットがトランザクション(例えば、一回の購入)に含まれる割合を表す指標です。
値は0から1の間の値を取り、1に近いほど、そのアイテムセットが多くのトランザクションに含まれていることを示します。つまり、非常に頻繁に一緒に購入されているということです。
0に近いほど、そのアイテムセットがほとんどのトランザクションに含まれていないことを示します。
頻出アイテムセット:
support itemsets
0 1.000000 (エンジン油)
1 1.000000 (タイヤ)
~省略~
今回の例では、エンジン油のsupportが1.0、タイヤのsupportが1.0となっています。これは、全てのトランザクションにおいて、エンジン油とタイヤが必ず含まれていることを意味します。言い換えると、全ての顧客がエンジン油とタイヤを必ず購入しているという状態を表しています。
アソシエーションルール
あるアイテムセットが与えられたときに、別のアイテムセットがどれくらいの確率で同時に発生するかを示すルールです。今回の例では、「エンジン油」を購入すると、「タイヤ」も必ず購入する、というルールが導き出されています。
アソシエーションルール:
antecedents consequents antecedent support consequent support support confidence lift leverage conviction zhangs_metric
0 (エンジン油) (タイヤ) 1.000000 1.000000 1.000000 1.000000 1.0 0.0 inf 0.0
| 項目名 | 説明 |
|---|---|
| support | あるアイテムセットがトランザクションに含まれる割合。サポート値が高いほど、そのアイテムセットは頻繁に購入されていることを意味します。 |
| confidence | あるアイテムセットAが与えられたとき、別のアイテムセットBも含まれる確率。自信度が高いほど、AとBの間に強い関係性があることを意味します。 |
| lift | AとBの同時発生確率が、AとBが独立に発生する場合の確率と比べてどれだけ大きいのかを示す指標。リフト値が1より大きい場合、AとBの間に正の相関関係があると考えられます。 |
| leverage | ルールの興味深さを測る指標。レバレッジが大きいほど、ルールが偶然ではなく、意味のあるものである可能性が高いと考えられます。 |
| conviction | ルールの信頼性を測る指標。コンビクションが大きいほど、ルールが信頼できるものである可能性が高いと考えられます。 |
| zhangs_metric | ルールの信頼性を測るもう一つの指標です。 |
今回の例では、以下のことが読み取れます。
エンジン油とタイヤの間に強い関連性がある: リフト値が1.0であることから、エンジン油を購入する顧客は必ずタイヤも購入するという非常に強い関連性があることがわかります。
エンジン油とタイヤは常に一緒に購入されている: 全てのトランザクションで、エンジン油とタイヤが同時に購入されています。
バスケット分析を手軽に実行できるBasketAnalyzerクラス
TF-IDFをもっと簡単に使えるようにするため、BasketAnalyzer クラスを作成しました。下記は使い方のサンプルです。
from basket_analyzer import BasketAnalyzer
# トランザクションデータ
transactions = [
['エンジン油', 'ブレーキ', 'タイヤ'],
['冷却水', 'エンジン油', 'タイヤ'],
['タイヤ', 'ブレーキ', 'エンジン油'],
]
# インスタンス生成
ba = BasketAnalyzer()
# バスケット分析を行い、結果を受け取る
frequent_itemsets,rules = ba.analyze(transactions)
# 結果の表示
print("頻出アイテムセット:")
print(frequent_itemsets)
print("\nアソシエーションルール:")
print(rules)BasketAnalyzer に実装されているメソッドは以下の通りです。
| メソッド名 | 説明 | 引数 | 戻り値 |
|---|---|---|---|
| __init__ | インスタンスの 初期化 | transactions :list トランザクションデータのリスト。 省略時は空のリスト。(省略時=[]) metric :str アソシエーションルールの評価指標。 (省略時= “lift”) min_threshold :float アソシエーションルールの最小評価値。 (省略時= 1.0) min_support :float 頻出アイテムセットの最小支持度 (省略時=0.5) use_colnames :bool 頻出アイテムセットの列名の使用有無。 (省略時=True) | インスタンス |
| load_transactions | データの読み込み | file_name:str 読み込むファイルのパス delimiter :str ファイル内のデータを区切る文字 (省略時= “,”) encoding:str エンコーディング(省略時="shift-jis") | なし |
| analyze | バスケット分析の実行 | transactions :list トランザクションデータのリスト (省略時=sefl.toransactions の値) | frequent_itemsets, rules |
load_transactions で読み込むことができるファイルはCSVではなく、単語(ワード)がカンマ区切りで列挙され、行末に改行コードがあるテキストファイルです。
従って、1行に含まれるカンマの数(ワードの数)を合わせる必要はありません。
エンジン油,ブレーキ,タイヤ,・・・・・・改行
冷却水,エンジン油,タイヤ,・・・・・・・・・・・改行
タイヤ, ブレーキ,エンジン油,・・・・・・・・改行
ソースコード
basket_analyzer.py というファイル名で、下記のソースコードを保存してください。
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
class BasketAnalyzer:
"""
バスケット分析を行うクラス
"""
def __init__(self, transactions=[], metric="lift", min_threshold=1.0, min_support=0.5, use_colnames=True):
"""
初期化メソッド
:param transactions: トランザクションデータのリスト (list)
:param metric: アソシエーションルールの評価指標 (str)
:param min_threshold: アソシエーションルールの最小評価値 (float)
:param min_support: 頻出アイテムセットの最小支持度 (float)
:param use_colnames: 頻出アイテムセットの列名を使用するかどうか (bool)
"""
self.transactions = transactions
self.metric = metric
self.min_threshold = min_threshold
self.min_support = min_support
self.use_colnames = use_colnames
self.frequent_itemsets = []
self.rules = []
def load_transactions(self, file_name, delimiter=",", encoding="shift-jis"):
"""
ファイルからトランザクションを読み込むメソッド
:param file_name: 読み込むファイルのパス (str)
:param delimiter: ファイル内のデータを区切る文字 (str)
:param encoding: ファイルのエンコーディング (str)
"""
with open(file_name, encoding=encoding) as f:
lines = f.readlines()
self.transactions = list([line.strip().split(delimiter) for line in lines])
def analyze(self, transactions=[]):
"""
トランザクションデータを分析し、頻出アイテムセットとアソシエーションルールを生成するメソッド
:param transactions: トランザクションデータのリスト (list)
:return: 頻出アイテムセットとアソシエーションルール (tuple)
"""
# 引数が空のリストなら、self.transactionsを代入する
transactions = self.transactions if transactions == [] else transactions
# トランザクションデータをエンコード
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 頻出アイテムセットの抽出
self.frequent_itemsets = apriori(df, min_support=self.min_support, use_colnames=self.use_colnames)
# アソシエーションルールの生成
self.rules = association_rules(self.frequent_itemsets, metric=self.metric, min_threshold=self.min_threshold)
return self.frequent_itemsets, self.rulesまとめ
今回は、Pythonで バスケット分析(=アソシエーション分析) を行うための方法と、結果を評価する際のポイント、バスケットを簡単に利用するためのBasketAnalyzerクラスについて紹介しました。
バスケットはマーケティングでよく使われますが、製造業のデータ分析にも活用できます。不良原因の特定や工程の最適化、操作ログや稼働ログから共通点や相違点を見つけるなど、多くの使い方があります。
この記事を参考にして、製造系データ分析でも積極的にバスケットを使っていきましょう。








コメント