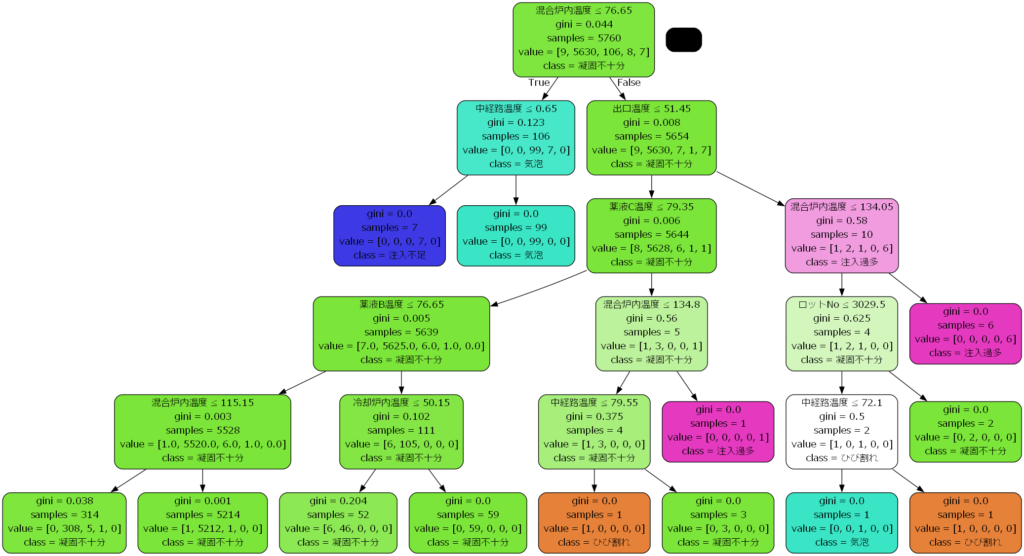
Pythonで機械学習を行う際、決定木はシンプルかつ効果的なアルゴリズムとして人気です。
この記事では、初心者でも簡単に実装できる決定木分析の手順を、サンプルコードと共に詳しく解説します。
データの前処理から、モデルの訓練、可視化まで、Pythonのスクリプトをコピーして実行するだけで、すぐに結果を得られる内容となっています。
これを機会に、ご自身の課題に対して決定木分析を実践してみてください。
テストデータのダウンロードURL
本記事のサンプルプログラムを実行する場合、下記からサンプルデータをダウンロードしてお使いください。
データに関する詳細は、「【実践データ】本記事で使うテストデータの内容と入手方法について」に記載しています。
本記事では、このテストデータの中にある「生産データ.csv」を使用しています。
決定木とは
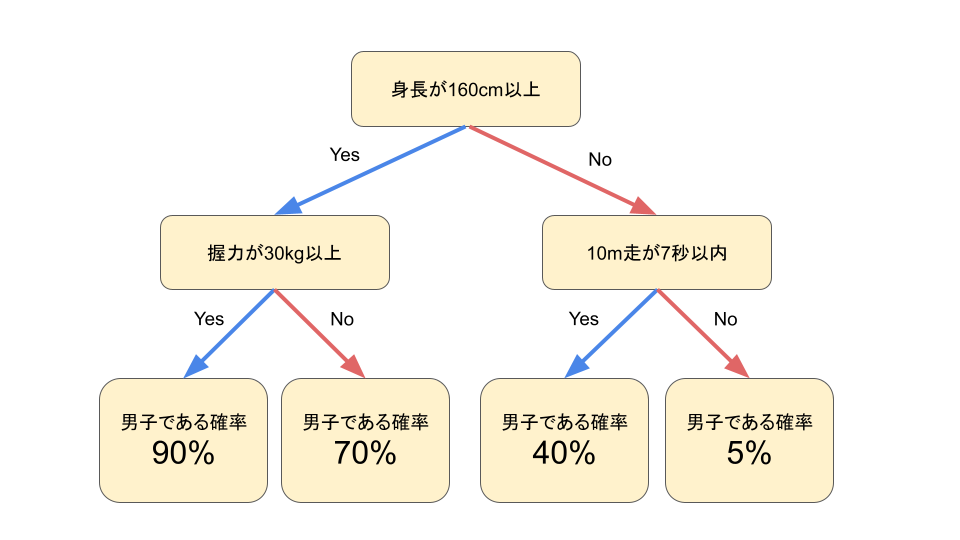
決定木(Decision Tree)は、データの特徴量に基づいて予測を行うアルゴリズムの一つで、分岐を繰り返すことで意思決定を行います。
決定木は分類と回帰という2つの用途があり、更に数多くの派生が存在していますが、本記事では分類と可視化を目的とした決定の使い方を解説します。
詳細については、NTTコム・オンラインの「決定木分析の事例を使ってメリットや活用場面を紹介」が参考になります。
決定木のメリット
現場での不安を解消するために、機械学習を活用したデータ分析が工場で使用される際、「中身が見えないから不安」という評価を受けることがあります。
決定木は、結果に至る過程がYES/NOの形式で図式化されるため、そのロジックが現場に理解されやすいというメリットがあります。
決定木には、分類精度を改良した派生版が数多く登場していますが、いずれも精度は向上するものの可視化ができません。
以上のことから、中身をブラックボックスとして割り切り、高い分類精度を得たい場合は派生版を用い、何らかの傾向や気づきを得たい場合は、今回紹介する決定木を使うという使い分けが一般的です。
決定木を行う場合のポイント(注意点)
決定木は決して万能というわけではありません。ここでは、決定木を使う上でのポイントを押さえておきましょう。
- 多重共線性
決定木はノードを分割する際に、そのノードで最も情報量が増加する特徴量を自動的に選択します。そのため、相関の高い特徴量同士が同時に選択されることは少なく、多重共線性の影響を受けにくい特徴があります。
とはいうものの、説明変数が完全に相関している場合などの極端な状況では、影響を受ける場合があります。
従って、相関が強い説明変数があれば、その中から1つに絞ることを心がけましょう。 - モデルの安定性
訓練データのわずかな変化で、モデルの構造が大きく変わってしまう場合があります。 - 不均衡データ
目的変数のデータが不均衡な場合(例えば目的変数Aが目的変数Bの数倍あるようなケース)は、正しい結果が得られません。できるだけ同じデータ量になるように多い方のデータを減らすか、少ない方のデータを水増しすることを検討しましょう。 - 過剰適合(Overfitting)
決定木は訓練データに過剰に適合する傾向があります。過剰適合を避けるために、木の深さを制限したり、最大葉ノード数を設定することが重要です。 - データの前処理
カテゴリカルデータを数値データに変換する必要があります。この記事では、LabelEncoderを使用してカテゴリカルデータをエンコードしています。データの欠損値についても適切な処理を行うことで、モデルの精度を向上させることができます。 - 可視化の工夫
決定木の構造を可視化することで、モデルの理解が深まります。特に日本語のデータを扱う際は、フォントの設定に注意が必要です。可視化の際に、日本語対応のフォントを指定することで、見やすいグラフを生成できます。
使い方
今回は、DecisionTreeというクラスを用意しました。指定したDataFrameと目的変数のカラム、説明変数のカラムリスト、出力結果の保存ファイル名を指定することで、描画した決定木を png 形式の画像として出力します。
下記は、使い方のサンプルです。
2行目には決定木に投入したいファイル名を、14行目には出力先のファイル名を指定してください。
dt = DecisionTree()
dt.read("P:\DataAnalysis\data\生産データ.csv")
# カテゴリを数値にエンコード(必要に応じて)
dt.category_encode(["ライン名称"])
# 欠損値のクレンジング(必要に応じて)
dt.cleansing(action="fb")
target = "不良内容" # 目的変数の列名
features = ["工場コード","ライン名称","ロットNo","薬液A温度","薬液B温度","薬液C温度","中経路温度","混合炉内温度","冷却炉内温度","出口温度"] # 説明変数のリスト
# 決定木の可視化
dt.visualize(target, features, "d:\decision_tree_output")
# カテゴリ変数の対応表を表示
print(dt.categorys)
プログラムを実行すると、下記の画像ファイルが保存されているはずです。
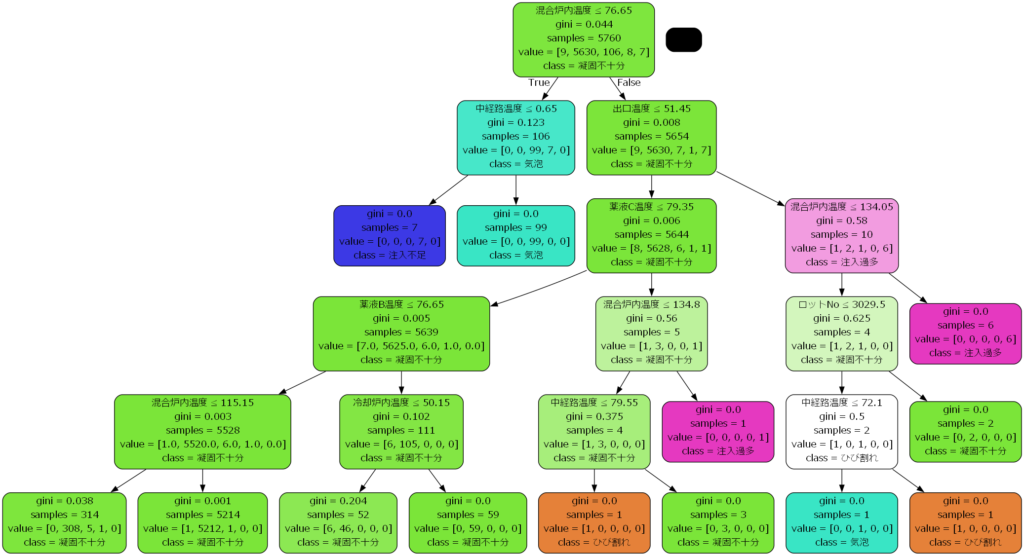
DecisionTree クラスのリファレンス
用意されているメソッドと引数の一覧を掲載しておきます。
| メソッド名 | 説明 | 引数 | 戻り値 |
|---|---|---|---|
| __init__ | クラスの初期化 | df: DataFrame (デフォルト: None) | なし |
| read | CSVファイルを読み込んでDataFrameに格納します。 | file_name:str, encoding:str (デフォルト: "shift-jis") | なし |
| cleansing | DataFrameの欠損値処理を行います。 | columns: list, action: str (デフォルト: 'fb') | pandas.DataFrame |
| visualize | 決定木を可視化し、PNGファイルとして保存します。 | target: str, features: list, file_name: str, max_depth: int (デフォルト: 5), random_state: int (デフォルト: 0), max_leaf_nodes: int (デフォルト: 100) | pydotplus.graphviz.Dot |
| category_encode | 指定したカラムを数値に変換します。 | columns: list | pandas.DataFrame |
DecisionTreeクラスのソースコード
事前準備
DecisionTreeクラスは、内部で Graphviz を呼び出しています。あらかじめ「【簡単便利】Graphvizの概要とPythonで使うためのインストール手順」に記載されている手順で、Graphviz をインストールしておいてください。
併せて、下記のライブラリもインストールしておく必要があります。
pip install pandas
pip install scikit-learn
pip install pydotplus
ソースコード
下記がソースコードです。ご自身のソースコードに張り付けるか、decision_tree.py というファイル名で保存してください。
# pip install pandas
# pip install scikit-learn
# pip install pydotplus
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import pydotplus
from sklearn.preprocessing import LabelEncoder
import pandas as pd
class DecisionTree:
def __init__(self,df=None):
"""
決定木を作成するクラス
Parameters:
df (pandas.DataFrame): 変換対象のDataFrame
"""
self.df = None if df is None else df.copy()
self.categorys = {}
def read(self,file_name,encoding="shift-jis"):
"""
CSVファイルをDataFrameに読み込む
Parameters:
file_name (str): CSVファイル名
encoding (str): エンコード名
"""
self.df = pd.read_csv(file_name,encoding=encoding) # データを読み込む
def cleansing(self, columns=None, action='fb'):
"""
DataFrameの欠損値処理を行うメソッド
Args:
columns (list, optional): 処理対象のカラムのリスト。Noneの場合、全カラムを対象とする。
action (str, optional): 処理内容を指定する文字列。
'f': 欠損値を前の行で埋める (ffill)
'b': 欠損値を後ろの行で埋める (bill)
'fb': 前後両方で埋める (ffill.bfill)
'd': 欠損値を含む行を削除する (dropna)
Returns:
pandas.DataFrame: 処理後のDataFrame
"""
# 処理対象のカラムを指定
if columns is None:
cols = self.df.columns
else:
cols = columns
# 処理内容に応じて処理を実行
if action == 'f':
self.df[cols] = self.df[cols].ffill()
elif action == 'b':
self.df[cols] = self.df[cols].bfill()
elif action == 'd':
self.df = self.df.dropna(subset=cols)
else:
self.df[cols] = self.df[cols].ffill().bfill()
return self.df
def visualize(self,target, features, file_name,max_depth=5,random_state=0,max_leaf_nodes=100):
"""
決定木を可視化してPNGファイルとして保存する関数
Parameters:
data (pd.DataFrame): 特徴量と目的変数を含むデータフレーム
target (str): 目的変数のカラム名
features (list of str): 特徴量として使用するカラム名のリスト
file_name (str): 保存するPNGファイルの名前(拡張子は含まない)
max_depth (int): 木の最大深さ
random_state (int): 乱数シード
max_leaf_nodes (int): 葉ノードの最大数
Returns:
pydotplus.graphviz.Dot: グラフオブジェクト
"""
# 特徴量と目的変数を分割
X = self.df[features]
y = self.df[target]
# 決定木クラス分類器のインスタンスを作成
clf = DecisionTreeClassifier(max_depth=max_depth,random_state=random_state,max_leaf_nodes=max_leaf_nodes)
# モデルの訓練
clf.fit(X, y)
# 決定木の可視化のためにDOTデータをエクスポート
dot_data = export_graphviz(clf, out_file=None,
feature_names=features,
class_names=sorted(y.unique()),
filled=True, rounded=True,
special_characters=True)
# 日本語のフォント名に置き換える
dot_data = dot_data.replace('fontname="helvetica"','fontname="Meiryo"')
# pydotplusを使用してDOTデータからグラフを生成
graph = pydotplus.graph_from_dot_data(dot_data)
# グラフをPNGファイルとして保存
graph.write_png(file_name + ".png")
# グラフを返す
return graph
def category_encode(self,columns):
"""
指定したカラムをLabelEncoderで数値に変換し、新しいDataFrameを返す関数
Args:
columns (list): 変換対象のカラム名のリスト
Returns:
pandas.DataFrame: 変換後のDataFrame
"""
for col in columns:
le = LabelEncoder()
self.df[col] = le.fit_transform(self.df[col])
self.categorys[col] = [x for x in le.classes_]
return self.df
まとめ
決定木は、その直感的で理解しやすいアルゴリズムとして、機械学習の入門者から現場のデータサイエンティストまで幅広く利用されています。
今回の記事では、Pythonを用いた決定木分析の基本的な実装方法を解説し、サンプルコードを通じて具体的なステップを示しました。
データの前処理や過剰適合の回避といったポイントに注意しながら、実際の業務データにも応用できる決定木を構築することができます。
また、決定木はその分かりやすさから、結果を現場に説明しやすいという利点がありますが、用途や目的に応じて派生アルゴリズムを使い分けることも大切です。
まずは今回のサンプルプログラムを実行し、決定木分析の基礎を押さえた上で、ご自身のプロジェクトで活用してみてください。データの持つ可能性を引き出し、意思決定を支援する強力なツールとして、決定木はあなたの課題解決に貢献してくれると思います。








コメント