
TF-IDF は、テキストデータにおける単語の重要度を数値化する手法として広く知られていますが、製造業のデータ分析においても、適切なデータと組み合わせることで、以下のような用途が考えられます。
TF-IDFとは
TF-IDF(Term Frequency - Inverse Document Frequency)は、文書中の単語の重要度を評価するための手法であり、自然言語処理や情報検索の分野でよく使われます。
TFは、特定の文書内で単語がどれだけ頻繁に出現するかを示します。登場頻度が多い単語は、その文書において重要であると解釈されます。
IDFは、複数の文書を比較した際に、どれだけ希少な単語かを示します。多くの文書に登場する単語は重要度が低く、逆に他の文書に含まれない単語は重要度が高い(希少価値がある)と解釈されます。
TF-IDFは、この2つの手法を掛け合わせて評価する手法であり、、「文書内での出現回数が多く(=TFの値が大きく)、他の文書であまり出てこない(=IDFの値が大きい)単語をリストアップし、これらを比較することで文書の類似性や特徴を見出すことができます。
製造業での用途
TF-IDFはテキストマイニングで使われる手法ではありますが、製造業でも文書はよく使われます。例えばメンテナンス記録や故障報告書などです。
また、TF-IDFは文書から単語を取り出しているため、単語のリストを渡すことでも分析できます。このことから、
例えば画面の操作ログや機械の稼働ログから画面名や稼働名を抜き出してTF-IDFを行うことで、画面操作や機械操作の人による違いや時間帯、設置場所による違いなども分析することも可能です。
- 画面の操作ログの分析
製造業では、オペレーターや技術者が使用するシステムの操作ログを収集することが一般的です。TF-IDFを用いることで、頻繁に行われる操作や重要な操作を特定し、操作手順の最適化やトレーニングの改善に役立てることができます。 - 機械の稼働ログの分析
機械の稼働ログを分析することで、稼働パターンや異常検知を行うことができます。TF-IDFを用いて、稼働ログから重要なイベントや異常なパターンを抽出し、予防保全や効率的な稼働計画の策定に役立てることができます - 品質管理
製造業では、品質管理のために多くのデータが収集されます。TF-IDFを用いることで、品質に関する報告書やクレームデータから重要なキーワードを抽出し、問題の根本原因を特定するのに役立ちます。 - メンテナンス予測
機械のメンテナンス記録や故障報告書を分析する際に、TF-IDFを使って頻繁に出現する問題や部品を特定できます。これにより、予防保全の計画を立てやすくなります。 - 顧客フィードバックの分析
顧客からのフィードバックやレビューを分析する際に、TF-IDFを用いて重要なキーワードを抽出し、製品の改善点や顧客のニーズを把握することができます。 - 文書の自動分類
製造業では多くの技術文書やマニュアルが存在します。TF-IDFを用いることで、これらの文書を自動的に分類し、必要な情報を迅速に検索できるようにすることができます。 - サプライチェーン管理
サプライチェーンに関する報告書やデータを分析する際に、TF-IDFを使って重要なトレンドや問題点を特定し、効率的なサプライチェーン管理を実現します。
インストール方法
Pythonで TF-IDF を行う場合、scikit-learn のインポートが必要です。また、TF-IDFが内部で使用するトークナイザー(MecabやJanomeなど)もインポートしなければなりません。
今回は、インストールが簡単な Janome をトークナイザーとして利用しますので、次の pip コマンドを実行します。
pip install scikit-learn
pip install janome
トークナイザー(tokenizer)は、自然言語処理(NLP)において、文章を単語や形態素などの基本的な単位であるトークンに分割するためのツールやプログラムの総称です。文書を形態素解析により分割し、数値化した後、モデルに入力できる形式に変換するという役割を持ちます。
TF-IDF の実行方法
下記は、TF-IDFのサンプルプログラムです。トークナイザーとしてjanome を使用するために、janome_tokenizer関数を定義し、 TfidfVectorizerの引数に渡しています。
docs に2つの文章を指定していますので、この2つの文書間で TF-IDF が行われます。
from sklearn.feature_extraction.text import TfidfVectorizer
from janome.tokenizer import Tokenizer
#TF-IDFを求めたい文書のリスト(実際には分かち書き文書又は単語の羅列)
docs = [
'左後方の深度センサーの接点不要により、後方バック時にポールに激突、バックライトが破損した',
'姿勢制御シリンダーの油圧調整不備により、斜面で車体が大きく傾き、横転した'
]
# TfidfVectorizer から呼び出されるトークナイザー。内部でJanome を使用。
def janome_tokenizer(text):
t = Tokenizer()
tokens = t.tokenize(text)
return [token.surface for token in tokens if token.part_of_speech.split(',')[0] in ['名詞', '動詞']]
# モデルの生成
vectorizer = TfidfVectorizer(tokenizer=janome_tokenizer)
# TF-IDFの計算
values = vectorizer.fit_transform(docs).toarray()
# 特徴量ラベルの取得
words = vectorizer.get_feature_names_out()
# 単語とTF-IDFの数値を1対のタプルにして、タプルのリストを作成
result = []
for doc_idx, doc in enumerate(values):
doc_result = [(words[word_idx], tfidf_value) for word_idx, tfidf_value in enumerate(doc) if tfidf_value > 0]
# 重要度順にソート
doc_result = sorted(doc_result, key=lambda x: x[1], reverse=True)
result.append(doc_result)
# 結果のプリント
for doc_result in result:
print(doc_result)実行結果は以下の通りです。2つの文書それぞれについて、TF-IDFの値が高いもの順に単語がリストアップされています。
[('バック', 0.46491210491127105), ('後方', 0.46491210491127105), ('センサー', 0.23245605245563553), ('ポール', 0.23245605245563553), ('ライト', 0.23245605245563553), ('不要', 0.23245605245563553), ('左', 0.23245605245563553), ('接点', 0.23245605245563553), ('時', 0.23245605245563553), ('深度', 0.23245605245563553), ('激突', 0.23245605245563553), ('破損', 0.23245605245563553), ('し', 0.16539439585841767)]
[('シリンダー', 0.30851498220914664), ('不備', 0.30851498220914664), ('傾き', 0.30851498220914664), ('制御', 0.30851498220914664), ('姿勢', 0.30851498220914664), ('斜面', 0.30851498220914664), ('横転', 0.30851498220914664), ('油圧', 0.30851498220914664), ('調整', 0.30851498220914664), ('車体', 0.30851498220914664), ('し', 0.21951095080860833)]
ワードクラウドによる可視化

TF-IDFの結果を可視化する方法として、ワードクラウドがあります。先ほどのプログラムの実行結果(result) を辞書に変換し、WordCloudの引数に渡せば、簡単にワードクラウドが描画できます。
但し、ワードクラウドは1文書づつ描画する必要がある点にご注意ください。下記のサンプルは、最初の文書についてのみワードクラウドで可視化しています。
ちなみに、ワードクラウドをそのまま利用すると文字化けを起こすので、WordCloudの font_path 引数に Windows標準のMeiryoフォントのパス(C:/Windows/Fonts/meiryo.ttc)を指定することで文字化けを回避しています。
from wordcloud import WordCloud
~省略(ここに先ほど紹介したサンプルプログラムを挿入してください。~
# 最初の文書の結果を取り出す
word_dic = dict(result[0])
# ワードクラウドを生成
wordcloud = WordCloud(width=800, height=400, background_color='black',font_path="C:/Windows/Fonts/meiryo.ttc").generate_from_frequencies(word_dic)
# ワードクラウドを表示
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()ヒートマップによる可視化
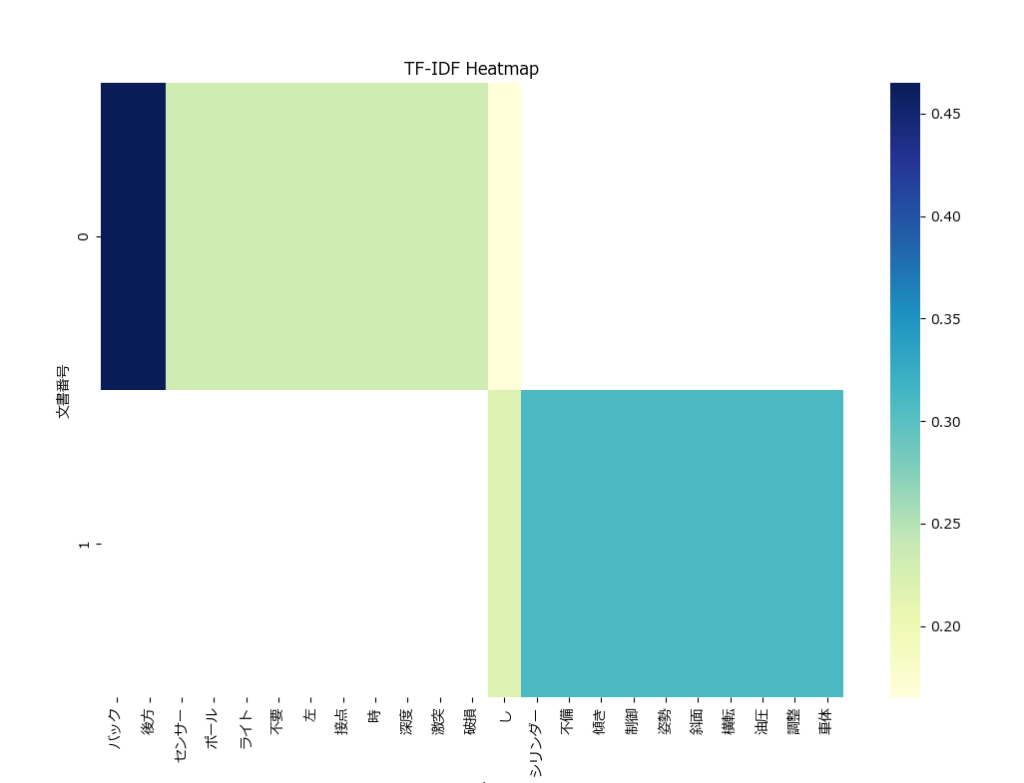
TF-IDFの結果を可視化する別の方法として、ヒートマップが利用できます。
こちらは1枚のヒートマップに複数の文書のTF-IDFの結果を表示できます。
先ほどのプログラムの実行結果(result) をDataFrameに変換し、seaborn を使ってヒートマップを作成しています。
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
rcParams['font.size'] = 10
import pandas as pd
import seaborn as sns
~省略(ここに先ほど紹介したサンプルプログラムを挿入してください。~
# データフレームに変換
df = pd.DataFrame([{word: score for word, score in doc} for doc in result])
# ヒートマップを作成
plt.figure(figsize=(12, 8))
sns.heatmap(df, cmap='YlGnBu', xticklabels=True, yticklabels=range(len(df)))
plt.title('TF-IDF Heatmap')
plt.xlabel('Words')
plt.ylabel('文書番号')
plt.show()TF-IDF分析結果の見方(評価ポイント)
TF-IDFの結果を見る時のポイントをまとめておきます。
- 相対的な重要度
TF-IDF値が高い単語は、その文書内で相対的に重要であることを示します。例えば、文書1では「バック」や「後方」が最も重要な単語であり、文書の内容が主に「バック」や「後方」に関連する問題に焦点を当てていることがわかります。 - 絶対的な重要度
全体的にTF-IDF値が低い場合、その文書自体が他の文書と比較してあまり特徴的でない可能性があります。この場合、トップの単語が重要であるとは限らないかもしれません。 - トップNの単語を抽出
各文書の最も重要な単語を簡単に特定するために、トップNの単語を抽出する方法も有効です。例えば、トップ3の単語を抽出することで、文書の主要なテーマやキーワードを素早く把握できます。
TF-IDFを手軽に実行できるTfIdfAnalyzerクラス
TF-IDFをもっと簡単に使えるようにするため、TfIdfAnalyzer クラスを作成しました。
下記は使い方のサンプルです。TF-IDFに渡す文章(docs)は、1文章が1要素となります。
analyzeメソッドを実行すると、janome を使ってdocs を形態素解析します。既に形態素解析済みのデータや、単語を羅列したデータでTF-IDFさせたい場合、analyzeの引数に use_tokenizer=False を指定してください。
from tfidf_analyzer import TfIdfAnalyzer
# 使用例
docs = [
'左後方の深度センサーの接点不要により、後方バック時にポールに激突、バックライトが破損した',
'姿勢制御シリンダーの油圧調整不備により、斜面で車体が大きく傾き、横転した'
]
# TfidfAnalyzerのインスタンスを作成
tf = TfIdfAnalyzer()
# 文書を分析し、結果をプリント
print(tf.analyze(docs))TfidfAnalyzerの load_documents メソッドを使うと、指定したファイルの内容でTF-IDFが行えますが、その際は改行までが1文書となります。
例えば、下記のテキストファイルを load_documents で読み込む場合、2つの文書として扱われます。1つの文書内に改行コードが含まれる場合は、文書内の末尾の改行コードを残し、残りの改行コードは削除してください。
今日は晴天だ。しかし風が強い。もしかすると犬の散歩ができないかもしれない。<改行>
さっき買ったノートPCを、さっそく自宅のWiFiにつなげてみた。思ったより簡単だった。<改行>
TfIdfAnalyzerには、以下のメソッドがあります。
| メソッド名 | 説明 | 引数 | 戻り値 |
|---|---|---|---|
| __init__ | インスタンスの 初期化 | file_name:str 読み込むファイルのパス。(省略時=None) encoding:str エンコーディング(省略時="shift-jis") tag_filter:list 抽出する品詞リスト(省略時=[‘名詞’, ‘動詞’]) | インスタンス |
| load_documents | 文書の読み込み | file_name:str 読み込むファイルのパス encoding:str エンコーディング(省略時="shift-jis") | なし |
| analyze | TF-IDFの実行 | docs:list 分析する文書のリスト use_tokenizer:bool トークナイザーの使用有無(省略時=True:使う) | [[(単語,TF-IDF値), ・・・・]] |
ソースコード
tfidf_analyzer.py というファイル名で、下記のソースコードを保存してください。
from janome.tokenizer import Tokenizer
from sklearn.feature_extraction.text import TfidfVectorizer
import os
# Janomeトークナイザー関数
class TfIdfAnalyzer:
def __init__(self, file_name=None, encoding="shift-jis", tag_filter=['名詞', '動詞']):
"""
コンストラクタ
:param file_name: 読み込むファイルのパス (str)
:param encoding: ファイルのエンコーディング (str)
:param tag_filter: 抽出する品詞のリスト (list)
"""
self.docs = [] # 文書のリストを格納するためのリスト
self.tag_filter = tag_filter # 品詞フィルター
self.values = [] # TF-IDF値を格納するリスト
self.words = [] # 特徴量ラベルを格納するリスト
# ファイル名が指定されていて、そのファイルが存在する場合、文書を読み込む
if file_name is not None and os.path.isfile(file_name):
self.load_documents(file_name, encoding)
def load_documents(self, file_name, encoding="shift-jis"):
"""
ファイルから文書を読み込む
:param file_name: 読み込むファイルのパス (str)
:param encoding: ファイルのエンコーディング (str)
"""
with open(file_name, encoding=encoding) as f:
lines = f.readlines()
self.docs = [x.strip() for x in lines]
def analyze(self, docs=[],use_tokenizer=True):
"""
文書のTF-IDF分析を行う
:param docs: 分析する文書のリスト (list)
:param use_tokenizer: 形態素解析を行うかどうか (bool)
:return: 各文書の単語とTF-IDF値のリスト (list)
"""
# janome用トークナイザー
def janome_tokenizer(text):
t = Tokenizer()
tokens = t.tokenize(text)
# 指定された品詞のみを抽出
return [token.surface for token in tokens if token.part_of_speech.split(',')[0] in self.tag_filter]
# TfidfVectorizerのインスタンスを作成
if use_tokenizer:
vectorizer = TfidfVectorizer(tokenizer=janome_tokenizer)
else:
vectorizer = TfidfVectorizer()
# 引数が無ければ、保持している文書を使う
if not docs:
docs = self.docs
# TF-IDF行列を作成
self.values = vectorizer.fit_transform(docs).toarray()
self.words = vectorizer.get_feature_names_out()
# 単語とTF-IDFの数値を1対のタプルにして、タプルのリストを作成
result = []
for doc in self.values:
doc_result = [(self.words[word_idx], tfidf_value) for word_idx, tfidf_value in enumerate(doc) if tfidf_value > 0]
# 重要度順にソート
doc_result = sorted(doc_result, key=lambda x: x[1], reverse=True)
result.append(doc_result)
return resultまとめ
今回は、Pythonで TF-IDF を行うための方法と、結果を評価する際のポイント、TF-IDFを簡単に利用するためのTfIdfAnalyzerクラスについて紹介しました。
TF-IDFはテキストマイニングでよく使われますが、製造業のデータ分析にも応用できます。作業日報や修理履歴などの文書はもとより、操作ログや稼働ログなどにも応用が可能です。
この記事を参考にして、製造系データ分析でも積極的にTF-IDFを使っていきましょう。








コメント