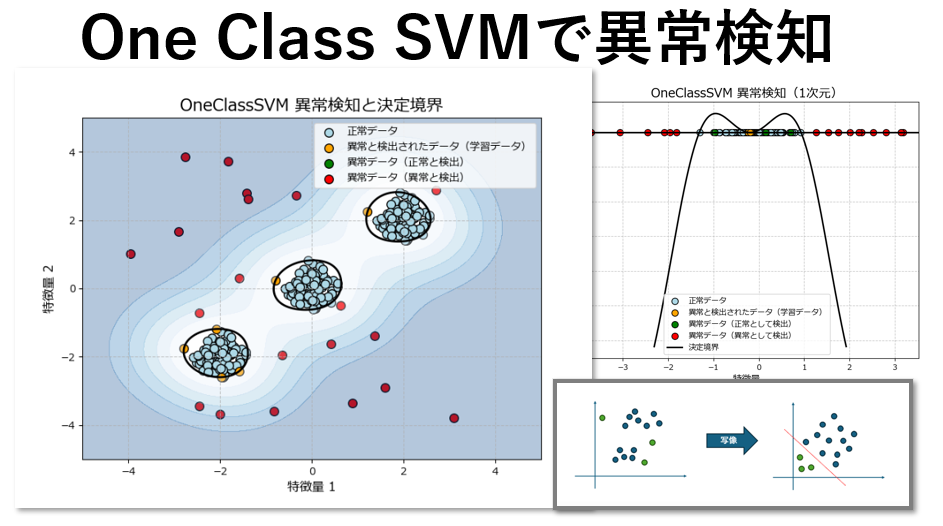
異常検知は、大量のデータの中から不正やエラー、異常な動作を迅速に検出する技術で、製造業も含めて幅広い分野で活用されています。
本記事でhあ、異常検知に特化した「OneClassSVM」というアルゴリズムに焦点を当て、その基本的な考え方や、Pythonでの実装方法を詳しく解説します。
OneClassSVMは、学習データが異常ではない正常データのみで構成されている状況でも高い精度を発揮し、未知の異常を効果的に検出します。
異常検知の導入を考えている方や、機械学習を使った高度な分析に挑戦したい方は、是非この記事を参考にしてください。
OneClassSVMとは
OneClassSVMは、主に異常検知に使用されるサポートベクターマシン(SVM)の一種です。通常、SVMはクラス分類を目的としたアルゴリズムですが、OneClassSVMは、正規のデータのみが与えられた環境で、未知の異常データを検出するために設計されています。
これにより、異常データのサンプルが少ない、または存在しない場合でも、学習した正常データから外れるパターンを異常と判断することができます。
OneClassSVMは、データの境界を学習し、その境界内に収まらないデータを異常とみなす非監督学習アルゴリズムです。したがって、異常ラベルが事前に付与されていないデータセットでも効果的に使用でき、さまざまな異常検知シナリオに適用されます。
OneClassSVMの原理
簡単に言うと、OneClassSVMはデータの分布を学習し、そこから外れたデータを異常と判断する教師なし学習のアルゴリズムです。そして、外れていることを判定するための方法として、SVMと高次元空間への写像(カーネルトリック)を行っています。
SVMを用いて、正常データを包含するような最小の超平面(境界線)を引き、さらにカーネルトリックによってデータを高次元空間に写像することで、異常データをより効果的に検出します。
高次元空間では、正常なデータは原点から遠くに、異常なデータは原点近くに配置される傾向があります。異常度の評価は、異常度スコアとして数値化され、境界からの距離や他のデータ点との密度など、複数の要素に基づいて計算されます。
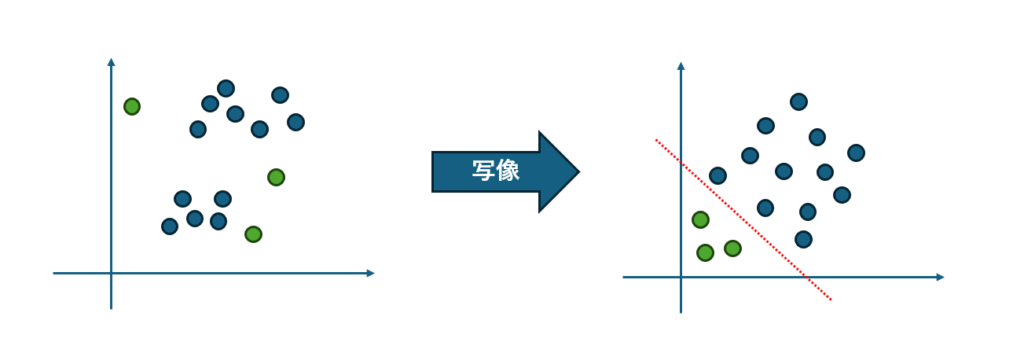
実際には、「境界からの距離」や「他のデータ点との密度」「異常度スコア」など、複数の要素が考慮されているのでもう少し複雑ですが、詳しい原理については、明治大学データ化学⼯学研究室が公開しているPDFが分かり易くまとまっています。
メリット
- 異常データのラベルが不要
OneClassSVMは、正常データのみでトレーニングができるため、異常データをラベル付けする必要がありません。これにより、異常データが少なく、ラベル付けが難しい場合でも有効です。 - 高次元データの処理能力
SVMは、カーネル関数を使って高次元空間にデータをマッピングし、複雑な非線形の境界を学習できます。これにより、複雑なパターンの異常も検出可能です。 - 汎用性が高い
製造業の異常検知やネットワークセキュリティなど、さまざまな分野で利用可能です。さまざまな種類のデータに適応できるため、異常検知タスクの多くに適しています。 - 少量の異常データに対応可能
OneClassSVMは、異常サンプルが少ない場合や極端に不均衡なデータセットでも正常サンプルからの乖離を検出できるため、異常なデータポイントが稀な場合にも有効です。
デメリット
- 大量の正常データが必要
正常な振る舞いをモデル化するために大量の正常データが必要です。正常データが少ない場合や、偏りがある場合は、モデルの精度が低下する可能性があります。 - 異常の多様性に弱い
異常データが多様な場合や、異常が正常と極端に似通っている場合、異常検出の性能が低下することがあります。異常が様々な種類のケースで発生する場合は、異常データにラベルを付ける他の手法の方が適しています。 - ハイパーパラメータ調整が難しい
OneClassSVMは、カーネル関数の選択やハイパーパラメータ(例:νパラメータ、カーネルのガンマ値)の設定に依存します。これらのパラメータを適切に調整しないと、過剰適合や過少適合につながり、異常検出の精度が下がる可能性があります。 - 計算コストが高い
データの量や次元が増えると、SVMの計算負荷が高くなることがあります。特に、カーネル関数を用いた場合は、データ量が多いとモデルのトレーニングや予測に時間がかかる場合があります。
OneClassSVM に適しているデータ
OneClassSVM は複雑な分布を持つデータに対して効果を発揮しますが、逆に単純な正規分布のデータや閾値で判定できるようなデータには適していません。また、異常データが多すぎるデータについても不得意です。
| 特徴 | OneClassSVMが適しているケース | OneClassSVMが不得意なケース |
|---|---|---|
| 正常データの定義 | 正常データと異常データの境界がはっきりしている | 異常データの定義が曖昧な場合 |
| 異常データの割合 | 異常データが少数派 | 異常データが多数派の場合 |
| 特徴量の形式 | データが数値で表現できる | 非数値データやテキストデータ |
| データの偏り | 学習データに偏りがない | 学習データに偏りがある場合 |
| 異常データの種類 | 異常データの種類が単一または限定的 | 異常データの種類が多様で、かつ、それぞれの異常パターンが異なる場合 |
| データのノイズ | ノイズが少なく、データがクリーンな場合 | ノイズが多く、データが汚染されている場合 |
OneClassSVMの製造業における用途
OneClassSVMは製造業において、設備の異常検知や品質管理に非常に有用なアルゴリズムです。以下に、具体的な用途をまとめます。
- 設備の故障予知
センサーデータを基に、機械や装置の異常を検知します。例えば、振動、温度、圧力などのデータを監視し、正常状態を学習することで、異常な挙動(故障の前兆や異常な振動など)を早期に発見できます。これにより、計画外のダウンタイムを防ぎ、メンテナンスコストの削減に寄与します。 - 生産品質の監視
製造工程で生成されるデータ(例:製品寸法、表面の仕上がり、成形時の温度や圧力)を監視し、通常の生産過程から逸脱するパターンを検出します。OneClassSVMを用いることで、正常な製品データを学習し、不良品や規格外品を検出することができます。これにより、製品の品質管理が強化され、廃棄率の低減や顧客満足度の向上につながります。 - 異常な作業工程の検出
製造ラインにおける異常な作業工程や動作を検出します。人間やロボットによる作業データを正常な範囲内で学習し、それに基づいて異常な作業や誤動作を特定することができます。これにより、作業効率を改善し、安全性を向上させることができます。 - 予防保全
製造機械やライン設備の予防保全にもOneClassSVMが利用されます。設備の通常動作時のデータを学習し、異常な状態(摩耗、損傷、劣化など)を検知することで、設備の予防的な保全作業が行えます。これにより、計画外の停止を回避し、保守作業の計画性を高めることができます。 - 在庫管理の異常検知
製造業における在庫データもOneClassSVMで監視することが可能です。在庫の異常な増減や不正な操作を検出することで、効率的な在庫管理や不正行為の早期発見に役立ちます。
OneClassSVMの実装方法
モジュールのインストール
OneClassSVMの実装には、Pythonの機械学習ライブラリ「scikit-learn」を使用します。また、結果を可視化するために 「matplotlib」 も必要です。まだインストールがお済みでない方は、下記のコマンドを実行してください。
pip install numpy pandas scikit-learn matplotlib
学習と異常検知
- このサンプルは、①学習データ生成⇒②学習⇒③テストデータ(異常データ)投入⇒④判定結果の出力という一連の処理を行っています。
- 実際のデータは正規分布ではないケースが多いため、学習データは3つの分布が混在するとともに、OneClassSVMには2次元以上のデータを渡す必要があるため、np.random.randn(100, 2) を使って2次元データを100個分作成しています。
- 異常検知したいデータが1次元の場合は、reshape(-1, 1) を使って2次元してからfit() の引数に指定してください。
- 後ほど紹介する自作クラスでは、1次元データをそのまま引数に指定できるよう考慮されています。
import numpy as np
import pandas as pd
from sklearn.svm import OneClassSVM
# 学習データ(100個の値を持つ2次元の正常データ)を生成
np.random.seed(42)
X_train = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X_train + 2, X_train - 2,X_train]
# OneClassSVM モデルの定義と学習(X_train は2次元以上のデータが必要)
model = OneClassSVM(nu=0.01, gamma='auto').fit(X_train)
# 出来上がったモデルに学習データを投入し、判定させてみる
y_pred_train = model.predict(X_train)
print("正常データの判定結果:",y_pred_train.tolist())
# テストデータを生成(異常と判定されるよう、振幅を-4~4で生成)
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# モデルに異常データを投入し、判定させてみる
y_pred_outliers = model.predict(X_outliers)
print("異常データの判定結果:",y_pred_outliers.tolist())実行結果は次の通りです。
OneClassSVMは正常データを1,異常データを-1 として判定結果を返します。
「正常データの判定結果」は学習を投入した時の結果、「異常データの判定結果」はテストデータを投入した時の結果です。
正常データだけを使って学習していますが、学習した分布が全ての正常データを網羅できないため、いくつかのデータは異常判定されています(ハイパーパラメータの調整が必要)。
正常データの判定結果: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, -1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, -1, 1, -1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, -1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, -1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, -1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
異常データの判定結果: [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
可視化
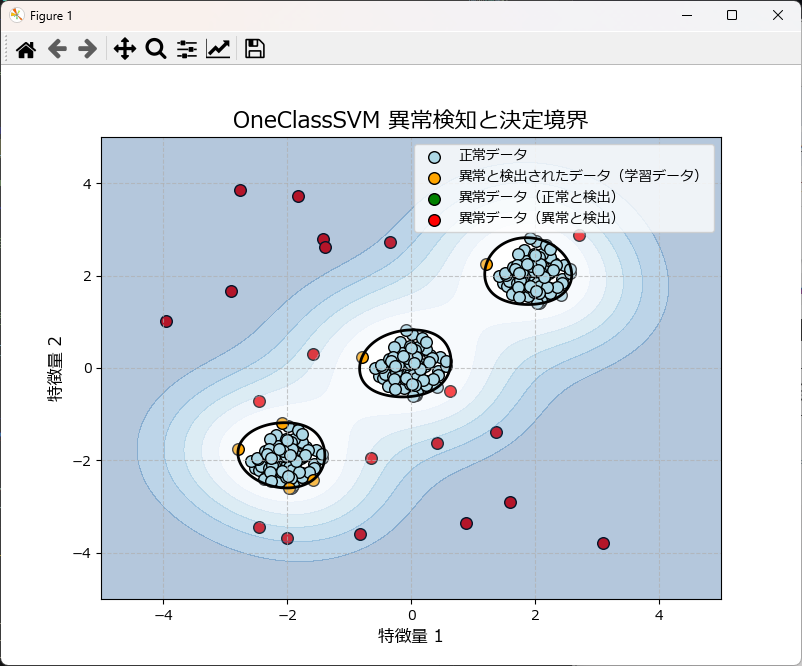
上記のグラフは、学習データと異常データを散布図としてプロットし、さらに異常スコアで境界線(等高線)を描画しています。
先ほどのプログラムの末尾に下記のコードを丸ごと挿入のうえ、実行して頂ければグラフが描画されます。関数化しているので、コピペしてお使いいただけます。
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
def plot_ocsvm_results(X_train, y_pred_train, X_test, y_pred_test, model):
"""
OneClassSVMモデルの異常検知結果を可視化します。
Args:
X_train (ndarray): 学習データの特徴量。
y_pred_train (ndarray): 学習データに対する予測ラベル (1: 正常, -1: 異常)。
X_test (ndarray): テストデータの特徴量。
y_pred_test (ndarray): テストデータに対する予測ラベル。
model (OneClassSVM): 学習済みのOneClassSVMモデル。
Returns:
None: グラフを表示します。
"""
# ======== グラフによる可視化 ========
plt.figure(figsize=(8, 6))
# 正常データの表示(分類結果ごとに色分け)
plt.scatter(X_train[y_pred_train == 1][:, 0], X_train[y_pred_train == 1][:, 1],
c='lightblue', edgecolors='k', s=70, label="正常データ")
plt.scatter(X_train[y_pred_train == -1][:, 0], X_train[y_pred_train == -1][:, 1],
c='orange', edgecolors='k', s=70, label="異常と検出されたデータ(学習データ)")
# 異常データの表示(分類結果ごとに色分け)
plt.scatter(X_test[y_pred_test == 1][:, 0], X_test[y_pred_test == 1][:, 1],
c='green', edgecolors='k', s=70, label="異常データ(正常と検出)")
plt.scatter(X_test[y_pred_test == -1][:, 0], X_test[y_pred_test == -1][:, 1],
c='red', edgecolors='k', s=70, label="異常データ(異常と検出)")
# 境界の等高線を描画するための範囲を設定
xx, yy = np.meshgrid(np.linspace(-5, 5, 500), np.linspace(-5, 5, 500))
# OneClassSVM モデルの決定関数の結果を計算
Z = model.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 境界の等高線を描画
plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='black')
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap=plt.cm.Blues_r, alpha=0.3)
# グラフの設定
plt.legend()
plt.title("OneClassSVM 異常検知と決定境界", fontsize=16)
plt.xlabel("特徴量 1", fontsize=12)
plt.ylabel("特徴量 2", fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
# 結果を表示
plt.show()
# ======== 可視化 ========
plot_ocsvm_results(X_train, y_pred_train, X_outliers, y_pred_outliers, model)ハイパーパラメータの調整
OneClassSVMには、いくつかの重要なハイパーパラメータがあり、パフォーマンスに大きな影響を与えます。特に、以下の2つのパラメータが重要です。
- nu
学習データの中で異常とみなされるデータの割合の上限を指定します。例えば0.1を指定すると、学習データの約10%が異常となる分布を学習します。
小さな値(0.01、0.001):異常と判断されるデータは少なくなりますが、逆に異常データを見逃す恐れがあります。
大きな値(0.1、0.2):異常の判定に寛容になりますが、正常データを異常として判定するリスクが増えます。 - gamma
カーネルの幅を調整するパラメータです。データの分布に応じてgammaを最適化することで、異常検知の精度を向上させることができます。
'scale:自動的にデータの標準偏差に基づいて値を設定します。
'auto':特徴量の数に基づいて自動的に値を設定します。通常は特徴量分の1になることが多いです。
小さな値(0.01、0.1):広い範囲をカバーし、一般的なパターンを捉えるのに適しています。
大きな値(1、10):局所的な変化を敏感に捉えますが、過剰な適合が生じる可能性があります。
ハイパーパラメータの調整には、クロスバリデーションを活用するのが効果的です。例えば、GridSerchCV を用いて最適なパラメータを探索できます。
from sklearn.model_selection import GridSearchCV
param_grid = {'nu': [0.1, 0.5, 0.9], 'gamma': ['scale', 'auto']}
grid_search = GridSearchCV(OneClassSVM(), param_grid, cv=5)
grid_search.fit(X_train)
print("Best parameters:", grid_search.best_params_)ハイパーパラメータを調整しても異常検知の精度が上がらない場合は、特徴量エンジニアリングを行います。
例えば、正規化や標準化、分布の調整、標準偏差や分散、移動平均などの演算、他の特徴量との相関係数の利用などが考えられます。
また、OneClassSVMに固執するのではなく、Isolation Forest、Local Outlier Factor (LOF)、AutoEncoderなど、別のアルゴリズムに切り替えることも検討すべきです。
OneClassSvmUtilが簡単に使える自作クラス
OneClassSVMを簡単に使えるようにするために自作クラスとグラフ描画関数を作成しました。
このクラスのfit() メソッドは、1次元データが渡された場合、内部でreshape(-1, 1)で2次元に拡張しているため、問題なく処理できます。
モデルを作成するには
OneClassSvmModelクラスのインスタンス生成時、引数にデータを格納したDataFrameを渡します。そして、fit メソッドにモデル作成で使いたいカラム名と、ハイパーパラメータを指定します。
read_csvメソッドを使うと、CSVファイルを読み込んでインスタンス変数(self.df)に保持します。
完成したモデルは save_model() メソッドで pickle ファイルとして保存できます。
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ここにOneClassSvmUtilとグラフ描画関数のコードを張り付けるか、インポートしてください
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# 学習データの生成
np.random.seed(42)
X_train_data = 0.5 * np.random.randn(100, 2)
X_train_data = np.r_[X_train_data + 1, X_train_data - 1, X_train_data]
df_train = pd.DataFrame(X_train_data, columns=['feature1', 'feature2'])
# インスタンスを生成
oc_svm = OneClassSvmUtil(df_train)
# モデルを学習
oc_svm.fit(['feature1', 'feature2'], nu=0.01)
# 学習データで異常検知を実施
y_pred_train = oc_svm.predict(['feature1', 'feature2'])
print("Train predictions:", y_pred_train)
# モデルの保存
oc_svm.save_model('one_class_svm_model.pkl')
# グラフ描画
plot_ocsvm_results(oc_svm.model,X_train=df_train[['feature1', 'feature2']].values, y_pred_train=y_pred_train)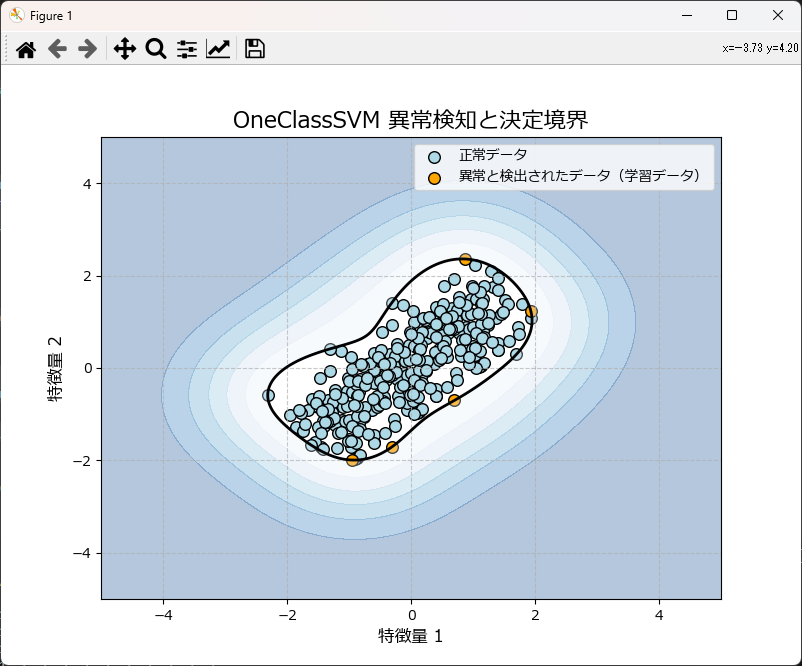
新しいデータで異常検知するには
OneClassSvmUtilのインスタンス生成時にモデルファイルのパスを指定します。
下記サンプルでは、カレントフォルダに保存されている'one_class_svm_model.pkl'を読み込んで、predict() メソッドで異常検知を行っています。
モデルをインスタンスの引数に指定する以外に、load_model()メソッドで読み込むことも可能です。
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ここにOneClassSvmUtilとグラフ描画関数のコードを張り付けるか、インポートしてください
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# テストデータの生成
np.random.seed(20)
X_test_data = np.random.uniform(low=-4, high=4, size=(20, 2))
df_test = pd.DataFrame(X_test_data, columns=['feature1', 'feature2'])
# インスタンスの生成とモデルの読み込み
oc_svm_new = OneClassSvmUtil(model_path='one_class_svm_model.pkl')
print("読み込んだモデル:", oc_svm_new.model)
# 新しいデータで異常検知を実施
y_pred_test = oc_svm_new.predict(['feature1', 'feature2'],df=df_test)
print("Test predictions:", y_pred_test)
# グラフ描画
plot_ocsvm_results(oc_svm_new.model,X_test=df_test[['feature1', 'feature2']].values, y_pred_test=y_pred_test)
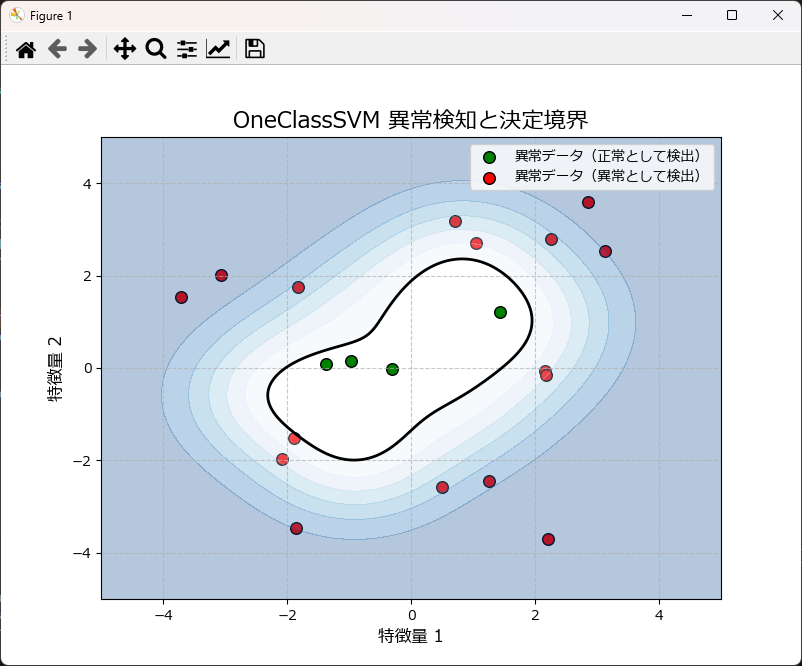
モデル作成時にテストデータによる評価を行うには
基本的には前述の処理を続けて行えばよいのですが、少しだけ処理を簡素化しています。
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ここにOneClassSvmUtilとグラフ描画関数のコードを張り付けるか、インポートしてください
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# 学習データの生成
np.random.seed(42)
X_train_data = 0.5 * np.random.randn(100, 2)
X_train_data = np.r_[X_train_data + 1, X_train_data - 1, X_train_data]
df_train = pd.DataFrame(X_train_data, columns=['feature1', 'feature2'])
# インスタンスを生成
oc_svm = OneClassSvmUtil(df_train)
# モデルを学習
oc_svm.fit(['feature1', 'feature2'], nu=0.01)
# 学習データで異常検知を実施
y_pred_train = oc_svm.predict(['feature1', 'feature2'])
print("Train predictions:", y_pred_train)
# テストデータを生成
np.random.seed(20)
X_test_data = np.random.uniform(low=-4, high=4, size=(20, 2))
df_test = pd.DataFrame(X_test_data, columns=['feature1', 'feature2'])
# テストデータで異常検知を実施
y_pred_test = oc_svm.predict(['feature1', 'feature2'],df=df_test)
print("Test predictions:", y_pred_test)
# 学習データとテストデータの検知結果を合わせてグラフ描画
plot_ocsvm_results(oc_svm.model,df_train[['feature1', 'feature2']].values, y_pred_train,df_test[['feature1', 'feature2']].values, y_pred_test)
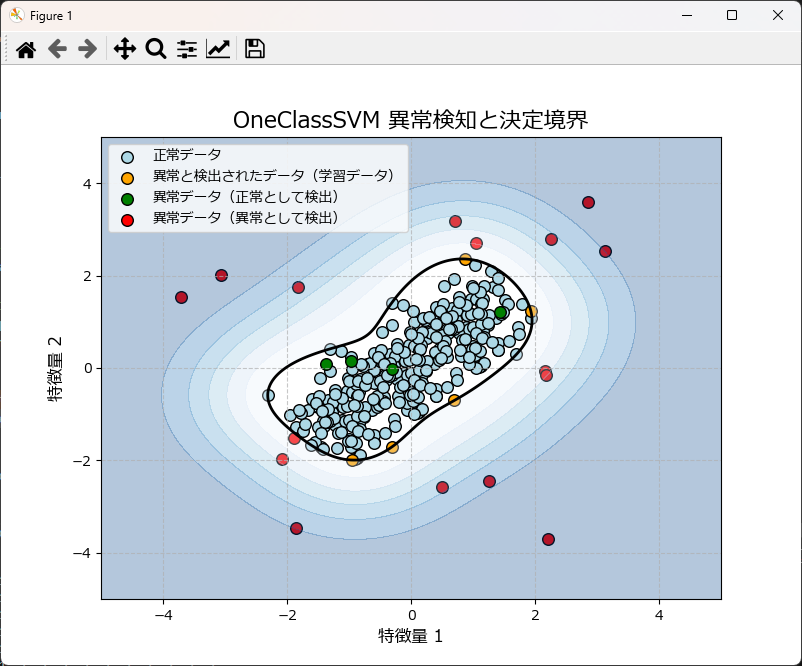
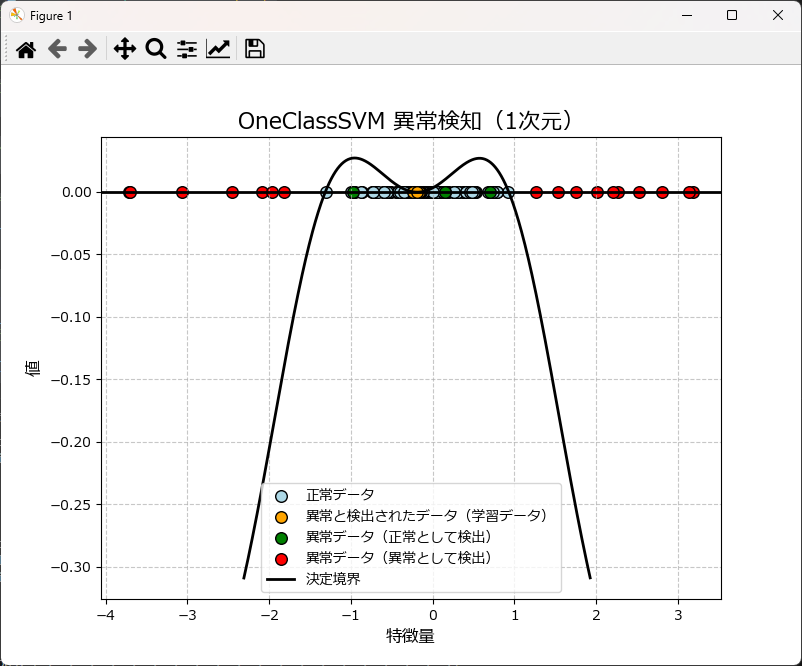
1次元の異常検知をするには
OneClassSvmModelクラスの使い方は前述と全く同じですが、グラフ描画は plot_ocsvm_results_1d を使用します。
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ここにOneClassSvmUtilとグラフ描画関数のコードを張り付けるか、インポートしてください
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# 学習データの生成
np.random.seed(42)
X_train_data = 0.5 * np.random.randn(100).reshape(-1, 1)
# 1次元データを2次元配列に変換
df_train = pd.DataFrame(X_train_data, columns=['feature1'])
# インスタンスを生成
oc_svm = OneClassSvmUtil(df_train)
# モデルを学習
oc_svm.fit(['feature1'], nu=0.01)
# 学習データで異常検知を実施
y_pred_train = oc_svm.predict(['feature1'])
print("Train predictions:", y_pred_train)
# テストデータを生成
np.random.seed(20)
X_test_data = np.random.uniform(low=-4, high=4, size=(20,)).reshape(-1, 1)
df_test = pd.DataFrame(X_test_data, columns=['feature1'])
# テストデータで異常検知を実施
y_pred_test = oc_svm.predict(['feature1'], df=df_test)
print("Test predictions:", y_pred_test)
# 1次元用の関数を使ってグラフ描画
plot_ocsvm_results_1d(
oc_svm.model, # 学習したモデルを直接使用
df_train[['feature1']].values,
y_pred_train,
df_test[['feature1']].values,
y_pred_test
)
グラフ描画関数のリファレンスとソースコード
| OneClassSvm用グラフ描画関数 | 説明 |
|---|---|
| plot_ocsvm_results_1d( model, X_train=None, y_pred_train=None, X_test=None, y_pred_test=None ) | 1次元データのOne-Class SVMの結果をプロットする。学習データとテストデータを表示し、決定境界を描画する。 |
| plot_ocsvm_results( model, X_train=None, y_pred_train=None, X_test=None, y_pred_test=None ) | 2次元データのOne-Class SVMの結果をプロットする。学習データとテストデータを表示し、決定境界を描画する。 |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
def plot_ocsvm_results_1d(model, X_train=None, y_pred_train=None, X_test=None, y_pred_test=None):
"""
1次元データのOne-Class SVMの結果をプロットする。
学習データとテストデータを表示し、正常データと異常と検出されたデータを色分けしてプロットする。
また、決定境界を描画する。
Parameters:
model : One-Class SVMモデル
学習済みのOne-Class SVMモデル。
X_train : array-like, shape (n_samples,), optional
学習データの特徴量。1次元データを想定。
y_pred_train : array-like, shape (n_samples,), optional
学習データに対する予測結果。1(正常)または-1(異常)。
X_test : array-like, shape (n_samples,), optional
テストデータの特徴量。1次元データを想定。
y_pred_test : array-like, shape (n_samples,), optional
テストデータに対する予測結果。1(正常)または-1(異常)。
"""
plt.figure(figsize=(8, 6))
# 学習データのプロット
if X_train is not None and y_pred_train is not None:
plt.scatter(X_train[y_pred_train == 1], np.zeros_like(X_train[y_pred_train == 1]),
c='lightblue', edgecolors='k', s=70, label="正常データ")
plt.scatter(X_train[y_pred_train == -1], np.zeros_like(X_train[y_pred_train == -1]),
c='orange', edgecolors='k', s=70, label="異常と検出されたデータ(学習データ)")
# テストデータのプロット
if X_test is not None and y_pred_test is not None:
plt.scatter(X_test[y_pred_test == 1], np.zeros_like(X_test[y_pred_test == 1]),
c='green', edgecolors='k', s=70, label="異常データ(正常として検出)")
plt.scatter(X_test[y_pred_test == -1], np.zeros_like(X_test[y_pred_test == -1]),
c='red', edgecolors='k', s=70, label="異常データ(異常として検出)")
# 決定境界の描画
if X_train is not None:
x_range = np.linspace(X_train.min() - 1, X_train.max() + 1, 500).reshape(-1, 1)
elif X_test is not None:
x_range = np.linspace(X_test.min() - 1, X_test.max() + 1, 500).reshape(-1, 1)
else:
# 両方のデータがない場合は固定範囲を使用(適宜調整)
x_range = np.linspace(-5, 5, 500).reshape(-1, 1)
Z = model.decision_function(x_range)
plt.plot(x_range, Z, color='black', linewidth=2, label='決定境界')
# グラフの設定
plt.axhline(0, color='black', linewidth=2)
plt.legend()
plt.title("One-Class SVM 異常検知(1次元)", fontsize=16)
plt.xlabel("特徴量", fontsize=12)
plt.ylabel("値", fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
# 結果を表示
plt.show()
def plot_ocsvm_results(model, X_train=None, y_pred_train=None, X_test=None, y_pred_test=None):
"""
2次元データのOne-Class SVMの結果をプロットする。
学習データとテストデータを表示し、正常データと異常と検出されたデータを色分けしてプロットする。
また、決定境界を描画する。
Parameters:
model : One-Class SVMモデル
学習済みのOne-Class SVMモデル。
X_train : array-like, shape (n_samples, 2), optional
学習データの特徴量。2次元データを想定。
y_pred_train : array-like, shape (n_samples,), optional
学習データに対する予測結果。1(正常)または-1(異常)。
X_test : array-like, shape (n_samples, 2), optional
テストデータの特徴量。2次元データを想定。
y_pred_test : array-like, shape (n_samples,), optional
テストデータに対する予測結果。1(正常)または-1(異常)。
"""
# 描画サイズの設定
plt.figure(figsize=(8, 6))
# 学習データのプロット(2次元データのみ)
if X_train is not None and y_pred_train is not None and X_train.ndim > 1:
plt.scatter(X_train[y_pred_train == 1][:, 0], X_train[y_pred_train == 1][:, 1],
c='lightblue', edgecolors='k', s=70, label="正常データ")
plt.scatter(X_train[y_pred_train == -1][:, 0], X_train[y_pred_train == -1][:, 1],
c='orange', edgecolors='k', s=70, label="異常と検出されたデータ(学習データ)")
# テストデータのプロット(2次元データのみ)
if X_test is not None and y_pred_test is not None and X_test.ndim > 1:
plt.scatter(X_test[y_pred_test == 1][:, 0], X_test[y_pred_test == 1][:, 1],
c='green', edgecolors='k', s=70, label="異常データ(正常として検出)")
plt.scatter(X_test[y_pred_test == -1][:, 0], X_test[y_pred_test == -1][:, 1],
c='red', edgecolors='k', s=70, label="異常データ(異常として検出)")
# 境界の等高線を描画するための範囲を設定
if X_train is not None and X_train.ndim > 1:
xx, yy = np.meshgrid(np.linspace(X_train[:, 0].min() - 1, X_train[:, 0].max() + 1, 500),
np.linspace(X_train[:, 1].min() - 1, X_train[:, 1].max() + 1, 500))
else:
# X_trainがない場合、テストデータの範囲を使用
if X_test is not None and X_test.ndim > 1:
xx, yy = np.meshgrid(np.linspace(X_test[:, 0].min() - 1, X_test[:, 0].max() + 1, 500),
np.linspace(X_test[:, 1].min() - 1, X_test[:, 1].max() + 1, 500))
else:
# X_trainとX_testがない場合は範囲を固定(適宜調整)
xx, yy = np.meshgrid(np.linspace(-5, 5, 500), np.linspace(-5, 5, 500))
x_range = np.c_[xx.ravel(), yy.ravel()]
# OneClassSVM モデルの決定関数の結果を計算
Z = model.decision_function(x_range)
Z = Z.reshape(xx.shape)
# 境界の等高線を描画
plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='black')
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap=plt.cm.Blues_r, alpha=0.3)
# グラフの設定
plt.legend()
plt.title("One-Class SVM 異常検知と決定境界", fontsize=16)
plt.xlabel("特徴量 1", fontsize=12)
plt.ylabel("特徴量 2", fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
# 結果を表示
plt.show()OneClassSvmUtilクラスのリファレンスとソースコード
| OneClassSvmUtilのメソッド | 説明 |
|---|---|
| __init__(df=None, model_path=None) | クラスの初期化メソッド。データフレームとモデルパスを受け取る。 |
| fit(column, nu=0.1, gamma="auto", kernel="rbf") | One-Class SVMモデルを作成・学習するメソッド。指定したカラムを使用。 |
| predict(column, df=None) | 学習したモデルを使用して予測を行うメソッド。指定したカラムを使用。 |
| read_csv(file_name, encoding="shift-jis") | CSVファイルからデータを読み込むメソッド。 |
| save_model(model_path) | 学習したモデルをファイルに保存するメソッド。 |
| load_model(model_path=None) | モデルをファイルから読み込むメソッド。 |
import numpy as np
import pandas as pd
from sklearn import svm
import pickle
from sklearn.model_selection import GridSearchCV
class OneClassSvmUtil:
def __init__(self, df=None,model_path=None):
"""
OneClassSvmクラスの初期化メソッド
:param df: 初期データフレーム (pd.DataFrame)
"""
self.df = None if df is None else df.copy() # データフレームのコピーを保持
self.model = None if model_path is None else self.load_model(model_path) # SVMモデルファイルのパス
self.pred = [] # 予測結果のリスト
def fit(self, column, nu=0.1, gamma="auto",kernel="rbf"):
"""
One-Class SVMモデルの作成と学習
:param column: 学習に使用するカラム名 (str または list)
:param nu: SVMのnuパラメータ (float)
:param gamma: SVMのgammaパラメータ (str または float)
:param kernel: 使用するカーネルの種類 (str)
- 'linear': 線形カーネル
- 'poly': 多項式カーネル
- 'rbf': RBFカーネル(ガウシアンカーネル⇒デフォルト)
- 'sigmoid': シグモイドカーネル
:return: 学習したモデル
"""
# 指定されたカラムのデータを抽出
if isinstance(column, list) and len(column) > 1:
X = self.df[column].values
else:
X = self.df[column].values.reshape(-1, 1) # 複数カラムのデータを2次元配列に変換
# One-Class SVMモデルの作成
self.model = svm.OneClassSVM(nu=nu, gamma=gamma,kernel=kernel).fit(X)
return self.model
def predict(self, column,df=None):
"""
学習したモデルを使用して予測を行う
:param column: 学習に使用するカラム名 (str または list)
:return: 予測結果の配列
"""
# df がNoneでなければ、インスタンス変数に代入
if df is not None:
self.df = df
# 指定されたカラムのデータを抽出
if isinstance(column, list) and len(column) > 1:
X = self.df[column].values
else:
X = self.df[column].values.reshape(-1, 1) # 複数カラムのデータを2次元配列に変換
# 予測する
self.pred = self.model.predict(X)
return self.pred
def read_csv(self, file_name, encoding="shift-jis"):
"""
CSVファイルからデータを読み込むメソッド
:param file_name: 読み込むファイルのパス (str)
:param encoding: ファイルのエンコーディング (str)
"""
self.df = pd.read_csv(file_name, encoding=encoding) # データフレームに読み込み
def save_model(self, model_path):
"""
学習したモデルをファイルに保存するメソッド
:param model_path: 保存するファイルのパス (str)
"""
self.model_path = model_path
with open(model_path, 'wb') as f:
pickle.dump(self.model, f) # モデルをバイナリ形式で保存
def load_model(self, model_path=None):
"""
モデルをファイルから読み込むメソッド
:param model_path: 読み込むファイルのパス (str)
:return: 読み込んだモデル
"""
if model_path is None:
model_path = self.model_path
with open(model_path, 'rb') as f:
self.model = pickle.load(f) # モデルをバイナリ形式で読み込み
return self.modelまとめ
OneClassSVMは、異常データが少ない、または存在しない状況でも正常データのみを使用して異常検知を実現する強力なアルゴリズムです。
Pythonでの実装も比較的簡単であり、ハイパーパラメータの調整によって、さまざまなシナリオに最適化できます。
製造業から金融、ITセキュリティまで、幅広い分野で異常検知の需要が高まる中、OneClassSVMはその一助となるでしょう。








コメント