
機械学習のモデル開発では、ランダムフォレストやLightGBMといったアルゴリズムを使い分けることが一般的です。しかし、その都度コードを一から書き直すのは非効率で、作業の重複が発生しがちです。
そこで活用したいのが、複数のアルゴリズムに対応した汎用クラスの作成です。このクラスを使えば、モデルの学習や予測、ハイパーパラメータ調整を統一した方法で実行でき、コーディング効率を大幅に向上させることが可能になります。
本記事では、このような汎用クラスの設計方法と活用例を詳しく解説します。
目的
scikit-learn(sklearn)は、アンサンブル技法など多くのアルゴリズム(モデル作成手法)を提供しており、それらの使い方(呼び出し方)はほとんど統一されています。
そこで、モデル作成や予測、グラフ作成といった共通処理をクラス化し、使用するアルゴリズムを切り替えるだけで、さまざまな手法で分類や予測が行える仕組みを作成しました。
このクラスを使うと、分類や回帰分析において、複数のアルゴリズムの中から最も精度の良いモデルおよびハイパーパラメータを簡単に選定できます。
汎用クラスの設計コンセプト
CSVやDataFrameに格納されているデータに対して、簡単な操作で分類/回帰のモデルを作成/評価でき、様々なアルゴリズムを簡単に試せる(切り替えられる)ことをコンセプトとしました。
現時点で実装している機能は次の通りです。
- 分類モデルと回帰モデルの作成と予測
- よく使うアルゴリズムに対応(RandomForest、LightGBM、XGBoost、CatBoost、GBDT、AdaBoost)
- グリッドサーチによるハイパーパラメータの検索機能
- 一般的に使われる一通りの精度指標の出力
- モデルを評価するために有用なグラフの出力(画面表示/ファイル保存)
クラス構成
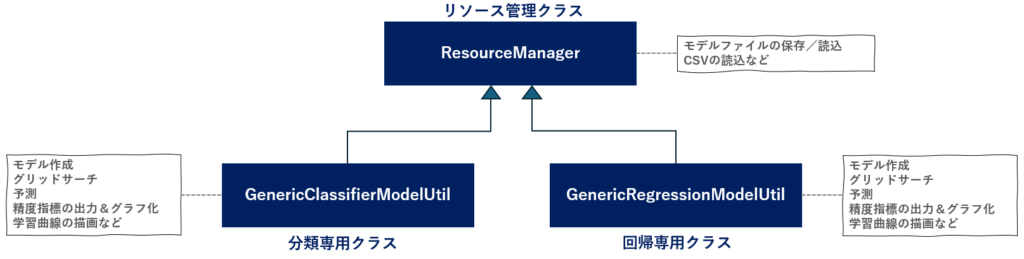
モデルファイルやCSVファイルなどのリソースファイルを取り扱う ResourceManager クラスと、それを継承して実際のモデルを作成したり、精度評価や可視化を行うGenericClassifierModelUtil と GenericRegressionModelUtil クラスで構成しています。
今後データベースとのやり取りやJson や XML 形式のデータに対応させたい場合はResourceManager へ、新しいハイパーパラメータ検索アルゴリズムの実装やグラフの追加を行いたい場合は GenericClassifierModelUtil 、GenericRegressionModelUtil に手を加えるという具合に切り分けが容易になるため、メンテナンス性が向上します。
自作クラスの使い方
ライブラリのインストール
下記のライブラリが必要になりますので、事前にインストールしてください。
pip install numpy
pip install matplotlib
pip install seaborn
pip install pandas
pip install dask[dataframe]
pip install scikit-learn
pip install xgboost
pip install lightgbm
pip install catboost
学習の仕方とモデルの保存
分類、回帰とも以下の手順で学習が可能です。
- 使いたいアルゴリズムとDataFrameを引数に指定し、自作クラスのインスタンスを生成
read_csvメソッドにより教師データを読込むfitメソッドにより学習を実行evaluateメソッドにより精度指標を出力
分類と回帰それぞれに専用クラスを用意しています。
分類用クラス: GenericClassifierModelUtil(アルゴリズム,DataFrame)
回帰用クラス: GenericRegressionModelUtil(アルゴリズム,DataFrame)
下記は分類モデルの簡単な作成例です。GenericClassifierModelUtil()をGenericRegressionModelUtil()に変更すれば、回帰モデルが作成できます。
# アルゴリズムのインポート
from sklearn.ensemble import RandomForestClassifier
# インスタンスの生成
util = GenericClassifierModelUtil(RandomForestClassifier)
# データの読み込み
util.read_csv('nonlinear_classification_data.csv',encoding="utf-8")
# 学習の実行
util.fit(target='正解データ', columns=None,track_learning_curve=True)
# 精度指標の表示
util.evaluate()
# モデルをファイルに保存
util.save_model("./mymodel.pkl")正解率: 0.925
混同行列:
[[44 1 1 5]
[ 0 46 0 0]
[ 0 0 51 2]
[ 0 3 3 44]]
分類レポート:
precision recall f1-score support
0 1.00 0.86 0.93 51
1 0.92 1.00 0.96 46
2 0.93 0.96 0.94 53
3 0.86 0.88 0.87 50
accuracy 0.93 200
macro avg 0.93 0.93 0.93 200
weighted avg 0.93 0.93 0.92 200
アルゴリズムの切り替え方法
分類の場合、使いたいアルゴリズムをインポートして、GenericClassifierModelUtilの第一引数に指定します。
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import AdaBoostClassifier
from lightgbm import LGBMClassifier
from xgboost import XGBClassifier
from catboost import CatBoostClassifier
# インスタンスの生成例
util = GenericClassifierModelUtil(RandomForestClassifier)回帰の場合、アルゴリズムをGenericRegressionModelUtilの第一引数に指定してください。
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import AdaBoostRegressor
from lightgbm import LGBMRegressor
from xgboost import XGBRegressor
from catboost import CatBoostRegressor
# インスタンスの生成例
util = GenericRegressionModelUtil(RandomForestRegressor)モデルの読込と予測の実行
以下の手順でモデルファイルを読み込み、新しいデータで予測することが可能です。
- 教師データを読込む
- 使いたいアルゴリズムとDataFrameを引数に指定し、自作クラスのインスタンスを生成
fitメソッドにより学習を実行evaluateメソッドにより精度指標を出力
# アルゴリズムのインポート
from sklearn.ensemble import RandomForestClassifier
# インスタンスの生成(モデルファイルを指定)
util = GenericClassifierModelUtil(RandomForestClassifier,model_path="./mymodel.pkl")
# データの読み込み
util.read_csv('nonlinear_classification_data.csv',encoding="utf-8")
# 予測に使うカラムのみ取り出し
columns = [x for x in util.columns if x != '正解データ']
# 予測の実行
res = util.predict(columns=columns)
print(res)[2 2 1 1 3 0 0 1 1 3 1 1 2 0 1 1 1 0 3 1 3 3 1 3 1 0 2 1 1 1 1 0 2 3 3 3 1
0 2 1 3 1 3 2 3 0 3 2 0 3 0 3 2 1 1 3 3 1 2 0 1 2 0 3 3 0 1 3 2 3 1 2 1 0
3 0 1 1 0 0 0 2 2 3 0 3 3 1 2 3 0 2 2 0 2 2 1 1 2 1 0 1 0 2 0 0 0 0 0 1 0
~省略~
モデルのパスを読み込む方法としてコンストラクタにパスを指定しましたが、コンストラクタでパスを省略し、load_modelメソッドを使うことも可能です。
グリッドサーチを使ったモデルの作成
fit_with_grid_search()メソッドにパラメータのサーチ範囲を指定することで、グリッドサーチが行えます。
この時、columnsに None を指定すると、 read_csv で読み込んだDataFrameの全カラムが使われますが、targetで指定したカラムは自動的に除外されます。
# アルゴリズムのインポート
from sklearn.ensemble import RandomForestClassifier
# インスタンスの生成
util = GenericClassifierModelUtil(RandomForestClassifier)
# データの読み込み
util.read_csv('nonlinear_classification_data.csv',encoding="utf-8")
# パラメータのサーチ範囲の指定
param_grid = {
'n_estimators': [100, 200, 500], # 決定木の数
'max_depth': [10, 20, 30, None], # 決定木の最大深さ
'min_samples_split': [2, 5, 10], # 内部ノードを分割するために必要な最小サンプル数
'min_samples_leaf': [1, 2, 4], # 葉ノードに必要な最小サンプル数
'bootstrap': [True, False] # ブートストラップサンプリングの使用
}
# 学習の実行
util.fit_with_grid_search(target='正解データ', columns=None, param_grid=param_grid)
# 精度指標の表示
util.evaluate()最適なハイパーパラメータ: {'bootstrap': True, 'max_depth': 20, 'min_samples_leaf': 1, 'min_samples_split': 5, 'n_estimators': 100}
グリッドサーチの最適なスコア: 0.86875
正解率: 0.92
混同行列:
[[44 1 1 5]
[ 0 46 0 0]
[ 2 0 49 2]
[ 0 3 2 45]]
分類レポート:
precision recall f1-score support
0 0.96 0.86 0.91 51
1 0.92 1.00 0.96 46
2 0.94 0.92 0.93 53
3 0.87 0.90 0.88 50
accuracy 0.92 200
macro avg 0.92 0.92 0.92 200
weighted avg 0.92 0.92 0.92 200
fit()と fit_with_grid_search()は共にインスタンス内部の変数に必要な情報(カラムのリスト、出来上がったモデルなど)を保存します。fit() を実行後、fit_with_grid_search() を実行(またその逆の場合も)すると上書きされるためご注意ください。
学習曲線の描画
fit() の track_learning_curve引数に True を指定すると、 util.plot_learning_curve()にて学習曲線が描画できます。file_name引数にファイルのパスを指定すると、グラフは表示せずファイルに保存します。
# アルゴリズムのインポート
from sklearn.ensemble import RandomForestClassifier
# インスタンスの生成
util = GenericClassifierModelUtil(RandomForestClassifier)
# データの読み込み
util.read_csv('nonlinear_classification_data.csv',encoding="utf-8")
# 学習の実行
util.fit(target='正解データ', columns=None,track_learning_curve=True)
# 学習曲線の描画
util.plot_learning_curve()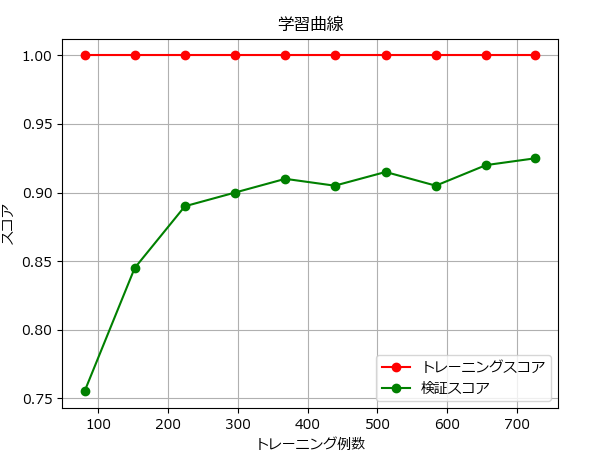
その他のグラフの描画
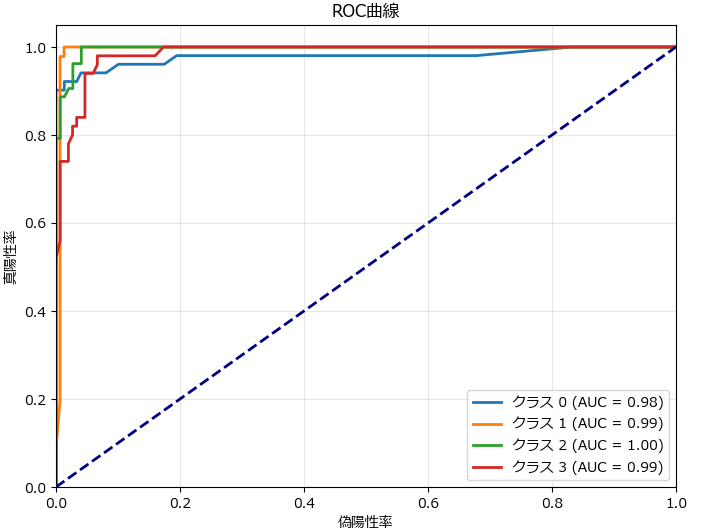
分類モデルでは、plot_confusion_matrix() で混同行列、plot_roc_curve()でROC曲線が描画できます。file_name引数にファイルのパスを指定すると、グラフは表示せずファイルに保存します。
# アルゴリズムのインポート
from sklearn.ensemble import RandomForestClassifier
# インスタンスの生成
util = GenericClassifierModelUtil(RandomForestClassifier)
# データの読み込み
util.read_csv('nonlinear_classification_data.csv',encoding="utf-8")
# 学習の実行
util.fit(target='正解データ', columns=None,track_learning_curve=True)
# 混同行列の描画
util.plot_confusion_matrix()
# 学習曲線の描画
util.plot_roc_curve()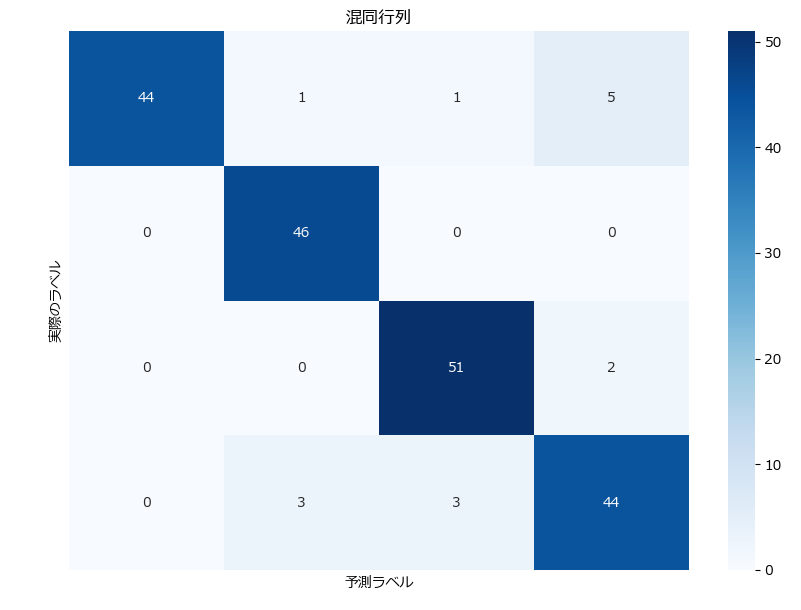
回帰モデルでは、plot_diagnostics() で4種類のグラフ(予実の折れ線、散布図、回帰曲線、残渣プロットを)描画します。file_name引数にファイルのパスを指定すると、グラフは表示せずファイルに保存します。
# 使用例
from sklearn.ensemble import RandomForestRegressor
# インスタンスの生成
util = GenericRegressionModelUtil(RandomForestRegressor)
# データの読み込み
util.read_csv('nonlinear_classification_data.csv',encoding='utf-8')
# 学習の実行
util.fit(target='特徴量_1', columns=util.columns)
# 予実の折れ線、散布図、回帰曲線、残渣プロットを描画
util.plot_diagnostics()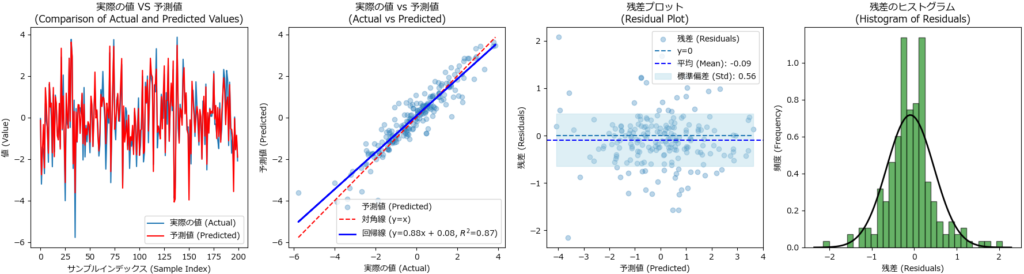
# 使用例
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import AdaBoostRegressor
from lightgbm import LGBMRegressor
from xgboost import XGBRegressor
from catboost import CatBoostRegressor
# 分類問題用テストデータの読み込み
df = pd.read_csv('nonlinear_regression_data.csv')
param_grid = {
'n_estimators': [100, 200],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5],
'min_samples_leaf': [1, 2]
}
rf_util = GenericRegressionModelUtil(GradientBoostingRegressor,df)
rf_util.fit(target='特徴量_1', columns=df.columns,track_learning_curve=True)
#rf_util.fit_with_grid_search(target='特徴量_1', columns=df.columns, param_grid=param_grid)
rf_util.evaluate()
rf_util.plot_learning_curve()
rf_util.plot_diagnostics()ソースコード
データ/モデル管理用の共通クラス(ResourceManager)
import pandas as pd
import pickle
class ResourceManager:
def __init__(self, df=None, model_path=None):
"""
クラスの初期化メソッド
:param df: 初期データフレーム (pd.DataFrame)
:param model_path: モデルファイルのパス (str)
"""
self.df = None if df is None else df.copy() # データフレームのコピーを保持
self.model = None if model_path is None else self.load_model(model_path) # モデルファイルのパス
self.columns = []
def read_csv(self, file_name, encoding="shift-jis"):
"""
CSVファイルからデータを読み込むメソッド。読み込むと columnsプロパティにカラムがセットされる。
:param file_name: 読み込むファイルのパス (str)
:param encoding: ファイルのエンコーディング (str)
:return: DataFrame, 読み込んだDataFrame
"""
self.df = pd.read_csv(file_name, encoding=encoding) # データフレームに読み込み
self.columns = self.df.columns
return self.df
def save_model(self, model_path):
"""
学習したモデルをファイルに保存するメソッド
:param model_path: 保存するファイルのパス (str)
"""
with open(model_path, 'wb') as f:
pickle.dump(self.model, f) # モデルをバイナリ形式で保存
def load_model(self, model_path=None):
"""
モデルをファイルから読み込むメソッド
:param model_path: 読み込むファイルのパス (str)
:return: 読み込んだモデル
"""
if model_path is None:
model_path = self.model_path
with open(model_path, 'rb') as f:
self.model = pickle.load(f) # モデルをバイナリ形式で読み込み
return self.model分類モデル作成/予測用クラス(GenericClassifierModelUtil)
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.metrics import roc_curve, auc,accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
class GenericClassifierModelUtil(ResourceManager):
def __init__(self, mode_cls,df=None, model_path=None):
"""
クラスの初期化メソッド
:param model_cls:分類で使うモデルのクラス
:param df: 初期データフレーム (pd.DataFrame)
:param model_path: モデルファイルのパス (str)
"""
super().__init__(df, model_path)
self.model_cls = mode_cls
self.X_train = []
self.X_test = []
self.y_train = []
self.y_test = []
self.y_pred = []
self.params = {}
self.history = []
def fit(self, target, columns=None, params={}, test_size=0.2, random_state=42, track_learning_curve=False, split_method='split'):
"""
モデルを学習し、レポートを出力するメソッド
:param target: str, 予測対象となるターゲット列名
:param columns: list of str, 使用する特徴量の列名のリスト。ターゲットが含まれていても無視する。省略時は self.columnsが使われる。
:param params: dict, optional (default={}), ランダムフォレストのハイパーパラメータ
:param test_size: float, optional (default=0.2), テストデータの割合
:param random_state: int, optional (default=42), 乱数シード
:param track_learning_curve: bool, optional (default=False), 学習曲線の履歴を取るかどうか
:param split_method: str, optional (default='split'), データ分割方法 ('split' または 'cross_val')
"""
if columns is not None:
self.columns = columns
X = self.df[[col for col in self.columns if col != target]]
y = self.df[target]
self.params = params
self.track_learning_curve = track_learning_curve
self.split_method = split_method
if split_method == 'split':
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
elif split_method == 'cross_val':
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
self.cross_val_scores = cross_val_score(self.model_cls(**params, random_state=random_state), X, y, cv=5)
self.model = self.model_cls(random_state=random_state, **params)
if track_learning_curve:
# 学習履歴を保存するリスト
self.history = {'train_sizes': [], 'train_scores': [], 'val_scores': []}
# 異なるサイズのトレーニングセットでモデルを再学習
train_sizes = np.linspace(0.1, 1.0, 10, endpoint=False) # 1.0 未満の最大値
for train_size in train_sizes:
X_train_sub, _, y_train_sub, _ = train_test_split(self.X_train, self.y_train, train_size=train_size, random_state=random_state)
self.model.fit(X_train_sub, y_train_sub)
# トレーニングスコアと検証スコアを計算
train_score = accuracy_score(y_train_sub, self.model.predict(X_train_sub))
val_score = accuracy_score(self.y_test, self.model.predict(self.X_test))
# スコアを保存
self.history['train_sizes'].append(len(X_train_sub))
self.history['train_scores'].append(train_score)
self.history['val_scores'].append(val_score)
else:
# モデルをトレーニング
self.model.fit(self.X_train, self.y_train)
self.y_pred = self.model.predict(self.X_test)
return self.model
def predict(self, columns = None, df = None):
"""
学習済みモデルを用いて予測を行うメソッド
:param columns: list, 予測に使うカラム名のリスト。省略すると self.columns の全てのカラムが使われる。
:param df: pd.DataFrame, 予測対象の特徴量データフレーム
:return: np.ndarray, 予測結果
"""
columns = self.columns if columns is None else columns
X = self.df[columns] if df is None else df
return self.model.predict(X)
def fit_with_grid_search(self, target, columns, param_grid, test_size=0.2, random_state=42):
"""
グリッドサーチを使用してハイパーパラメータをチューニングし、最適なモデルを見つけるメソッド。
:param target: str, 予測対象となるターゲット列名
:param columns: list of str, 使用する特徴量の列名のリスト。ターゲットが含まれていても無視する。None指定時は self.columnsが使われる。
:param param_grid: dict, グリッドサーチで試すハイパーパラメータの辞書
:param test_size: float, optional (default=0.2), テストデータの割合
:param random_state: int, optional (default=42), 乱数シード
"""
if columns is not None:
self.columns = columns
X = self.df[[col for col in self.columns if col != target]]
y = self.df[target]
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
self.model = self.model_cls(random_state=random_state)
grid_search = GridSearchCV(estimator=self.model, param_grid=param_grid, cv=5, scoring='accuracy', n_jobs=-1)
grid_search.fit(self.X_train, self.y_train)
self.model = grid_search.best_estimator_
self.params = grid_search.best_params_
best_score = grid_search.best_score_
self.y_pred = self.model.predict(self.X_test)
print(f'最適なハイパーパラメータ: {self.params}')
print(f'グリッドサーチの最適なスコア: {best_score}')
return self.model
def evaluate(self):
"""
分類モデルの評価指標を計算して出力するメソッド
:param y_test: np.ndarray, テストデータの真のラベル
:param y_pred: np.ndarray, 予測結果のラベル
"""
accuracy = accuracy_score(self.y_test, self.y_pred)
report = classification_report(self.y_test, self.y_pred, target_names=[str(i) for i in range(len(np.unique(self.y_test)))])
cm = confusion_matrix(self.y_test, self.y_pred)
print(f'正解率: {accuracy}')
print('混同行列:')
print(cm)
print('分類レポート:')
print(report)
def plot_confusion_matrix(self,class_names = [], file_name = None):
"""
混同行列をプロットする関数。
引数:
cm : numpy.ndarray
混同行列を表す2次元配列。
class_names : list of str, optional
クラス名のリスト。省略すると連番が表示される
file_name : str, optional
ファイル名が指定された場合、プロットはファイルに保存されます。
指定されない場合、プロットは画面に表示されます。
"""
plt.figure(figsize=(10, 7))
cm = confusion_matrix(self.y_test, self.y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=class_names, yticklabels=class_names)
plt.xlabel('予測ラベル')
plt.ylabel('実際のラベル')
plt.title('混同行列')
if file_name:
plt.savefig(file_name)
else:
plt.show()
plt.close()
def plot_learning_curve(self, file_name = None):
"""
学習履歴をプロットするメソッド
引数:
file_name : str, optional
ファイル名が指定された場合、プロットはファイルに保存されます。
指定されない場合、プロットは画面に表示されます。
"""
if not self.track_learning_curve:
print("学習曲線の履歴を取るように設定されていません。")
return
plt.figure()
plt.plot(self.history['train_sizes'], self.history['train_scores'], 'o-', color="r", label="トレーニングスコア")
plt.plot(self.history['train_sizes'], self.history['val_scores'], 'o-', color="g", label="検証スコア")
plt.title("学習曲線")
plt.xlabel("トレーニング例数")
plt.ylabel("スコア")
plt.legend(loc="best")
plt.grid()
if file_name:
plt.savefig(file_name)
else:
plt.show()
plt.close()
def plot_roc_curve(self, file_name = None):
"""
ROC曲線をプロットするメソッド
引数:
file_name : str, optional
ファイル名が指定された場合、プロットはファイルに保存されます。
指定されない場合、プロットは画面に表示されます。
"""
y_pred_proba = self.model.predict_proba(self.X_test)
fpr = {}
tpr = {}
roc_auc = {}
for i in range(len(np.unique(self.y_test))):
fpr[i], tpr[i], _ = roc_curve(self.y_test, y_pred_proba[:, i], pos_label=i)
roc_auc[i] = auc(fpr[i], tpr[i])
plt.figure(figsize=(8, 6))
for i in range(len(np.unique(self.y_test))):
plt.plot(fpr[i], tpr[i], lw=2, label='クラス {0} (AUC = {1:0.2f})'.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('偽陽性率')
plt.ylabel('真陽性率')
plt.title('ROC曲線')
plt.legend(loc="lower right")
plt.grid(alpha=0.3)
if file_name:
plt.savefig(file_name)
else:
plt.show()
plt.close()回帰モデル作成/予測用クラス(GenericRegressionModelUtil)
import pandas as pd
import numpy as np
from scipy.stats import norm
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_percentage_error, mean_absolute_error
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
class GenericRegressionModelUtil(ResourceManager):
def __init__(self, model_cls,df=None, model_path=None):
"""
クラスの初期化メソッド
:param model_cls:回帰で使うモデルのクラス
:param df: 初期データフレーム (pd.DataFrame)
:param model_path: モデルファイルのパス (str)
"""
super().__init__(df, model_path)
self.model_cls = model_cls
self.X_train = []
self.X_test = []
self.y_train = []
self.y_test = []
self.y_pred = []
self.params = {}
self.history = []
def fit(self, target, columns=None, params={}, test_size=0.2, random_state=42, track_learning_curve=False, split_method='split'):
"""
モデルを学習し、レポートを出力するメソッド
:param target: str, 予測対象となるターゲット列名
:param columns: list of str, 使用する特徴量の列名のリスト。ターゲットが含まれていても無視する。省略時は self.columns が使われる。
:param params: dict, optional (default={}), ランダムフォレストのハイパーパラメータ
:param test_size: float, optional (default=0.2), テストデータの割合
:param random_state: int, optional (default=42), 乱数シード
:param track_learning_curve: bool, optional (default=False), 学習曲線の履歴を取るかどうか
:param split_method: str, optional (default='split'), データ分割方法 ('split' または 'cross_val')
"""
if columns is not None:
self.columns = columns
X = self.df[[col for col in self.columns if col != target]]
y = self.df[target]
self.params = params
self.track_learning_curve = track_learning_curve
self.split_method = split_method
if split_method == 'split':
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
elif split_method == 'cross_val':
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
self.cross_val_scores = cross_val_score(self.model_cls(**params, random_state=random_state), X, y, cv=5)
self.model = self.model_cls(random_state=random_state, **params)
if track_learning_curve:
# 学習履歴を保存するリスト
self.history = {'train_sizes': [], 'train_scores': [], 'val_scores': []}
# 異なるサイズのトレーニングセットでモデルを再学習
train_sizes = np.linspace(0.1, 1.0, 10, endpoint=False) # 1.0 未満の最大値
for train_size in train_sizes:
X_train_sub, _, y_train_sub, _ = train_test_split(self.X_train, self.y_train, train_size=train_size, random_state=random_state)
self.model.fit(X_train_sub, y_train_sub)
# トレーニングスコアと検証スコアを計算
train_score = r2_score(y_train_sub, self.model.predict(X_train_sub))
val_score = r2_score(self.y_test, self.model.predict(self.X_test))
# スコアを保存
self.history['train_sizes'].append(len(X_train_sub))
self.history['train_scores'].append(train_score)
self.history['val_scores'].append(val_score)
else:
# モデルをトレーニング
self.model.fit(self.X_train, self.y_train)
self.y_pred = self.model.predict(self.X_test)
return self.model
def predict(self, columns = None, df = None):
"""
学習済みモデルを用いて予測を行うメソッド
:param columns: list, 予測に使うカラム名のリスト。省略するとself.columnsの全てのカラムが使われる。
:param df: pd.DataFrame, 予測対象の特徴量データフレーム
:return: np.ndarray, 予測結果
"""
columns = self.columns if columns is None else columns
X = self.df[columns] if df is None else df
return self.model.predict(X)
def fit_with_grid_search(self, target, columns, param_grid, test_size=0.2, random_state=42):
"""
グリッドサーチを使用してハイパーパラメータをチューニングし、最適なモデルを見つけるメソッド
:param target: str, 予測対象となるターゲット列名
:param columns: list of str, 使用する特徴量の列名のリスト。ターゲットが含まれていても無視する。None を指定すると self.columnsが使われる。
:param param_grid: dict, グリッドサーチで試すハイパーパラメータの辞書
:param test_size: float, optional (default=0.2), テストデータの割合
:param random_state: int, optional (default=42), 乱数シード
"""
if columns is not None:
self.columns = columns
X = self.df[[col for col in self.columns if col != target]]
y = self.df[target]
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
self.model = self.model_cls(random_state=random_state)
grid_search = GridSearchCV(estimator=self.model, param_grid=param_grid, cv=5, scoring='r2', n_jobs=-1)
grid_search.fit(self.X_train, self.y_train)
self.model = grid_search.best_estimator_
self.params = grid_search.best_params_
best_score = grid_search.best_score_
self.y_pred = self.model.predict(self.X_test)
print(f'最適なハイパーパラメータ: {self.params}')
print(f'グリッドサーチの最適なスコア: {best_score}')
return self.model
def evaluate(self):
"""
回帰モデルの評価指標を計算して出力するメソッド
"""
# モデルの精度を評価する
mse = mean_squared_error(self.y_test, self.y_pred)
rmse = np.sqrt(mse) # RMSE
mae = mean_absolute_error(self.y_test, self.y_pred)
r2 = r2_score(self.y_test, self.y_pred)
mape = mean_absolute_percentage_error(self.y_test, self.y_pred)
# 統計情報を表示
print(f'{self.y_test}の統計情報:')
print(f'最小値(Min): {self.y_test.min()}')
print(f'最大値(Max): {self.y_test.max()}')
print(f'平均値(Mean): {self.y_test.mean()}')
print(f'標準偏差(Std): {self.y_test.std()}')
print(f'分散(Var): {self.y_test.var()}')
# 精度指標を出力する
print(f'平均絶対誤差 (Mean Absolute Error): {mae}')
print(f'平均二乗誤差 (Mean Squared Error): {mse}')
print(f'ルート平均二乗誤差 (Root Mean Squared Error): {rmse}')
print(f'平均絶対パーセンテージ誤差 (MAPE): {mape}')
print(f'決定係数 (R^2 Score): {r2}')
# 特徴量の重要度を表示する
feature_importances = self.model.feature_importances_
importance_df = pd.DataFrame({'特徴量 (Feature)': self.columns, '重要度 (Importance)': feature_importances})
importance_df = importance_df.sort_values(by='重要度 (Importance)', ascending=False)
print("\n特徴量の重要度:")
print(importance_df)
def plot_learning_curve(self,file_name = None):
"""
学習履歴をプロットするメソッド
引数:
file_name : str, optional
ファイル名が指定された場合、プロットはファイルに保存されます。
指定されない場合、プロットは画面に表示されます。
"""
if not self.track_learning_curve:
print("学習曲線の履歴を取るように設定されていません。")
return
plt.figure()
plt.plot(self.history['train_sizes'], self.history['train_scores'], 'o-', color="r", label="トレーニングスコア")
plt.plot(self.history['train_sizes'], self.history['val_scores'], 'o-', color="g", label="検証スコア")
plt.title("学習曲線")
plt.xlabel("トレーニング例数")
plt.ylabel("スコア")
plt.legend(loc="best")
plt.grid()
if file_name:
plt.savefig(file_name)
else:
plt.show()
plt.close()
def plot_diagnostics(self, file_name = None):
"""
予実の折れ線、散布図、回帰曲線、残渣プロットを描画するメソッド
引数:
file_name : str, optional
ファイル名が指定された場合、プロットはファイルに保存されます。
指定されない場合、プロットは画面に表示されます。
"""
# 残差の計算
residuals = self.y_test - self.y_pred
fig, axs = plt.subplots(1, 4, figsize=(18, 5))
# 実際の値と予測値の折れ線グラフ
axs[0].plot(self.y_test.values, label='実際の値 (Actual)', linestyle='-', marker=None)
axs[0].plot(self.y_pred, label='予測値 (Predicted)', color='red', linestyle='-', marker=None)
axs[0].set_xlabel('サンプルインデックス (Sample Index)')
axs[0].set_ylabel('値 (Value)')
axs[0].set_title('実際の値 VS 予測値\n(Comparison of Actual and Predicted Values)')
axs[0].legend()
# 実際の値と予測値の散布図
axs[1].scatter(self.y_test, self.y_pred, alpha=0.3, label='予測値 (Predicted)')
axs[1].plot([self.y_test.min(), self.y_test.max()], [self.y_test.min(), self.y_test.max()], 'r--', label='対角線 (y=x)')
# 回帰線の計算
slope, intercept = np.polyfit(self.y_test, self.y_pred, 1)
r2 = r2_score(self.y_test, self.y_pred)
axs[1].plot(self.y_test, slope * self.y_test + intercept, color='blue', linestyle='-', linewidth=2, label=f'回帰線 (y={slope:.2f}x + {intercept:.2f}, $R^2$={r2:.2f})')
axs[1].set_xlabel('実際の値 (Actual)')
axs[1].set_ylabel('予測値 (Predicted)')
axs[1].set_title('実際の値 vs 予測値\n(Actual vs Predicted)')
axs[1].legend()
# 残差プロット
axs[2].scatter(self.y_pred, residuals, alpha=0.3, label='残差 (Residuals)')
axs[2].hlines(y=0, xmin=self.y_pred.min(), xmax=self.y_pred.max(), linestyles='dashed', label='y=0')
# 残差の平均と標準偏差を計算
residuals_mean = np.mean(residuals)
residuals_std = np.std(residuals)
# y_pred をソートし、それに対応する範囲を再計算
sorted_indices = np.argsort(self.y_pred)
sorted_y_pred = self.y_pred[sorted_indices]
sorted_upper = residuals_mean + residuals_std
sorted_lower = residuals_mean - residuals_std
axs[2].axhline(y=residuals_mean, color='blue', linestyle='--', label=f'平均 (Mean): {residuals_mean:.2f}')
# 標準偏差の範囲を水色で塗りつぶし
axs[2].fill_between(
sorted_y_pred, # ソートされた予測値
sorted_lower, # 下限 (固定値)
sorted_upper, # 上限 (固定値)
color='lightblue',
alpha=0.4,
label=f'標準偏差 (Std): {residuals_std:.2f}'
)
axs[2].set_xlabel('予測値 (Predicted)')
axs[2].set_ylabel('残差 (Residuals)')
axs[2].set_title('残差プロット\n(Residual Plot)')
axs[2].legend()
# 残差のヒストグラム
axs[3].hist(residuals, bins=30, edgecolor='k', density=True, alpha=0.6, color='g')
# 残差のヒストグラムに正規分布曲線を追加
xmin, xmax = axs[3].get_xlim()
x = np.linspace(xmin, xmax, 100)
p = norm.pdf(x, residuals_mean, residuals_std)
axs[3].plot(x, p, 'k', linewidth=2)
axs[3].set_xlabel('残差 (Residuals)')
axs[3].set_ylabel('頻度 (Frequency)')
axs[3].set_title('残差のヒストグラム\n(Histogram of Residuals)')
plt.tight_layout()
if file_name:
plt.savefig(file_name)
else:
plt.show()
plt.close()まとめ
今回の記事では、アンサンブル手法を用いた分類と回帰のモデルが簡単に作成・評価できる自作クラスについて解説しました。
複数のアルゴリズムを簡単に切り替えられるというコンセプトのもと、CSVやDataFrameデータに対して直感的な操作が可能です。
この汎用クラスを活用することで、皆さんのプロジェクトに最も適した分類/回帰モデルの選定が、より簡単になります。ぜひこのクラスにご自身の必要な機能を実装し、実務に役立てて頂ければ光栄です。








コメント