
機械学習の精度をさらに向上させる手法として注目されているのが「アンサンブル学習」です。分類や回帰といった課題において、複数のアルゴリズムを組み合わせることで、それぞれの強みを引き出し、弱点を補うこの手法は、データ分析の現場で強力な武器となります。
本記事では、アンサンブル学習の基本的な仕組みや種類(バギング、ブースティング、スタッキング)をわかりやすく解説するとともに、アンサンブル学習が使われている7つの手法(ランダムフォレスト、XGBoost、GBDT、LightGBM、CatBoost、AdaBoost、Stacking)について、分類と回帰のサンプルプログラムを掲載しています。
この記事の内容を参考に、みなさんの案件にアンサンブル学習を取り入れてみて下さい。
アンサンブル学習とは
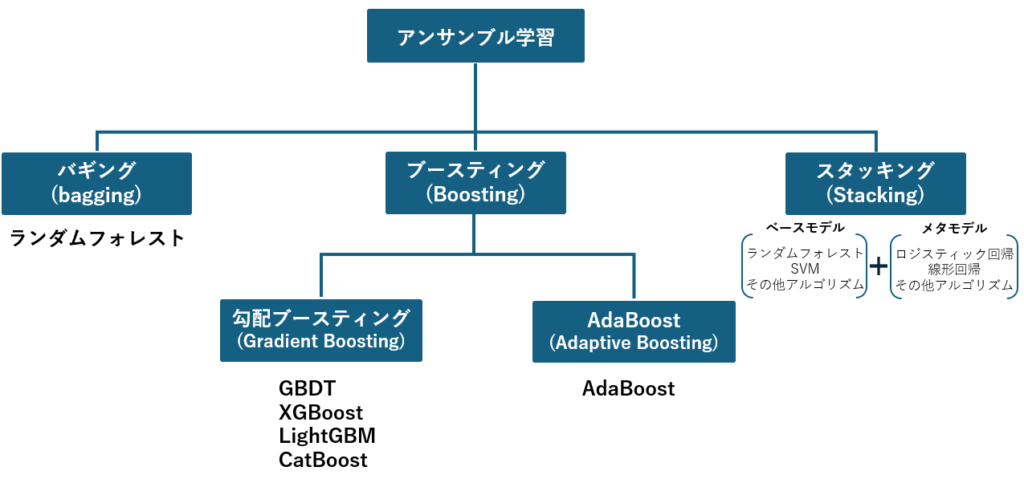
アンサンブル学習(Ensemble Learning)は、機械学習において複数のモデルを組み合わせることで、予測精度を向上させる手法です。特に分類問題や回帰問題の複雑なデータ構造を扱う際に高い性能を発揮します。
この手法の中心的な考え方は、異なるモデルを組み合わせることで、それぞれのモデルの強みを活かし、個々の弱点を補完することです。代表的なアンサンブル学習の手法として、バギング、ブースティング、スタッキングがあります。
一般的に、GBDT(Gradient Boosting Decision Trees)は勾配ブースティングの総称です。
しかし、scikit-learnでは純粋な勾配ブースティングとして実装されています。
一方、XGBoost、LightGBM、CatBoostは勾配ブースティングを改良したモデルで、それぞれ得意な用途において高性能を発揮します。
用途によっては純粋なGBDTが適する場合もあるため、本記事ではGBDTを1つの実装として取り扱います。
バギング(Bagging)
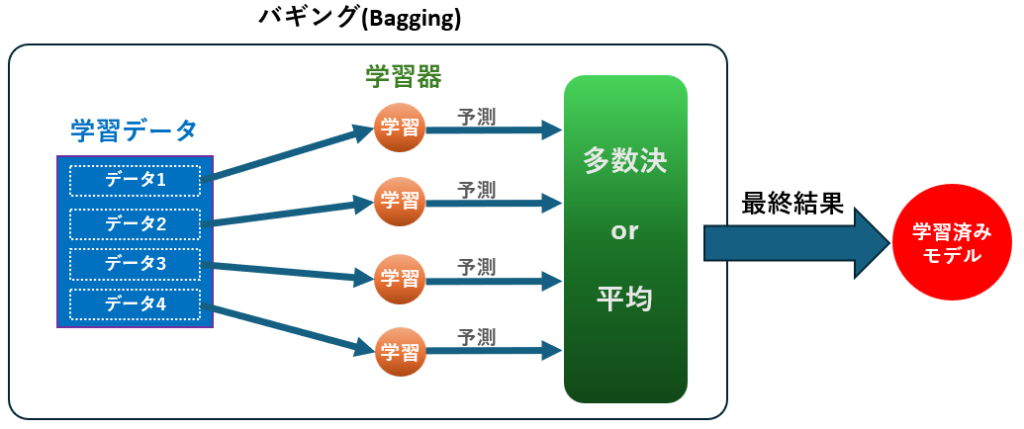
多数の決定木を独立に学習させ、その予測結果を平均化または多数決で結合します。これにより、過学習を防ぎつつ高い予測精度を実現します。ランダムフォレストがこの方式を使っています。
動作原理
- 訓練データから複数のサブセットをブートストラップサンプリング(復元抽出)によって作成
- 各サブセットに対して独立に弱学習器(通常は決定木などのシンプルなモデル)を学習
- すべての学習されたモデルに対して、新しいデータに基づいた予測を実施
- 分類問題では各モデルの予測結果の多数決、回帰問題では平均を予測結果として出力
ブースティング(Boosting)
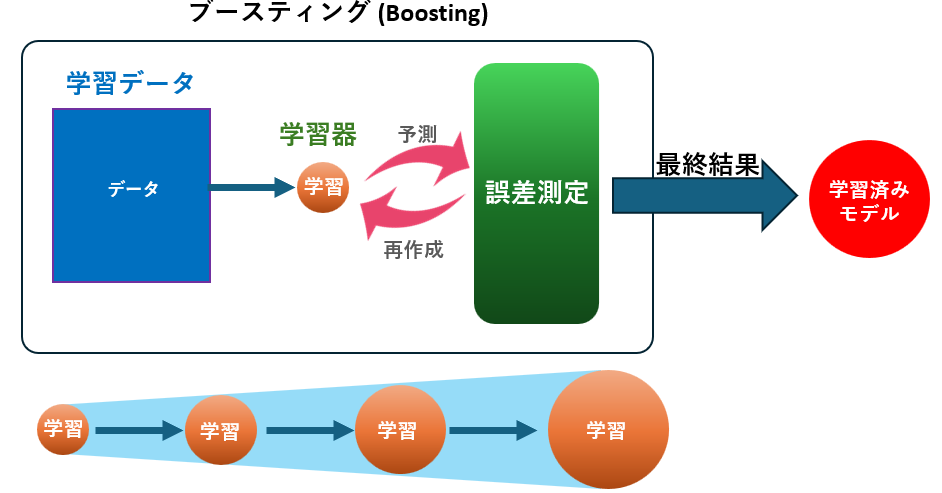
複数の弱学習器を逐次的に学習させます。それぞれの学習器は、前の学習器がうまく予測できなかった部分(誤差)を重点的に学習します。最適化に際して、誤差の勾配を利用する勾配ブースティングと、誤差の重みを調整するAdaBoostの2通りがあます。
- 勾配ブースティング(Gradient Boosting)
モデルの予測誤差の勾配に基づいて、新しい学習器を最適化します。これにより、前のモデルが持つ誤差を効率的に修正します。XGBoost、GBDT、LightGBM、CatBoostなどが代表例です。 - AdaBoost(Adaptive Boosting)
初期重みは全サンプルに均等に割り当てられますが、誤分類されたサンプルに対して重みが増加します。次の学習器は、これらの重みを考慮して学習します。
動作原理
- 初期モデル(弱学習器)を訓練データで学習
- モデルの誤差に基づいて新しいモデルを学習
- 逐次的に新しい弱学習器を追加し、各学習器は前の学習器の誤差を修正するように学習
- 最終的に全てのモデルの予測結果を加重平均して最終予測を出力
スタッキング(Stacking)
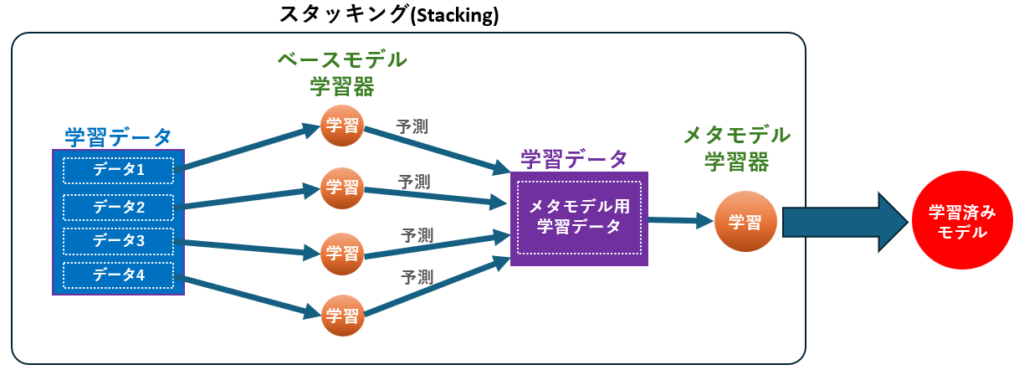
異なる種類のモデルを組み合わせ、それぞれのモデルの予測結果を新たな特徴量として使用し、メタモデルで最終予測を行います。メタモデルとしてロジスティック回帰、線形回帰、勾配ブースティングなどが使われます。
動作原理
- 異なるアルゴリズムを持つ複数のベースモデルを用意
- 各ベースモデルを訓練データで学習
- 各ベースモデルに新しいデータで予測させ、その予測結果を収集
- ベースモデルの予測結果を新たな特徴量(訓練データ)として取りまとめ
- 取りまとめた訓練データを、メタモデル(スタッキングモデル)で学習
- メタモデルを用いて最終予測を出力
アンサンブル学習の特徴

アンサンブル学習には次の特徴があります。
- 高い予測精度
多くのデータセットにおいて、アンサンブル学習は高い予測精度を実現します。複数のモデルを組み合わせることで、各モデルの弱点を補完し、全体の精度を向上させます。 - 逐次的学習(ブースティングに特有)
勾配ブースティングやAdaBoostは、複数の弱学習器(通常は決定木)を逐次的に訓練し、各ステップで前のモデルの誤差を修正しながら新しいモデルを追加します。 - 並列学習(バギングに特有)
ランダムフォレストなどのバギング手法では、独立に複数のモデルを並列に学習させ、最終的な予測結果を多数決や平均で結合します。 - モデルの多様性
アンサンブル学習は、異なるアルゴリズムやパラメータ設定を持つ複数のモデルを組み合わせるため、各モデルの強みを活かしつつ、全体としての予測精度を向上させます。 - 適応性の高いモデル
アンサンブル学習は、多種多様なデータセットや課題に対して適応可能であり、分類問題や回帰問題の両方に適用可能です。 - ロバスト性
アンサンブル学習は、異常値やノイズに対して比較的ロバストな性能を持つため、データの質が必ずしも高くない場合でも有効です。 - 調整可能なハイパーパラメータ
アンサンブル学習には多くのハイパーパラメータがあり、これを調整することでモデルの性能を最適化することができます。例として、学習率、決定木の深さ、ブースティングの反復回数などがあります。 - 自動特徴選択
多くのアンサンブル学習アルゴリズムでは、不要な特徴を自動的に無視し、重要な特徴のみを使用する能力があります。これにより、過学習を防ぎつつ、モデルの性能を向上させることができます。 - 解釈可能性
決定木ベースのアンサンブル学習アルゴリズムは、特徴の重要度を評価する機能を持ち、モデルの解釈性を向上させることができます。これにより、どの特徴が予測に重要かを理解することができます。
アンサンブル学習のメリット・デメリット
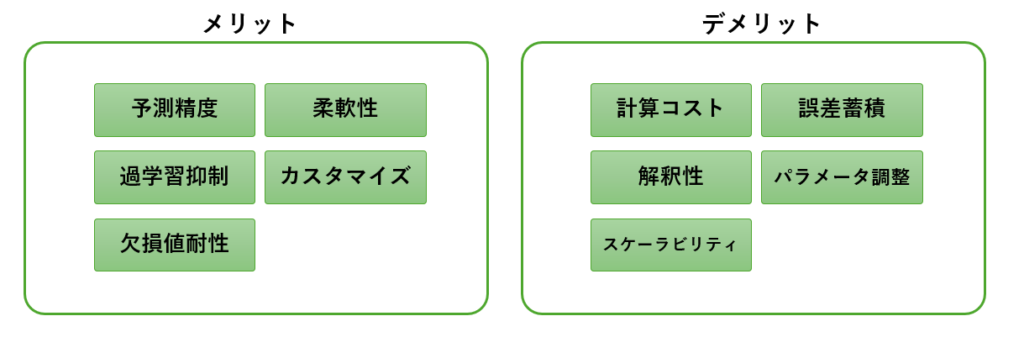
アンサンブル学習(Gradient Boosting)は、その高い予測精度と汎用性から、機械学習の中でも特に注目されています。しかし、万能な手法ではなく、メリットとデメリットの両方を正しく理解することが大切です。ここでは、アンサンブル学習のメリット、デメリットを解説します。
メリット
- 高い予測精度
アンサンブル学習は、データの複雑な非線形関係を学習できるため、他の単一のアルゴリズムと比較して高精度な予測を行えます。バギングやブースティングによって、個々の弱学習器の弱点を補完するためです。 - 高い柔軟性
アンサンブル学習は、連続データ、カテゴリデータの両方を扱えるため、さまざまなデータセットに適用可能です。例えば、ランダムフォレストや勾配ブースティングなど、多様なモデルが存在します。 - ハイパーパラメータの調整でカスタマイズ可能
学習率や木の深さなど、さまざまなハイパーパラメータを調整することで、モデルの性能をチューニングできます。これにより、適切な設定を見つけることで特定の問題に最適化できます。 - 過学習を抑制できる仕組み
バギングやブースティングを使用することで、過学習(訓練データに過度に適合する状態)を効果的に抑えることができます。例えば、学習率(Learning Rate)や早期終了(Early Stopping)を用いることができます。 - 欠損値への耐性
一部のアンサンブルアルゴリズム(例:XGBoostやLightGBM)では、欠損値を自然に処理できるため、クレンジングの負担が軽減されます。
デメリット
- 計算コストが高い
モモデルを複数組み合わせるため、他の単一のアルゴリズム(例:単一の決定木)と比較して計算時間が長くなりがちです。特に、大規模データセットや多数の特徴量を扱う場合にはリソースを多く消費します。 - ハイパーパラメータ調整が難しい
メリットでもあるハイパーパラメータの多さは、設定を誤ると性能が大幅に低下する要因にもなります。学習率や木の深さ、ブースティングの回数など、複数のパラメータを適切に調整するには経験や試行錯誤が必要です。 - 解釈性が低い
アンサンブル学習は「ブラックボックス」とみなされることが多く、モデルの結果を直感的に説明するのが難しい場合があります。製造業のように現場での納得感が求められる場合には、この点が障壁になることもあります。 - 誤差蓄積による精度低下
ブースティング系アルゴリズムでは、誤差を繰り返し補正する仕組みにより、データ内のノイズや外れ値に対して誤差が蓄積されてしまい、モデル全体の性能を低下させるリスクがあります。 - 大規模データでのスケーラビリティの課題
データが増えると計算負荷が増大し、学習が遅くなるため、大規模なリアルタイムデータ処理には適していない場合があります。
アンサンブル学習に適したデータとは?
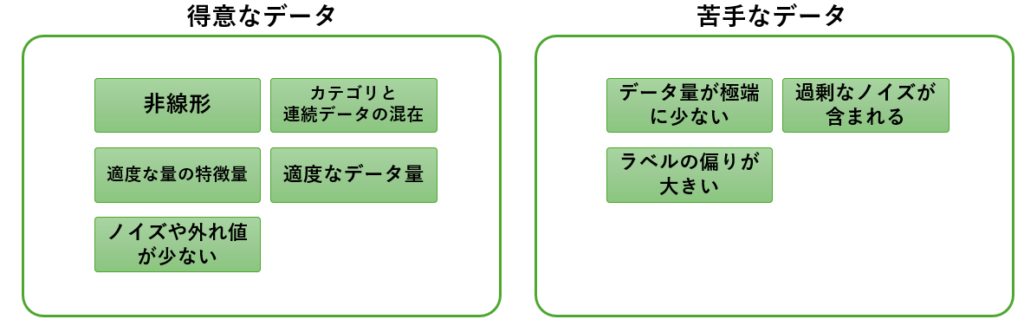
アンサンブル学習の性能を最大限に引き出すためには「適したデータ」を選ぶことが重要です。
ここでは、アンサンブル学習の特性を踏まえ、どのようなデータがこのアルゴリズムに適しているのかを解説します。
アンサンブル学習に適したデータ
- 非線形な関係を含むデータ
アンサンブル学習(特に勾配ブースティングやランダムフォレスト)は、決定木を基盤としているため、データ間の非線形な関係をうまく学習できます。複雑な相関や非線形性が多いデータに適しています
例:製造装置のセンサー値と製品品質の関係、異常検知における多次元データ間の複雑な相関 - カテゴリデータと連続データが混在するデータ
アンサンブル学習はカテゴリデータと連続データの両方を扱える柔軟性を持っています。データ前処理の負担が比較的少なく、エンコーディングやスケーリングの必要がないケースも多いです。
例:製品タイプ(A, B, C)や操作モード(自動、手動)、温度、圧力、湿度などのセンサーデータ - 適度な量の特徴量を持つデータ
アンサンブル学習は、多数の特徴量がある場合でも利用可能ですが、特徴量が適度な場合に特に優れた性能を発揮します。不要な特徴量やノイズが多いと、モデルの性能が低下する可能性があるため、特徴選択を事前に行うことが望ましいです。大規模データを扱う場合は、LightGBMやXGBoostなどの最適化された実装を用いるのが効果的です。 - 適度なデータ量
アンサンブル学習は、多数の特徴量がある場合でも利用可能ですが、特徴量が適度な場合に特に優れた性能を発揮します。不要な特徴量やノイズが多いと、モデルの性能が低下する可能性があるため、特徴選択を事前に行うことが望ましいです。大規模データを扱う場合は、LightGBMやXGBoostなどの最適化された実装を用いるのが効果的です。 - ノイズや外れ値が少ないデータ
アンサンブル学習は、学習の初期段階での誤差が後続のモデルに大きな影響を与えるため、ノイズや外れ値に敏感です。そのため、以下のような前処理を行うことが推奨されます。
(外れ値の除去、欠損値の補完、データのクレンジング)
アンサンブル学習に不向きなデータ
- データ量が極端に少ない場合
データ量が非常に少ない場合(例: 数百件以下)、過学習に陥りやすくなります。このような場合は、線形回帰やロジスティック回帰といったシンプルなモデルが適していることが多いです。 - 過剰なノイズが含まれる場合
センサーの異常値や測定誤差など、過剰なノイズを含むデータは、アンサンブル学習の性能を低下させる原因となります。この場合、データの前処理が欠かせません。 - ラベルの偏りが大きい場合
分類タスクで、正例と負例の数が極端に偏っているデータでは、モデルが一方のラベルを優先的に学習してしまう可能性があります。この場合、サンプリング手法やクラス重み付けを活用することが必要です。
製造業における用途
- 異常検知
製造プロセスのデータを用いて、異常や故障の予兆を早期に検出するためにアンサンブル学習を使用します。センサーデータや機器の稼働データを解析することで、正常な状態と異常な状態を区別し、異常が発生する前に対策を講じることができます。 - 品質管理
製品の品質管理において、製造プロセス中のデータを分析し、製品の品質を予測します。例えば、温度や圧力、湿度などの環境条件が最終製品の品質に与える影響を評価し、最適な製造条件を見つけることができます。 - 需要予測
製品の需要を予測するために、アンサンブル学習を用います。過去の販売データや市場のトレンド、季節性の影響などを考慮して、将来の需要を予測し、製造計画や在庫管理を最適化します。 - 予知保全
機器のメンテナンスにおいて、故障が発生する前に予防的な保全作業を行うためにアンサンブル学習を使用します。センサーデータや運転履歴データを解析して、機器の劣化状態を予測し、最適なタイミングでメンテナンスを実施します。 - 製造プロセスの最適化
製造プロセスの様々なパラメータを最適化するためにアンサンブル学習を用います。例えば、原材料の混合比率や加工温度、時間などを最適化して、製品の品質と生産効率を向上させます
アンサンブル学習における7つの手法
アンサンブル学習でよく使われる7つの手法について、分類と予測におけるモデル作成のサンプルコード付きで紹介します。
いずれの手法においても、インポートするモジュールと関数が異なるだけで、データの与え方や予測の仕方は共通です。複数の手法を試してみて、最も精度の高いものを採用するという方法もよく行われます。
ランダムフォレスト(Random Forest)
ランダムフォレストは、多数の決定木を用いたバギング(Bootstrap Aggregating)のアンサンブル学習手法です。ランダムに選ばれたデータのサブセットを用いて複数の決定木を学習し、その結果を平均化または多数決で集約して最終予測を行います。
# ランダムフォレストによる分類プログラムサンプル
# pip install scikit-learn
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# データの準備
data = load_iris() # アイリスデータセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# ランダムフォレスト分類器の作成と訓練
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")# ランダムフォレストによる回帰プログラムサンプル
# pip install scikit-learn
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# データの準備
data = load_boston() # ボストン住宅データセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# ランダムフォレスト回帰器の作成と訓練
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.4f}")ランダムフォレストの特徴は以下の通りです。
- バギング: 各決定木は独立に学習され、データのサブセットを使用して作成されます。
- 並列計算: 各決定木は独立しているため、並列計算が容易です。
- 過学習の抑制: 多数の決定木の結果を平均化することで、過学習を抑制します。
- 特徴の重要度評価: 特徴の重要度を評価する機能があり、どの特徴が予測に重要かを理解することができます。
XGBoost (Extreme Gradient Boosting)
XGBoostは、勾配ブースティングの一種で、効率的かつ高性能なモデルを提供するために最適化されたライブラリです。並列処理や分散コンピューティングをサポートしており、多くの機械学習コンペティションで使用されています。特徴としては、過学習を防ぐための正則化や、欠損値の処理、高速な計算などがあります。
# XGBoostによる回帰プログラムサンプル
# pip install xgboost
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# データの準備
data = load_boston() # ボストン住宅データセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# XGBoost回帰器の作成と訓練
model = xgb.XGBRegressor(n_estimators=100, learning_rate=0.1)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.4f}")# XGBoostによる分類プログラムサンプル
# pip install xgboost
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# データの準備
data = load_iris() # アイリスデータセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# XGBoost分類器の作成と訓練
model = xgb.XGBClassifier(n_estimators=100, learning_rate=0.1)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")XGBoostの主な特徴は以下の通りです。
- 高い予測精度: 多くの機械学習コンペティションで使用される理由は、その高い予測精度にあります。
- 正則化: L1(Lasso)およびL2(Ridge)正則化が組み込まれており、過学習を防ぎます。
- 並列処理: 並列計算をサポートしており、学習速度が高速です。
- 欠損値処理: 欠損値を自動的に処理し、データの前処理を簡素化します。
- カスタマイズ性: 多くのパラメータを調整できるため、モデルのカスタマイズが容易です。
- 早期停止: モデルの訓練中に性能が向上しなくなった場合に学習を停止する機能があり、効率的です。
GDBT(Gradient Boosting Decision Tree)
GDBTは、最も純粋な勾配ブースティングの具体的な実装であり、主に決定木を弱学習器として使用します。GDBTは、勾配ブースティングフレームワークに基づいて、逐次的に弱学習器(決定木)を追加し、前のモデルの誤差を補正しながら学習します。
# GBDTによる分類プログラムサンプル
# pip install gbdt
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# データの準備
data = load_iris() # アイリスデータセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# GBDT分類器の作成と訓練
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
# GBDTによる回帰プログラムサンプル
# pip install gbdt
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# データの準備
data = load_boston() # ボストン住宅データセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# GBDT回帰器の作成と訓練
model = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.4f}")
GDBTの主な特徴は以下の通りです。
- 逐次的学習: モデルを逐次的に構築し、前のモデルの誤差を補正します。
- 高い予測精度: 適切な調整により、非常に高い予測精度を実現します。
- 柔軟性: 回帰問題と分類問題の両方に適用可能です。
- ハイパーパラメータ調整: 学習率、決定木の深さ、繰り返し回数など、調整可能なハイパーパラメータが多数あります。
LightGBM (Light Gradient Boosting Machine)
LightGBMは、Microsoftによって開発された勾配ブースティングのライブラリで、大規模データセットに対する効率的な処理が特徴です。葉(リーフ)ベースの成長戦略を採用しており、深い木を構築することで、より複雑なデータパターンをキャプチャできます。また、並列学習とGPU学習をサポートしています。
# LightGBMによる分類プログラムサンプル
# pip install lightgbm
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# データの準備
data = load_iris() # アイリスデータセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# LightGBM分類器の作成と訓練
model = lgb.LGBMClassifier(n_estimators=100, learning_rate=0.1)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
# LightGBMによる回帰プログラムサンプル
# pip install lightgbm
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# データの準備
data = load_boston() # ボストン住宅データセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# LightGBM回帰器の作成と訓練
model = lgb.LGBMRegressor(n_estimators=100, learning_rate=0.1)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.4f}")LightGBMの主な特徴は以下の通りです。
- 高速学習: Leaf-wise(葉ごとの)成長戦略を採用しており、学習が非常に高速です。
- 大規模データ対応: 大規模なデータセットに対しても効率的に処理でき、メモリの使用量も少ないです。
- 並列学習: 並列処理をサポートしており、大規模なデータセットでも高速に学習できます。
- GPUサポート: GPUを使用することで、さらに高速な学習が可能です。
- ハイパーパラメータの自動調整: 一部のハイパーパラメータは自動的に調整され、ユーザーの手間を減らします。
CatBoost
CatBoostは、Yandexによって開発された勾配ブースティングのライブラリで、カテゴリカルデータを効率的に扱う機能があります。他の勾配ブースティング手法と比べて、デフォルトの設定で高い精度を発揮することが多いです。また、欠損値の自動処理や学習速度の向上が特徴です。
# CatBoostによる分類プログラムサンプル
# pip install catboost
from catboost import CatBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# データの準備
data = load_iris() # アイリスデータセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# CatBoost分類器の作成と訓練
model = CatBoostClassifier(iterations=1000, learning_rate=0.1, depth=6, verbose=False)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")# CatBoostによる回帰プログラムサンプル
# pip install catboost
from catboost import CatBoostRegressor
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# データの準備
data = load_boston() # ボストン住宅データセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# CatBoost回帰器の作成と訓練
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=6, verbose=False)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.4f}")CatBoostの主な特徴は以下の通りです。
- カテゴリカルデータの効率的な処理: カテゴリカルデータを自動的にエンコーディングし、高い精度を実現します。
- デフォルト設定で高い性能: 特にパラメータ調整をしなくても、デフォルト設定で高い性能を発揮します。
- 欠損値処理: 欠損値を自動的に処理し、モデルの学習に影響を与えません。
- 高速学習: 他の勾配ブースティング手法に比べて学習速度が速く、効率的です。
- クロスバリデーションのサポート: 学習データを分割して、モデルの汎化性能を高めるためのクロスバリデーションをサポートしています。
AdaBoost
AdaBoost(Adaptive Boosting)は、ブースティングの一種で、誤分類されたサンプルに重みを増加させることによって、複数の弱学習器を逐次的に学習させるアルゴリズムです。この手法は、前の学習器の誤りを次の学習器が補正することで、全体の予測精度を向上させます。
# AdaBoostによる分類プログラムサンプル
# pip install scikit-learn
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# データの準備
data = load_iris() # アイリスデータセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# AdaBoost分類器の作成と訓練
base_estimator = DecisionTreeClassifier(max_depth=1)
model = AdaBoostClassifier(base_estimator=base_estimator, n_estimators=50, learning_rate=1.0, random_state=42)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")# AdaBoostによる回帰プログラムサンプル
# pip install scikit-learn
from sklearn.ensemble import AdaBoostRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# データの準備
data = load_boston() # ボストン住宅データセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# AdaBoost回帰器の作成と訓練
base_estimator = DecisionTreeRegressor(max_depth=1)
model = AdaBoostRegressor(base_estimator=base_estimator, n_estimators=50, learning_rate=1.0, random_state=42)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 精度の評価
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.4f}")AdaBoostの主な特徴は以下の通りです。
- 逐次的学習: 各弱学習器は、前の学習器が誤分類したサンプルを重視して学習します。
- 高い柔軟性: 分類問題と回帰問題の両方に適用可能です。
- 過学習の抑制: 学習率や基礎学習器の深さを調整することで過学習を抑えます。
- 高い精度: 弱学習器の集約により、高い予測精度を実現します。
- 簡便な実装:
scikit-learnなどのライブラリを使用して簡単に実装できます。
スタッキング(Stacking)
スタッキング(Stacking)は、複数の異なるモデル(ベースモデル)を組み合わせ、それらの予測結果をメタモデルで学習し最終予測を行うアンサンブル学習手法です。この手法は、各モデルの強みを最大限に活かすことで、高い予測精度を実現します。
# スタッキングによる分類プログラムサンプル
# pip install scikit-learn
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# データの準備
data = load_iris() # アイリスデータセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# ベースモデルの作成
base_models = [
('rf', RandomForestClassifier(n_estimators=100, random_state=42)),
('dt', DecisionTreeClassifier(random_state=42))
]
# メタモデルの作成
meta_model = LogisticRegression()
# スタッキングモデルの作成
stacking_model = StackingClassifier(estimators=base_models, final_estimator=meta_model)
stacking_model.fit(X_train, y_train)
# 予測
y_pred = stacking_model.predict(X_test)
# 精度の評価
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")# スタッキングによる回帰プログラムサンプル
# pip install scikit-learn
from sklearn.ensemble import StackingRegressor
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# データの準備
data = load_boston() # ボストン住宅データセットの読み込み
X, y = data.data, data.target # 特徴量とターゲットの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 訓練データとテストデータの分割
# ベースモデルの作成
base_models = [
('rf', RandomForestRegressor(n_estimators=100, random_state=42)),
('dt', DecisionTreeRegressor(random_state=42))
]
# メタモデルの作成
meta_model = LinearRegression()
# スタッキングモデルの作成
stacking_model = StackingRegressor(estimators=base_models, final_estimator=meta_model)
stacking_model.fit(X_train, y_train)
# 予測
y_pred = stacking_model.predict(X_test)
# 精度の評価
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.4f}")スタッキングの主な特徴は以下の通りです。
- モデルの多様性: 異なるアルゴリズムを組み合わせることで、多様な視点からデータを学習できます。
- 高い精度: 各モデルの強みを最大限に活かし、弱点を補完することで、高い予測精度を実現します。
- 柔軟性: 分類問題と回帰問題の両方に適用可能です。
- 解釈可能性: メタモデルの結果を解析することで、どのベースモデルがどの程度寄与しているかを理解できます。
アンサンブル学習はどれを選べばよいか
勾配ブースティングにおける7つの手法について、それぞれの選択すべき状況をまとめておきます。
| 手法 | 特徴 | 選択すべき状況 |
|---|---|---|
| ランダムフォレスト | バギング、並列計算、過学習の抑制、特徴の重要度評価 | 高い解釈性が求められる場合、過学習を防ぎつつ性能を安定させたい場合、 データにノイズが多い場合 |
| XGBoost | 高い予測精度、正則化、並列処理、欠損値処理 | 高い予測精度が必要な場合、大規模データセットの場合、欠損値が存在する場合 |
| LightGBM | 高速学習、大規模データ対応、GPUサポート、並列学習 | 非常に大規模なデータセットを扱う場合、学習時間を短縮したい場合 |
| CatBoost | カテゴリカルデータの効率的な処理、デフォルト設定で高性能、欠損値処理 | カテゴリカルデータが多い場合、特にパラメータ調整せずに高精度を求める場合 |
| GBDT | 逐次的学習、高い予測精度、柔軟性、回帰・分類の両方に対応 | 過学習を防ぎつつ高精度を求める場合、カスタマイズが必要な場合 |
| AdaBoost | 逐次的学習、誤差の修正、高い柔軟性 | シンプルな弱学習器で高い精度を求める場合、誤差修正を重視したい場合 |
| スタッキング | 異なるアルゴリズムの組み合わせ、多様な視点からの学習 | 異なるモデルの強みを活かしたい場合、高い予測精度を求める場合 |
迷ったら、最初にGBDTを選択するのが良いでしょう。GBDTは純粋な勾配ブースティングの実装であるため、幅広いシーンで高い性能を発揮します。まずGBDTで評価し、更に精度を求めたい場合は、その他の手法を試すのが効果的です。
特徴量の選定方法
機械学習モデルの予測精度は、どの特徴量を使うかで大きく左右されます。特にアンサンブル回帰モデル(LightGBMやXGBoostなど)は、非線形な関係や冗長な情報に敏感なため、適切な特徴量選定が不可欠です。
選定方法は次の3つのステップで進めます。
- 特徴量候補の選定
時系列データから予測に使えそうな変数を抽出し、候補群を構築します。 - 冗長性の除去と安定性・多様性の確認
相関やVIFなどを用いて重複や多重共線性を排除し、代表的な特徴量を選びます。 - 重要度の評価
GBDTモデルに投入し、SplitやGainなどの指標で予測に寄与する特徴量を見極めます。
詳細については下記の記事で詳しく触れていますので、合わせてご確認下さい。ピペで使えるサンプルコード付きで掲載しています。
自動で特徴量を選定することも可能です。詳しくは下記の記事に記載しています。
スケーリング(loglog1p)による精度向上
アンサンブルモデル、特に勾配ブースティング系(XGBoost、LightGBM、CatBoostなど)を用いる場合、一般的な機械学習アルゴリズムとは異なり「説明変数のスケーリングは必須ではない」ことが多いです。ツリー系モデルは変数のスケールよりも分岐における相対的な閾値を重視するため、正規化・標準化の効果が限定的か、むしろ悪化する場合もあります。
一方で、以下の場合は目的変数のスケーリングが有効です。
- 目的変数(ターゲット)の分布が極端だったり外れ値を含む場合
- 数値レンジに数桁の開きがあるような連続値を予測する場合
スケーリングでは、log や log1p 変換がモデルの安定性を大きく高めることがあります。これは、「分布の偏りを補正する」効果があり、大きな外れ値や歪んだ分布を対数変換で圧縮し、損失関数(MSEやMAE)が極端値に引っ張られないようにします。
目的変数のスケーリングにおいて、以下の理由から正規化や標準化は使用しません。
正規化や標準化は「スケールを揃える」だけで、分布の歪みや外れ値への耐性はない。
特に Z-score 標準化(平均0、標準偏差1)にすると、元のスケールからの逆変換が直感的に難しくなる。
分布が非対称な場合、平均や標準偏差が有効に機能しないことも多い。
スケーリング方法
アンサンブルモデルのスケーリングでよく使われるのが、expと、expm1です。
これらは、目的に応じて使い分ける必要があります。
- exp
主に「値が必ず正の連続値」である目的変数(例:金額、売上など)を扱うときに使用 - expm1
ゼロを含む変数や、小さな値に対する精度を保ちたいときに有効
(例:負荷、アクセス数、待機時間など)
これら2つを、アルゴリズムに応じて使い分けます。
下記は、log1pを用いたサンプルです。
from numpy import log1p, expm1
# 学習時のスケーリング
y_train_scaled = log1p(y_train)
# モデルの学習と推論
y_pred_scaled = model.predict(X_test)アルゴリズムごとに推奨されるスケーリング方法は次の通りです。
| モデル | 説明変数のスケーリング | 目的変数のスケーリング | 備考 |
|---|---|---|---|
| ランダムフォレスト | 不要 | 状況次第 (log 有効な場合あり) | ツリーベースのためスケールの影響なし |
| GBDT(Gradient Boosting) | 不要 | 有効なことが多い | log1p で外れ値の影響を軽減 |
| AdaBoost | 不要 | 状況次第 (logで安定化可能) | 回帰の場合はロス関数の特性に注意 |
| CatBoost | 不要 (内部で自動処理) | やや有効 | 特徴量エンコーディングは強力 |
| スタッキング | 構成モデルに依存 | 構成モデルに依存 | 通常、事前の共通前処理が必要 |
特にスタッキングでは、「説明変数の前処理を統一しておくこと」と「目的変数のスケーリングは逆変換ができるよう注意」が重要です。構成モデルごとのスケーリング要否に合わせて調整するのがポイントです。
予測結果の逆変換
目的変数をスケーリングした場合、そのモデルが出力した予測値は、逆変換処理が必要です。逆変換を忘れると、評価指標(RMSE, MAEなど)が実際とずれてしまい、正しい評価ができません。必ず逆変換した値(元スケールに戻した値)で計算します。
np.log(y) ⇒ np.exp(y_pred) ・・・ y>0が前提
np.log1p(y)⇒ np.expm1(y_pred) ・・・y≧0に対応
from numpy import log1p, expm1
# 学習時のスケーリング
y_train_scaled = log1p(y_train)
# モデル学習・推論…
y_pred_scaled = model.predict(X_test)
# 予測結果の逆変換
y_pred = expm1(y_pred_scaled)学習時は高精度でも、本番では精度が出ない場合の対応
モデル学習時のテストでは高い精度が得られるのに、本番データを入れてみると精度がガクッと落ちる場合、「モデル」ではなく「データの分布のズレ」の可能性を疑ってみましょう。
Adversarial Validation(敵対的検証)という手法を使うことで、分布のズレを視覚的に確認できます。
詳しくは下記の記事で解説していますので、興味のある方はご一読ください。
まとめ
アンサンブル学習は、個々のモデルの弱点を補い、精度を向上させる強力な手法です。
本記事では、バギング、ブースティング、スタッキングという主要な手法について解説し、それぞれの特徴や使い所を示しました。
- バギング: モデルのばらつきを抑え、過学習を防ぐ
- ブースティング: モデルを連携させて難しい課題を克服する
- スタッキング: 複数モデルの組み合わせで全体の精度を最大化する
これらを適切に使い分けることで、分析の精度を高めるだけでなく、新たな知見を得られる可能性も広がります。ただし、アンサンブル学習には計算コストや過学習といった課題もあるため、データの性質や目的に応じた選択が重要です。
データ分析の現場で求められる「精度」と「汎用性」を実現するために、アンサンブル学習は欠かせないツールとなっています。是非、今回の内容を参考に、アンサンブル学習にチャレンジしてみてください。








コメント