
膨大なデータを理解し、活用するための手法の一つとして「クラスタリング」は、長い歴史を持ち、その有効性が広く認識されています。
クラスタリングは、データを似た特徴ごとにグループに分けることで、データのパターンや構造を明確にし、新たな洞察を得るための強力な手段です。
本記事では、クラスタリングの基本概念から、その具体的な用途や代表的なアルゴリズムについて詳しく解説していきます。
クラスタリングとは
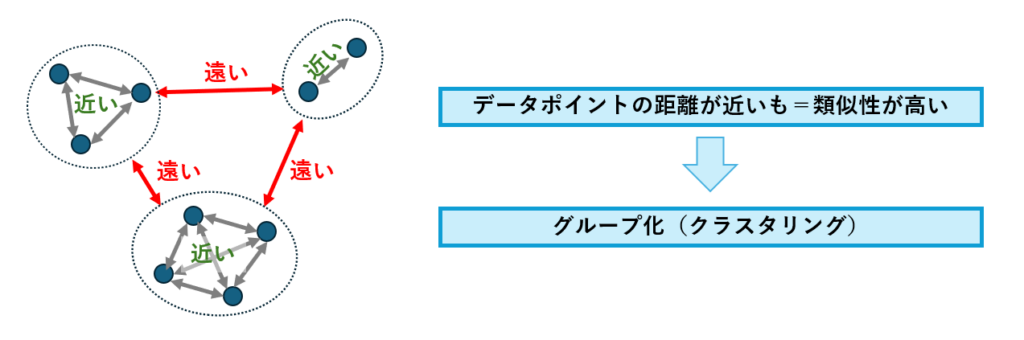
クラスタリングは、データをいくつかのグループ(クラスタ)に分ける分析手法です。この方法では、データの性質やパターンを自動的にグループ化することができます。
クラスタリングは教師無し学習の一種です。教師無し学習とは、データに事前にラベル(正解)が付けられていない状態で、アルゴリズムがデータのパターンを自動的に見つけ出す手法です。
つまり、クラスタリングでは「どのデータが同じカテゴリに属するのか?」という情報が最初から与えられていなくても、アルゴリズムがデータをグループに分けることができます。
クラスタリングでは、以下のような特徴があります:
クラスタリングの特徴
クラスタリングには次の特徴があります。
- 教師無し学習
クラスタリングは、データに事前のラベルがない状態で学習を行う手法であり、教師無し学習に分類されます。データのパターンや構造を自動的に抽出することができます。 - グループ化
クラスタリングは、似たようなデータを同じグループ(クラスタ)にまとめる手法です。これにより、データの内在する構造やパターンを発見することができます。
- 距離に基づく分類
データポイント間の類似性を測るために距離(ユークリッド距離やマンハッタン距離など)を使用します。類似したデータは近い位置にあり、同じクラスタにまとめられます。 - スケーラビリティ
大量のデータに対して適用可能であり、データ量が増えても適切にスケールしていくことが可能です(特にK-meansやDBSCANなど)。 - 多様な用途
クラスタリングは、マーケティング(顧客セグメント化)、異常検知(不良品検出)、生産ラインの最適化、需要予測など、さまざまな分野で活用されています。 - 距離に基づく分類
データポイント間の類似性を測るために距離(ユークリッド距離やマンハッタン距離など)を使用します。類似したデータは近い位置にあり、同じクラスタにまとめられます。 - 多様な用途
クラスタリングは、マーケティング(顧客セグメント化)、異常検知(不良品検出)、生産ラインの最適化、需要予測など、さまざまな分野で活用されています。
クラスタリングの目的
クラスタリングの目的は多岐にわたりますが、その中でも特に重要なのが、未知のパターンの発見と異常の検出です。
- 未知のパターンの発見
ラベルのないデータを分析することで、予期しないパターンや関係性を見つけることができます。 - 異常の検出
通常のデータから逸脱した異常なデータポイントを特定することができます。製造業などでは、この異常を検出して不良品の早期発見や工程改善に役立てることができます。
クラスタリングのメリットとデメリット
クラスタリングはデータ分析において強力な手法ですが、活用する際にはそのメリットとデメリットを理解しておくことが大切です。ここでは特に製造業におけるクラスタリングの活用を中心に、利点と課題を詳しく解説します。
メリット
- 高効率・高速処理
大規模なデータセットでも迅速に処理可能で、リアルタイムの分析にも対応できる。 - 前処理が少ない
データの前処理が簡単で、手間をかけずに分析を開始できる。 - ノンパラメトリック手法の活用
特定の分布に依存せず、さまざまなデータ構造に適応可能で汎用性が高い。 - スケーラビリティ
データ量が増加しても適応しやすく、大規模なデータでも高い精度でクラスタリングが可能。
デメリット
- 解釈性の低さ
クラスタリング結果が自動的に生成されるため、各クラスタの意味や異常の原因が分かりにくい場合がある。 - 高次元データへの弱さ
データの次元が多い場合、アルゴリズムの精度が低下する可能性がある。 - 外れ値の影響
外れ値の分布や種類によってクラスタリング結果に影響を及ぼし、検出精度が変動することがある。
クラスタリングに適したデータ
クラスタリングの効果を最大限に引き出すためには、適切なデータセットを用意することが重要です。クラスタリングに適したデータにはいくつかの条件があります。以下では、クラスタリングを成功させるためのデータの特徴について詳しく説明します。
- 十分なサンプル数があるデータ
クラスタリングは統計的な分析手法のため、データ数が少ないと信頼性の高い結果を得るのが難しくなります。適切な結果を得るには、十分なサンプル数が必要です。 - 特徴量が明確で多様性があるデータ
クラスタリングでは、データ間の類似性を計算するため、数値データやカテゴリデータなど、明確な特徴量が重要です。また、同じ特徴量が偏りすぎている場合、アルゴリズムの性能が低下する可能性があります。 - 異常値が適切に処理されているデータ
クラスタリングは外れ値(異常値)に敏感です。データに異常値が多く含まれる場合、結果が大きく歪む可能性があります。そのため、前処理として異常値の検出と適切な対応が必要です。 - スケーリングが行われたデータ
クラスタリングアルゴリズム(例: K-means法)は、距離ベースで計算を行います。そのため、データのスケール(単位や範囲)が異なる場合は、標準化や正規化を行い、すべての特徴量が均等に扱われるようにすることが重要です。 - 適度な次元のデータ
次元(特徴量の数)が高すぎると「次元の呪い」と呼ばれる問題が発生し、アルゴリズムの性能が低下します。適切な次元削減(主成分分析、t-SNEなど)を行うことで、効率的なクラスタリングが可能になります。
クラスタリングの製造業における用途
クラスタリングはデータの「類似性」に基づいて分類を行う手法です。この特性を活かすことで、製造業では以下のような場面で価値を発揮します。
- 不良品の検出
製品の品質データ(例:寸法、重量、硬さなど)をグループ化して異常なデータを見つけることで、不良品を早期に発見できます。この仕組みにより、無駄なコストを抑えつつ製造工程を改善できます。 - 生産ラインの最適化
設備の動作データを分析して、正常稼働と異常パターンを分類します。これにより、機械のメンテナンスを計画的に行い、生産効率を高めることができます。 - 在庫管理と需要予測
製品の需要や補充サイクルを分類して、在庫の過不足を防ぎます。これにより、必要な量だけを保管・補充する効率的な在庫管理が可能になります - 工程異常の早期発見
製造プロセスのデータを分析し、通常の動作と異なるパターンを検出します。これにより、異常が発生した際に早めの対策が可能になります。 - 顧客ニーズの分析
顧客データを分類することで、ニーズに応じた製品の提供やマーケティング施策の最適化ができます。
クラスタリングにおける3つの手法
ここでは、代表的な3つのクラスタリング手法、K-Meansクラスタリング、DBSCANクラスタリング、階層的クラスタリングについて解説します。
K-Meansクラスタリング
K-Meansクラスタリングは、最も広く利用されている非階層的クラスタリング手法です。
特徴
- クラスタ数の指定: あらかじめ分けるべきグループ数(K)を指定する必要があります。そのため、クラスタ数が事前に予測できる場合に適しています。
- 計算の効率: 高速な計算が可能で、大規模なデータセットにも適用可能です。
- クラスタの形状: 球状のクラスタに適しており、非線形の境界を持つデータには向いていません。
適用範囲: 均一に分布するデータや、クラスタ数が事前にわかっている場合に有効です。顧客のセグメンテーションや市場分析などに広く用いられます。

DBSCANクラスタリング
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)は、密度に基づいたクラスタリング手法です。
特徴
- クラスタ数の不要: クラスタ数を事前に設定する必要がなく、データの密度に応じて自動的にクラスタを形成します。
- 異常値の処理: ノイズや外れ値を「ノイズ」として扱い、クラスタから除外するため、外れ値処理が容易です。
- 密度ベースの手法: 異なる形状やサイズのクラスタを識別する能力があり、密度が不均一なデータに適しています。
適用範囲: クラスタ数が不明な場合や、異常値の検出が重要な場合に有効です。地理空間データや異常検知の分野で特に効果を発揮します。

階層的クラスタリング
階層的クラスタリングは、データを階層構造としてグループ化する手法です。特に凝集型(アグロメレティブ)アプローチが広く利用されています。
特徴
- デンドログラム: 階層構造を視覚的に表示できるデンドログラムを作成し、クラスタの結合や分割の過程を理解できます。
- クラスタ数の柔軟性: デンドログラムを任意の高さで切断することで、後からクラスタ数を決定できます。
- 距離計算の多様性: ユークリッド距離、マンハッタン距離、コサイン類似度など、さまざまな距離計算方法を採用可能です。
適用範囲: データの階層構造を詳細に把握したい場合や、比較的小規模なデータセットに適しています。遺伝子系統樹の解析やマーケティングデータの分析で活用されます。
手法選択のポイント
クラスタリングにおける3つの手法と、それぞれの手法を選択すべき状況をまとめておきます。
それぞれ得意不得意があるため、選定の際の参考にしてください。
| 手法 | 主な特徴 | 適用範囲 |
|---|---|---|
| K-Means | クラスタ数を事前に指定、高速計算、球状のクラスタ向け | 均一に分布するデータ、クラスタ数が既知のケース |
| DBSCAN | 密度ベース、外れ値処理が容易、非線形クラスタの識別が可能 | クラスタ数が不明な場合、異常値検出が必要なデータ |
| 階層的クラスタリング | デンドログラムで階層構造を視覚化、後からクラスタ数を決定可能 | 小規模データ、階層構造の分析が求められるケース |
データの準備と前処理
クラスタリングアルゴリズムを適用する前に、データの前処理が重要です。製造業のデータには欠損値や異常値が含まれている場合が多いため、適切に処理する必要があります。
ここでは、クラスタリングでよく使われる前処理について紹介します。
データの正規化
製造ラインのセンサーデータや品質データなどは、スケールが異なることが多いため、データの正規化(標準化)が必要です。これにより、すべての特徴量が同じスケールで比較されるようになります。以下は正規化の例です。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data_normalized = scaler.fit_transform(data)次元削減
高次元のデータを扱う場合、次元削減を行うことで計算負荷を減らし、可視化もしやすくなります。主成分分析(PCA)を使って2次元や3次元に変換した結果をクラスタリングすれば、簡単に可視化できるようになります。
from sklearn.decomposition import PCA
pca = PCA(n_components=2) # 2次元に削減
data_reduced = pca.fit_transform(data_normalized)ノイズ処理
クラスタリングアルゴリズムにおいては、ノイズが結果に大きな影響を与えることがあります。外れ値を除去するために、データのクレンジングを行いましょう。
import numpy as np
# 標準偏差を使って外れ値を検出し、データから削除する
data_cleaned = data[np.abs(data - np.mean(data)) <= 3 * np.std(data)]まとめ
クラスタリングは、膨大なデータの中からパターンを見つけ出し、データを効果的に活用するための強力なツールです。教師無し学習の一種として、事前のラベルが不要でありながら、データの構造を明らかにし、新たな洞察を得ることができます。
製造業では、不良品の検出、生産ラインの最適化、需要予測など、幅広い用途でその価値が発揮されています。また、K-Means、DBSCAN、階層的クラスタリングといった代表的な手法は、それぞれ異なる特性を持ち、データの性質や分析目的に応じて選択が可能です。
一方で、クラスタリングには解釈性の難しさや高次元データへの弱さなどの課題もあります。これらを克服するためには、適切な前処理やデータ選定、次元削減技術の活用が鍵となります。
データ分析の現場でクラスタリングを活用することで、より深い洞察を得るだけでなく、効率的な業務改善や意思決定の迅速化にもつながるでしょう。この記事が、クラスタリングの基本を理解し、実践に活かすための一助となれば幸いです。








コメント