近年、自動車や建設機械、農業機械などの車両に通信ユニットを搭載し、位置情報を収集して製品企画やメンテナンスに活用する取り組みが広がっています。
たとえば、トラクターの軌跡データから圃場(ほじょう)の面積を算出したり、建設機械の作業範囲を分析したりすることが可能です。これらの車両が特定の作業を行う際には、GPSデータの密集箇所が発生することが多いです。このような密集箇所をうまく分類・特定できれば、さらなる詳細なデータ分析や有益なインサイトの抽出が容易になります。
そこで本記事では、GPSの軌跡データをDBSCAN(Density-Based Spatial Clustering of Applications with Noise)アルゴリズムを用いてクラスタリングし、データを分割・分析する方法について解説します。
GPSデータとDBSCANの活用について
GPSデータの課題
現代のモビリティ社会において、GPSデータは欠かせない存在です。自動車や建設機械、農業機械などに搭載された通信ユニットから取得されるGPSデータは、単なる位置情報にとどまらず、製品の改善や効率化のヒントを与える重要なデータ源となっています。たとえば、次のような活用が考えられます:
- 農業:農機の走行軌跡から圃場の面積を自動算出し、作業効率を可視化。
- 建設:建機の作業エリアを分析し、無駄のない稼働をサポート。
- 物流:配送ルートの最適化や、リアルタイムでの車両追跡。
これらの事例からもわかる通り、GPSデータを適切に処理・分析することが、業務の効率化やコスト削減に直結します。
しかし、実際のGPSデータには課題があります。
- ノイズの存在:GPSの受信状態が悪いと、不正確な位置情報が含まれてしまう。
- 膨大なデータ量:継続的に記録されるため、着目したい場所と無関係なデータも多数含まれてしまう。
- 構造化されていない:経路やパターンを簡単に理解できる形になっていない。
これらの課題を解決するための手法として、DBSCAN(Density-Based Spatial Clustering of Applications with Noise)が活用できます。
DBSCANとは
DBSCANは、密度に基づいてデータをクラスタリングするアルゴリズムです。通常のクラスタリング手法ではうまく処理できないノイズや異常値を自動的に除外し、密集している部分だけをグループ化することが特徴です。特にGPSデータとの相性が良く、次のような用途に活用できます。
- 作業エリアの特定:GPSデータの密集部分をグループ化し、作業範囲や重要な地点を抽出。
- 経路の分類:移動経路をクラスタリングして、どの経路が頻繁に使用されているかを分析。
- 異常検知:通常の移動範囲から外れたノイズや異常なパターンを除外。
より詳しい情報は「【Python実践】DBSCANでデータのグルーピングを行う(コピペで使えるサンプルコード付き)」をご一読ください。

GPSデータにおけるDBSCANの活用手順
GPSデータにDBSCANを適用するには、次の手順を踏みます。
- データ準備:経緯度や時刻を含むデータを整える。
- 前処理:ノイズとなるデータ(例:緯度や経度が0の値など)を除去する。
- クラスタリング:DBSCANを使用して、密集領域をグループ化。
- 結果の可視化:クラスタごとの軌跡をプロットして確認。
使用するCSVデータの概要
今回のプログラムで使用するGPSのテストデータです。プロットが4か所に分布しています。gpsdata.csv という名前でファイルに保存してご利用下さい。
OCCURRED_DATETIME,LATITUDE,LONGITUDE
2020/11/25 10:08,35.1763883,136.7141533
2020/11/25 10:09,35.1763833,136.7140683
2020/11/25 10:10,35.1763066,136.7137566
2020/11/25 10:11,35.1760666,136.7138033
2020/11/25 10:12,35.1759416,136.71384
2020/11/25 10:13,35.1760216,136.7141983
2020/11/25 10:14,35.176345,136.714125
2020/11/25 10:15,35.1763166,136.713835
2020/11/25 10:16,35.1759616,136.713845
2020/11/25 10:17,35.1759383,136.7140883
2020/11/25 10:18,35.1760949,136.71418
2020/11/25 10:19,35.1760633,136.7142133
2020/11/25 10:38,35.17611,136.7138416
2020/11/25 10:39,35.1759683,136.7140433
2020/11/25 10:40,35.1761116,136.7141466
2020/11/25 10:41,35.1763133,136.7141016
2020/11/25 10:50,35.1761966,136.7138466
2020/11/25 10:51,35.1759616,136.7139483
2020/11/25 10:52,35.1763333,136.7140766
2020/11/25 10:53,35.1761233,136.713875
2020/11/25 10:54,35.1760266,136.71411
2020/11/25 10:55,35.1762283,136.7140766
2020/11/25 10:56,35.1762633,136.7138816
2020/11/25 11:25,35.1761449,136.71406
2020/11/25 11:27,35.17629,136.71391
2020/11/25 11:28,35.1759683,136.71406
2020/11/25 11:29,35.1762816,136.7140099
2020/11/25 11:30,35.1762166,136.7139483
2020/11/25 11:31,35.1759649,136.7140416
2020/11/25 11:32,35.1759649,136.7140416
2020/11/25 12:05,35.1763149,136.7138633
2020/11/25 12:06,35.1763149,136.7138633
2020/11/25 12:07,35.1763833,136.7140683
2020/11/25 13:43,35.176455,136.7141733
2020/11/25 11:56,35.1762033,136.71399
2020/11/25 11:57,35.1761133,136.7139733
2020/11/25 12:17,35.1763533,136.7139116
2020/11/25 12:18,35.1763516,136.7139116
2020/11/25 12:19,35.176345,136.713935
2020/11/25 12:20,35.176345,136.713935
2020/11/25 11:15,35.1759499,136.7140316
2020/11/25 11:16,35.1760366,136.714105
2020/11/25 11:18,35.1760483,136.7140666
2020/11/25 11:19,35.1760133,136.7140666
2020/11/25 11:20,35.1760416,136.7140849
2020/11/25 11:21,35.1763099,136.7140283
2020/11/25 11:22,35.1762783,136.7138766
2020/11/25 11:23,35.17621,136.7138966
2020/11/25 15:01,35.177455,136.7137083
2020/11/25 15:02,35.1776033,136.7136883
2020/11/25 15:03,35.1776166,136.7136883
2020/11/25 15:04,35.1774433,136.7137783
2020/11/25 15:05,35.1775916,136.7138016
2020/11/25 15:06,35.1776033,136.7136499
2020/11/25 15:07,35.1775933,136.713855
2020/11/25 15:08,35.1773683,136.7139199
2020/11/25 15:09,35.1771699,136.7138516
2020/11/25 14:58,35.1773849,136.7137016
2020/11/25 14:59,35.1775483,136.7138716
2020/11/25 15:00,35.1776099,136.7137266
2020/11/25 15:11,35.17733,136.7138416
2020/11/25 15:12,35.1772883,136.7139083
2020/11/25 15:14,35.1773433,136.7138499
2020/11/25 15:15,35.1773716,136.7138566
2020/11/25 15:16,35.1773716,136.7138566
2020/11/25 14:51,35.1774633,136.7134016
2020/11/25 14:53,35.1774116,136.7133516
2020/11/25 14:54,35.1775533,136.7134516
2020/11/25 14:55,35.17741,136.713395
2020/11/25 14:56,35.1774183,136.7134383
2020/11/25 16:04,35.1772149,136.7131649
2020/11/25 16:05,35.1772149,136.7131649
2020/11/25 16:06,35.1771266,136.71319
2020/11/25 16:07,35.1769399,136.71324
2020/11/25 16:08,35.1768933,136.7133533
2020/11/25 16:09,35.1770733,136.7133633
2020/11/25 16:10,35.17729,136.7132333
2020/11/25 16:11,35.17729,136.7132333
2020/11/25 16:12,35.1769466,136.7132733
2020/11/25 16:13,35.1769366,136.7132716
2020/11/25 16:14,35.1769416,136.7133733
2020/11/25 16:15,35.1772933,136.7132416
2020/11/25 16:16,35.17716,136.7132433
2020/11/25 16:17,35.17689,136.7133183
2020/11/25 16:18,35.17689,136.7133183
2020/11/25 16:19,35.17713,136.7133099
2020/11/25 16:20,35.1772916,136.7132649
2020/11/25 16:21,35.1771733,136.7132616
2020/11/25 16:22,35.1769166,136.7133249
2020/11/25 16:23,35.1772316,136.7132749
2020/11/25 16:24,35.1772516,136.7131949
2020/11/25 16:25,35.1772516,136.7131949
2020/11/25 16:26,35.1772516,136.7131949
2020/11/25 16:27,35.1772516,136.7131949
2020/11/25 14:18,35.1770333,136.7116233
2020/11/25 14:19,35.1770883,136.7115166
2020/11/25 14:20,35.176975,136.7116283
2020/11/25 14:24,35.1771016,136.7115399
2020/11/25 14:25,35.1771,136.7115683
2020/11/25 14:26,35.1771,136.7115683
2020/11/25 14:27,35.1771183,136.7114066
2020/11/25 14:21,35.1769316,136.711605
2020/11/25 14:12,35.1772133,136.7114683
2020/11/25 14:13,35.177095,136.7114133
2020/11/25 14:14,35.1769483,136.7115166
2020/11/25 14:15,35.1769283,136.7115766
2020/11/25 14:16,35.17705,136.7116416
2020/11/25 14:17,35.1770716,136.7114933
2020/11/25 14:01,35.1770816,136.7112799
2020/11/25 14:02,35.1771766,136.7115099
2020/11/25 14:03,35.1774016,136.7114533
2020/11/25 14:05,35.1772666,136.7113516
2020/11/25 14:06,35.1771866,136.7114916
2020/11/25 14:09,35.1772083,136.7114416GPS軌跡をGeoPandas可視化について
GPSデータの可視化は、位置情報を活用する上で欠かせないプロセスです。「【Python実践】DBSCANでGPS位置情報をクラスタリングする(コピペで使えるサンプルコード付き)」の記事では、folimu というライブラリを使って地図上に軌跡をプロットしました。

今回はプロットの軌跡パターンや密集具合が分かればよいので、軌跡を高速に可視化できる geopandas を使います。
GeoPandasとは
GeoPandasは、地理空間データ(緯度や経度を持つデータ)を扱うために設計されたPythonライブラリです。通常のPandasに地理情報システム(GIS)機能を組み込んだ形で、次のような特徴があります:
- 空間データの操作:ポイント、ライン、ポリゴンなどの地理情報を簡単に扱える。
- 豊富な可視化機能:地理空間データをマップ上にプロット可能。
- 他ライブラリとの連携:ShapelyやMatplotlibと連携して高度な解析やカスタマイズも可能。
GeoPandasを使うことで、例えば以下のようなタスクが簡単になります:
- 緯度・経度情報を操作してデータを解析する。
- GPSデータから移動軌跡を描画する。
- 都市や地域ごとのデータを地図に重ね合わせる。
GeoPandasのインストール方法
GeoPandas を使う場合は、下記コマンドでインストールして下さい。
pip install geopandas
GPS軌跡データを可視化する
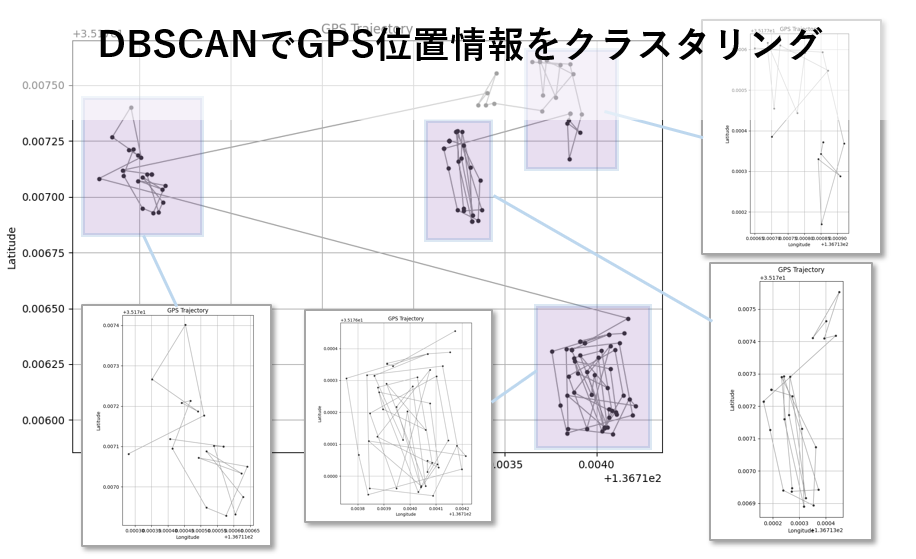
GeoPandasを使って gpsdata.csv を可視化すると、下記の画像が表示されます。
可視化が簡単に行えるようplot_trajectoryという名前で関数化しました。引数にタイムスタンプを指定しているのは、時系列に並べる為です。
また、緯度経度のどちらかが0のデータについては関数内部で削除しています。
import pandas as pd
import geopandas as gpd
from shapely.geometry import LineString, Point
import matplotlib.pyplot as plt
def plot_trajectory(df, time_col, lat_col, lon_col):
"""
GPSデータを線と点でプロットする関数
Args:
df (pd.DataFrame): DataFrame
time_col (str): 時刻のカラム名
lat_col (str): 緯度のカラム名
lon_col (str): 経度のカラム名
"""
# 緯度または経度が 0 またはNaNである行を除外
df = df[(df[lat_col] != 0) & (df[lon_col] != 0) & df[lat_col].notna() & df[lon_col].notna()]
# df が空なら抜ける
if len(df) == 0:
return
# 時系列順にソート
df = df.sort_values(by=time_col)
# 点のジオメトリを作成
point_geometry = gpd.points_from_xy(df[lon_col], df[lat_col])
point_gdf = gpd.GeoDataFrame(geometry=point_geometry, crs="EPSG:4326")
# 線のジオメトリを作成
line_geometry = LineString(list(zip(df[lon_col], df[lat_col])))
line_gdf = gpd.GeoDataFrame(geometry=[line_geometry], crs="EPSG:4326")
# プロット
fig, ax = plt.subplots(figsize=(10, 8))
# 線のプロット
line_gdf.plot(ax=ax, color='#999999', linewidth=1, zorder=1)
# 点のプロット
point_gdf.plot(ax=ax, color='#333333', marker='o', markersize=10, zorder=2)
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.title('GPS Trajectory')
plt.grid()
plt.show()
if __name__ == "__main__":
# CSVファイルを読み込む(パスはご自身の環境のものと置き換えて下さい)
df = pd.read_csv("p:/gpsdata.csv", parse_dates=["OCCURRED_DATETIME"])
# プロット関数を実行
plot_trajectory(df, "OCCURRED_DATETIME", "LATITUDE", "LONGITUDE")GPSデータをDBSCANでクラスタリングする
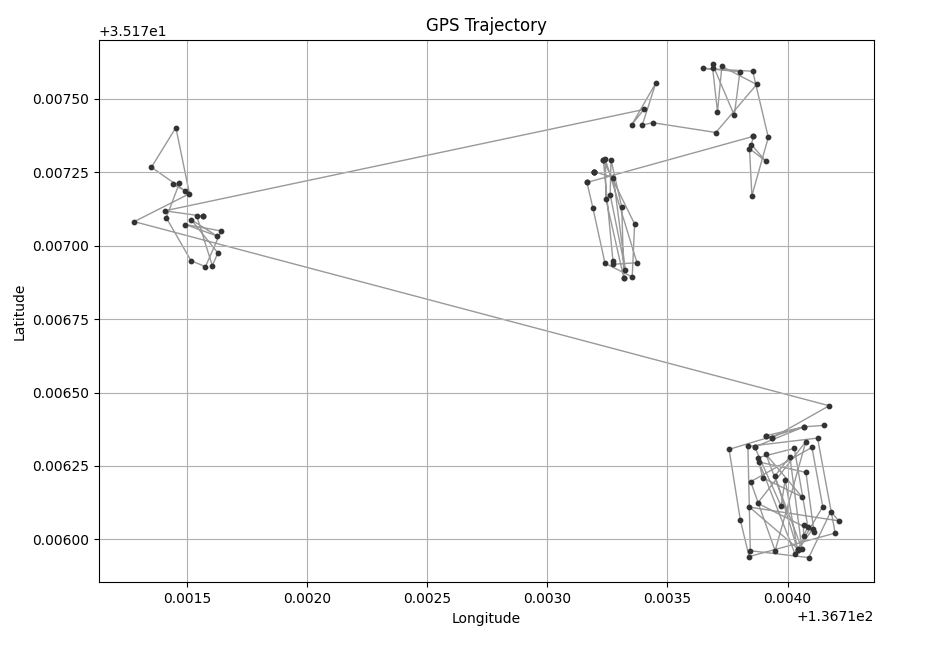
DBSCANでクラスタリングした結果、期待通り4つのクラスターとして分類できました。
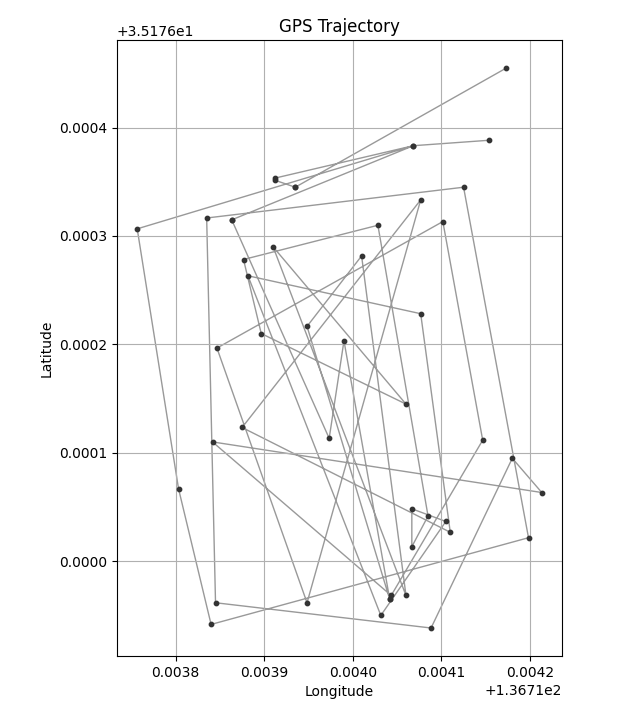
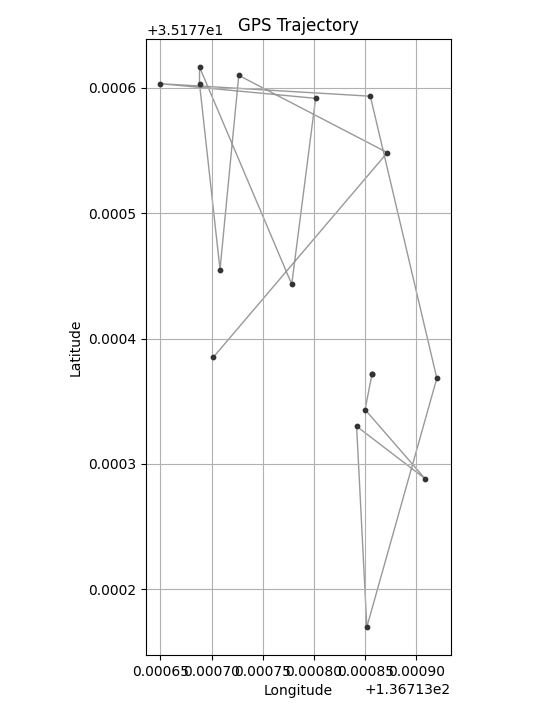
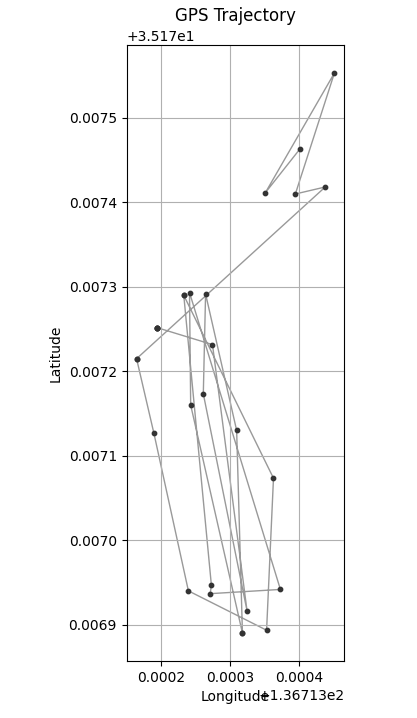
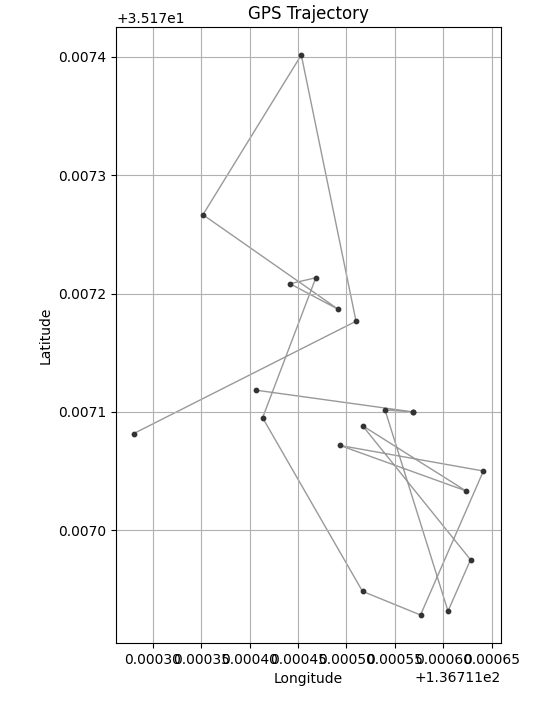
GPSデータをクラスタリングするために、extract_by_dbscanという名前で関数を作成しました。
引数に時刻、緯度、経度を格納したDataFrameと、DBSCANのハイパーパラメータである eps,min_samples を指定します。
extract_by_dbscan(データフレーム, 緯度のカラム名,経度のカラム名, eps, min_samples)
| eps(ε) | データポイントが同じクラスタに属すると見なす最大距離。 |
|---|---|
| min_samples | あるデータポイントをコアポイントと見なすために必要な最小データポイント数。 |
今回は eps=0.0002、min_samples=10を指定しています。状況に応じて適宜変更して下さい。
下記のプログラムを実行する場合は、前述のplot_trajectoryが必要です。
# ------------------------------------------------------------
# ここに前述の plot_trajectory 関数のソースを張り付けて下さい。
# ------------------------------------------------------------
from sklearn.cluster import DBSCAN
import numpy as np
def extract_by_dbscan(df, time_col, lat_col, lon_col, eps, min_samples):
"""
DBSCANでクラスタリングを行い、各クラスタを通常のDataFrameのリストで返す関数
Args:
df (pd.DataFrame): DataFrame
time_col (str): 時刻のカラム名
lat_col (str): 緯度のカラム名
lon_col (str): 経度のカラム名
eps (float): DBSCANのepsパラメータ
min_samples (int): DBSCANのmin_samplesパラメータ
Returns:
list: 各クラスタのDataFrameのリスト
"""
# 緯度経度のNumPy配列を作成
coords = np.column_stack((df[lon_col], df[lat_col]))
# DBSCANでクラスタリング
clustering = DBSCAN(eps=eps, min_samples=min_samples).fit(coords)
df['cluster'] = clustering.labels_
# クラスタごとにDataFrameを作成
trajectory_dfs = []
for cluster_label in np.unique(clustering.labels_):
if cluster_label != -1: # ノイズを除外
cluster_df = df[df['cluster'] == cluster_label]
trajectory_dfs.append(cluster_df)
return trajectory_dfs
if __name__ == "__main__":
# CSVファイルを読み込む(パスはご自身の環境のものと置き換えて下さい)
df = pd.read_csv("p:/gpsdata.csv", parse_dates=["TIMESTAMP"])
# DBSCANでクラスタリングする
trajectory_dfs = extract_by_dbscan(df, 'LATITUDE', 'LONGITUDE', 0.0002, 10)
for df in trajectory_dfs:
# プロット関数を実行
plot_trajectory(df, "TIMESTAMP", "LATITUDE", "LONGITUDE")まとめ
本記事では、GPS位置情報をDBSCANアルゴリズムを用いてクラスタリングする方法について解説しました。GPSデータは現代のさまざまな分野で活用されており、その分析結果は効率的な作業やコスト削減に直結します。
DBSCANは、密度ベースでデータをクラスタリングし、ノイズや異常値を取り除くのに優れた手法です。そのため、GPSデータのようにノイズが含まれやすく、密集部分の検出が重要なデータセットにおいて非常に有用です。
皆さんのデータ分析において、GPSの軌跡データを分析する際に、この記事が参考になれば幸いです。








コメント