
ディープラーニングの進化とともに、より効率的な学習手法が求められています。そこで登場するのが「転移学習」「追加学習」「ファインチューニング」といったモデルの強化手法です。これらは、すでに学習済みのモデルを活用して、新しいタスクへの適応や性能向上を図るための重要な技術です。
本記事では、それぞれの手法の特徴と違いを詳しく解説し、どのような場面で使い分けるべきかを解説します。
転移学習、追加学習、ファインチューニングの違いがよく分からない方、あるいはどれを使えば良いか迷っている方は、是非参考にしてください。
転移学習・追加学習・ファインチューニングの概要
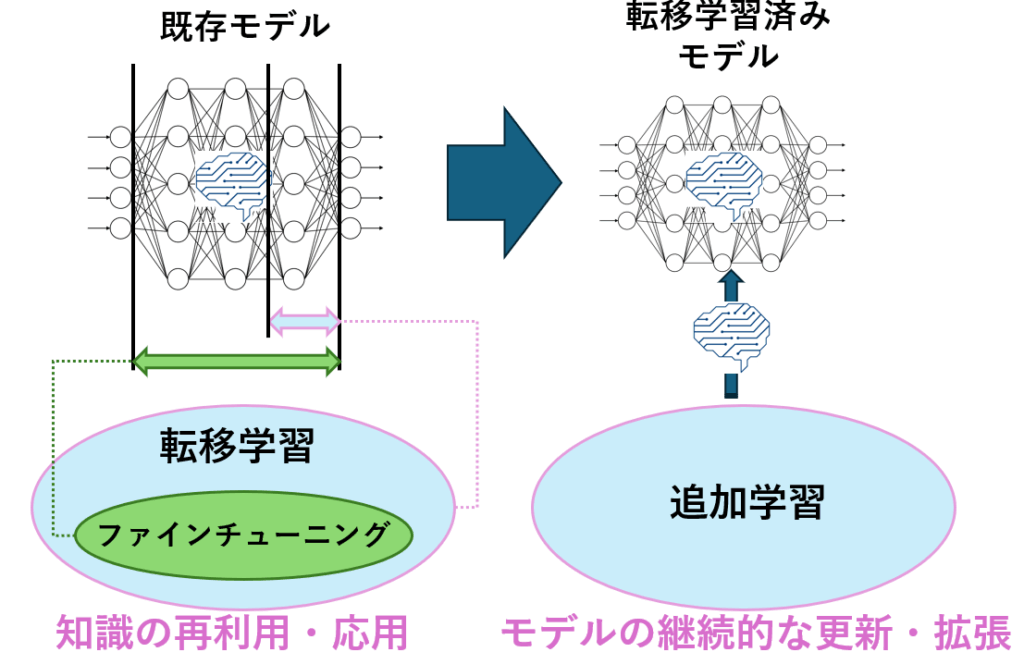
転移学習は、ある領域で得た知識を別の領域に役立てるという、より広い概念です。その具体的な実現方法の一つとしてファインチューニングがあります。
ファインチューニングは、事前学習済みモデルの重みを初期値として、ターゲットタスクのデータで再学習(重みの微調整)を行うことで、効率的に高い精度を目指します。
追加学習は、モデルを一度学習させて終わりではなく、新しいデータが手に入るたびに継続的に学習を続けることに主眼を置いています。既存の知識を忘れないように(破綻的忘却を防ぐ)工夫が必要になる場合もあります。
| 手法 | 概要 | 目的 | 学習対象の層 |
|---|---|---|---|
| 転移学習(Transfer Learning) | 学習済みのモデルを、別の関連するタスクに応用 | タスクの学習効率向上(少量、短時間での学習) | 手法による(特徴抽出器として固定する場合や、ファインチューニングする場合がある) |
| ファインチューニング(Fine-tuning) | 学習済みモデル一部または全体を再学習 | 既存モデルをターゲットタスクに特化、精度向上 | 主に出力層に近い層、またはモデル全体の重みを微調整(初期層を固定する場合もある) |
| 追加学習(Incremental Learning) | 既存モデルに新しいデータを加えて継続的に学習 | モデルの知識を維持しつつ、新しいデータに対応・知識を更新・拡張する | モデル全体または一部の層(新しいクラス追加時は出力層の構造変更も) |
転移学習(Transfer Learning)とは
転移学習(Transfer Learning)は、既存の学習済みモデルの知識を活かして、新しいタスクに適応させる手法です。通常、ディープラーニングモデルをゼロから学習させるには大量のデータと計算リソースが必要ですが、転移学習を利用すると、少量のデータで高い精度を達成できます。
転移学習の種類
転移学習にはいくつかのアプローチがあります。
特徴抽出 → モデルの知識をそのまま活用し、新しい分類層のみ学習するので計算コストが低い。
ファインチューニング → 一部の層を再学習して特定のタスクに最適化する。
ドメイン適応 → 異なるデータ分布にモデル全体を適応させる。
| アプローチ | 手順 | 目的 | 調整範囲 |
|---|---|---|---|
| 特徴抽出(Feature Extraction) | ① 事前学習モデルをロード ② 最終出力層を変更 ③ 低レベルの層を固定(学習しない) ④ 新しい分類器のみ学習 | モデルの事前学習済み特徴をそのまま活用 | 最終分類層のみ学習 |
| ファインチューニング(Fine-tuning) | ① 事前学習モデルをロード ② 最終出力層を変更 ③ 低レベルの層を選択的に学習 ④ 高レベルの層を再学習 | 事前学習モデルの特徴を活かしつつ、特定のタスクに最適化 | 高レベル層+一部の低レベル層を学習 |
| ドメイン適応(Domain Adaptation) | ① 事前学習モデルをロード ② 新しいデータセットに適応 ③ 特定のデータ分布に合わせて全層調整 | 異なるデータ分布間でモデルを調整 | 全層を再学習 |
転移学習の手順
大規模データセットで事前学習された汎用的なモデルを、特定のタスクにカスタマイズしたい場合に適しているため、多くの実用的なAIシステムで採用されています。以下の手順に沿って、転移学習を適用していきます。
- 事前学習モデルの読み込み(例えば、ResNet・BERT など)
- 出力層を変更(新しいタスク向けに最適化)
- 固定する層を選択(一部の層を再学習)
- 新しいデータセットで学習
- 精度評価と調整
転移学習のサンプルソース
このコードは、事前学習済みのResNet18モデルを利用し、新しい5クラス分類タスクに適用する転移学習の例です。転移学習では、すでに学習されたモデルの知識を活用し、一部の層を調整することで、新しいデータに適応させることができます。
import torch
import torch.nn as nn
import torchvision.models as models
# 事前学習済みモデルをロード
model = models.resnet18(pretrained=True)
# 出力層を変更(例えば5クラス分類)
model.fc = nn.Linear(model.fc.in_features, 5)
# 一部の層だけ学習可能に(特徴抽出層は固定)
for param in model.parameters():
param.requires_grad = False
for param in model.fc.parameters():
param.requires_grad = True
# モデル保存
torch.save(model.state_dict(), 'transfer_learning_model.pth')転移学習のポイント
ファインチューニング(Fine-tuning)とは
ファインチューニング(Fine-tuning)とは、事前学習済みのモデルの一部または全体を調整し、新しいタスクやデータセットに最適化する手法です。これは転移学習の一種であり、既存のモデルを活用しながら、特定の用途に向けた微調整を行うことで、性能を向上させることができます。
ディープラーニングモデルの学習には大量のデータと計算コストが必要ですが、ファインチューニングを活用することで、少量のデータでも高い精度を達成できるという利点があります。特に、特定の業界や用途に適応させる際に有効です。
ファインチューニングの手順
ファインチューニングでは、事前学習済みのモデルを基にして、一部の層を再学習することで最適化します。これにより、既存のモデルの知識を活かしつつ、新しいデータに適応することが可能になります。
- 事前学習済みモデルの読み込み(例えば、BERTやResNetなど)
- 一部の層をフリーズ(固定)し、高レベルの層のみ再学習
- 新しいデータセットを使用してモデルを訓練
- 精度向上のためのハイパーパラメータ調整
- 最終的な評価とテスト
ファインチューニングのサンプルソース
このコードは、ResNet18をファインチューニングし、新しい2クラス分類タスクに適応するためのシンプルな例です。ファインチューニングでは、事前学習済みのモデルを活用しながら、特定のデータに最適化するため、精度向上が期待できます。
import torch
import torch.nn as nn
import torchvision.models as models
# 事前学習済みモデルをロード
model = models.resnet18(pretrained=True)
# 出力層を変更(例えば2クラス分類)
model.fc = nn.Linear(model.fc.in_features, 2)
# すべての層を学習可能に
for param in model.parameters():
param.requires_grad = True
# モデル保存
torch.save(model.state_dict(), 'fine_tuned_model.pth')追加学習(Incremental Learning)とは
追加学習(Incremental Learning)は、既存のモデルに新しい知識を継続的に追加しながら学習する手法です。特に コンティニュアルラーニング(Continual Learning) の一部として、過去に学習した内容を保持しつつ、新しいデータを組み込む ことができます。
追加学習の手順
追加学習では、モデルを最初から再学習するのではなく、これまでの学習を維持しながらアップデートを行うため、リソースの消費を抑えつつ、柔軟な適応が可能になります。以下の手順に沿って、追加学習のプロセスを実施していきます。
- 新しいデータを追加
モデルに新しい情報を組み込むため、新しいデータセットを用意し、適切な形式で取り込む。 - 過去の知識を維持しながら再学習
既存の学習済み情報を活かしつつ、新しいデータを追加学習することで、モデルの知識を拡張する。 - モデルの評価
追加学習後のモデルをテストし、新しいタスクに適応できているか検証する。 - 継続的にアップデート
新しいデータが追加されるたびに学習を繰り返し、モデルを常に最新の状態に保つ。
追加学習のサンプルコード
このコードは、ResNet18モデルに新しい分類クラスを追加し、段階的に適応させる追加学習(Incremental Learning)の例です。追加学習では、既存のモデルの知識を保持しながら、新しいデータに適応できるため、継続的にモデルを進化させることができます。
import torch
import torch.nn as nn
import torchvision.models as models
# 既存のモデルをロード
model = models.resnet18(pretrained=True)
model.fc = nn.Linear(model.fc.in_features, 3) # 既存タスク
# 追加学習用に新しいデータを加える
new_output_layer = nn.Linear(model.fc.in_features, 5) # 3→5クラス分類へ拡張
model.fc = new_output_layer
# モデル保存
torch.save(model.state_dict(), 'incremental_learning_model.pth')
まとめ
この記事では、転移学習・追加学習・ファインチューニングの概要と、それぞれの特徴や違いについて解説しました。これらの手法は、既存の学習済みモデルを活用し、新しいタスクに適応させるための重要な技術です。
- 転移学習 は、事前学習済みモデルの特徴抽出能力を活かし、新しい分類タスクに適用することで、計算コストを抑えながら高精度な予測が可能。
- 追加学習 は、過去の知識を保持しつつ、新しいデータを継続的に追加することで、モデルを進化させながら適応力を向上。
- ファインチューニング は、事前学習済みモデルの一部または全体を調整し、特定の用途に最適化することで、精度をさらに向上。
これらの手法を適切に選び、組み合わせることで、少量のデータでも高性能なモデルを構築できるほか、時間とともに変化するタスクにも対応可能となります。特定の目的に応じて、最適な学習戦略を選択し、より効率的なAI開発を進めることができます。








コメント