
「【Python実践】OpenCV×SIFTで画像分類!特徴量を活かした分析手法(コピペで使えるサンプルコード付き)」の記記事では、スケールや回転に強い特徴点検出手法であるSIFT(Scale-Invariant Feature Transform)を活用した画像分類についてご紹介しました。しかし、SIFTとクラスタリング、あるいはBoVW(Bag-of-Visual-Words)と組み合わせたクラスタリングによる分類において、画素数が少なく単純で類似性の高い画像では、抽出された特徴量の差が少なく、結果として分類精度が十分ではありませんでした。
そこで本記事では、さらなる高精度な画像分類を目指し、近年著しい成果を上げている深層学習技術、特にCNN(Convolutional Neural Network:畳み込みニューラルネットワーク)と非教師あり学習であるクラスタリングを組み合わせた新たなアプローチをご紹介します。
以前のSIFTによる分類の経験を踏まえ、CNNとクラスタリングがどのように異なる結果をもたらすのか、その可能性をサンプルコードを通じてぜひお試しください。
CNNとは

CNN(convolutional neural network = 畳み込みニューラルネットワーク)は、画像認識をはじめとする様々な分野で目覚ましい成果を上げている、画像処理に特化した深層学習のモデルです。人間の視覚野の仕組みを一部模倣しており、画像の特徴を効率的に捉えることができるように設計されています。
主な特徴としては、以下の点が挙げられます。
- 畳み込み層(Convolutional Layer)
画像の小さな領域(フィルタ)をスライドさせながら、その領域の特徴を抽出します。これにより、エッジや角、テクスチャといった基本的な視覚的パターンを検出できます。 - プーリング層(Pooling Layer)
畳み込み層で得られた特徴マップのサイズを縮小し、位置ずれに対するロバスト性を高めます。重要な特徴を残しつつ、計算量を減らす役割もあります。 - 活性化関数(Activation Function)
畳み込み層や全結合層の出力に対して非線形な変換を行い、モデルがより複雑なパターンを学習できるようにします。ReLUなどがよく使われます。 - 全結合層(Fully Connected Layer)
畳み込み層やプーリング層で抽出された特徴量を統合し、最終的な分類や回帰などのタスクを実行します。従来のニューラルネットワークと同様の構造です。
CNNによる画像の特徴量抽出
モジュールのインストール
CNNを使った画像の特徴量抽出を行うには、torch、torchvision、Pillowのモジュールのインストールが必要です。
pip install torch torchvision Pillow opencv-python
学習済みモデルのダウンロード
CNNには、用途ごとに改良された多くのパターン(アルゴリズム)が存在し、学習済みモデルが公開されています。
今回は、特徴抽出のデモンストレーションとして、比較的小規模で扱いやすく、基本的な画像の特徴を捉えるのに適した「ResNet18」を採用しました。
モデルのダウンロードは非常に簡単で、models.resnet18を使ってモデルのインスタンスを生成するだけです。
これにより、必要なモデルが自動的にダウンロードされます。
また、モデルのインスタンスを生成した直後に、eval をコールして推論モードに設定しておきます。
import torchvision.models as models
model = models.resnet18(pretrained=True)
model.eval() # 推論モードに設定
参考までに、よく使われるCNN(一部抜粋)の一覧を掲載しておきます。
| モデル名 | 発表 | 特徴 | ダウンロード関数 |
|---|---|---|---|
| LeNet-5 | 1998 | CNNの初期の成功例、手書き文字認識 | (直接的な関数なし、自分で実装することが多い) |
| AlexNet | 2012 | 深層学習再興のきっかけ、ReLU、Dropout、MaxPooling | models.alexnet(pretrained=True) |
| VGG16 | 2014 | 小さな3x3フィルタを深く積層 | models.vgg16(pretrained=True) |
| GoogLeNet (Inception v1) | 2014 | Inceptionモジュールによる並列畳み込み | models.googlenet(pretrained=True) |
| ResNet18 | 2015 | 残差接続による深いネットワークの学習 | models.resnet18(pretrained=True) |
| ResNet50 | 2015 | ResNetの深いバリアント | models.resnet50(pretrained=True) |
| MobileNetV2 | 2017 | モバイルデバイス向け軽量モデル、Depthwise Separable Convolution | models.mobilenet_v2(pretrained=True) |
| EfficientNet-B0 | 2019 | 幅、深さ、解像度のバランス良いスケーリング | models.efficientnet_b0(pretrained=True) |
画像の前処理
CNNで特徴抽出するためには、画像の前処理が必要です。この時に問題となるのが、transforms.Composeに渡すパラメータの値です。これは状況に応じて変更が必要ですが、詳しくはChatGPTやGeminiなどの生成AIに指示すれば、適切な回答が得られると思います。
今回の様に、画像のサイズが244より大きく、かつ画像全体から特徴量を抽出する場合は、このままの値でも問題ありません。
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
image = Image.open(image_path).convert('RGB')
img_tensor = transform(image).unsqueeze(0)
| メソッド名 | 引数・パラメータ | 説明 |
|---|---|---|
| Resize | 256 | 画像の短辺を256ピクセルにリサイズ(縦横比は保持) |
| CenterCrop | 224 | 画像の中心から224×224の領域を切り抜き ※多くの学習済みモデルが224x224の入力サイズを想定 |
| ToTensor | なし | 画像をPyTorchのテンソル形式に変換(値を[0,1]にスケーリング) ※PyTorchで数値計算を行うための基本的なデータ構造 |
| Normalize | mean=[0.485, 0.456, 0.406] std=[0.229, 0.224, 0.225] | 各チャンネル(RGB)を正規化(平均を引き、標準偏差で割る) ※学習時のデータ分布に近づけることで、性能を安定させるため |
| unsqueeze(0) | dim=0 | テンソルの先頭にバッチ次元を追加([C, H, W] → [1, C, H, W]) |
特徴量の抽出
特徴量抽出は、学習済みのモデル(feature_extractor)に画像データを入力するとで実現できます。この時、with torch.no_grad() を呼び出して、学習時に使われる勾配の計算など、特徴量抽出に関係のない処理を行わせないようにしています。
そして、torch.mean を用いたグローバル平均プーリングにより、画像全体の特徴を集約した固定長のベクトルが得られ、これがクラスタリングのインプットとなる特徴量となります。
with torch.no_grad():
features = feature_extractor(img_tensor)
# グローバル平均プーリングを適用して1次元ベクトルに
features_flat = torch.mean(features, dim=(-1, -2)).flatten()
CNNを使った特徴量抽出のサンプルプログラム全体
これまでに説明した内容を組み立てていくと、最終的に次のサンプルになります。
import torch
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
# 画像ファイルのパスを指定してください
image_path = r"D:\図面分類\logo\kubota_white.png" # <--- ここに実際のパスを入力してください
# 1. 学習済みモデルのロード
model = models.resnet18(pretrained=True)
model.eval() # 推論モードに設定
# 2. 特徴抽出のためのレイヤーを選択 (例: 最終の平均プーリング層)
feature_extractor = torch.nn.Sequential(*list(model.children())[:-1])
# 3. 画像の前処理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 4. 画像の読み込み
image = Image.open(image_path).convert('RGB')
img_tensor = transform(image).unsqueeze(0) # バッチ次元を追加
# 5. 特徴量の抽出
with torch.no_grad():
features = feature_extractor(img_tensor)
# グローバル平均プーリングを適用して1次元ベクトルに
features_flat = torch.mean(features, dim=(-1, -2)).flatten()
print("抽出された特徴ベクトルの形状:", features_flat.shape)
print("抽出された特徴ベクトル:", features_flat.numpy())100%|████████████████████████████████████████████████████████████████████████████████| 44.7M/44.7M [00:00<00:00, 60.7MB/s]
抽出された特徴ベクトルの形状: torch.Size([512])
抽出された特徴ベクトル: [4.05794501e-01 2.90332325e-02 2.41773057e+00 1.10476327e+00
6.20531552e-02 4.28220071e-03 2.41214797e-01 3.60294819e-01
2.25273657e+00 7.08012819e-01 4.22281884e-02 4.38979298e-01
5.78672811e-03 8.05866301e-01 9.16353583e-01 1.04498768e+00
~~~~省略~~~~
2.08169788e-01 2.30096102e+00 1.29922882e-01 1.06868342e-01
6.27624467e-02 4.68800694e-01 0.00000000e+00 1.84949386e+00
7.95218796e-02 1.12515837e-01 1.27313092e-01 5.28125502e-02]
CNNとクラスタリングによる画像分類

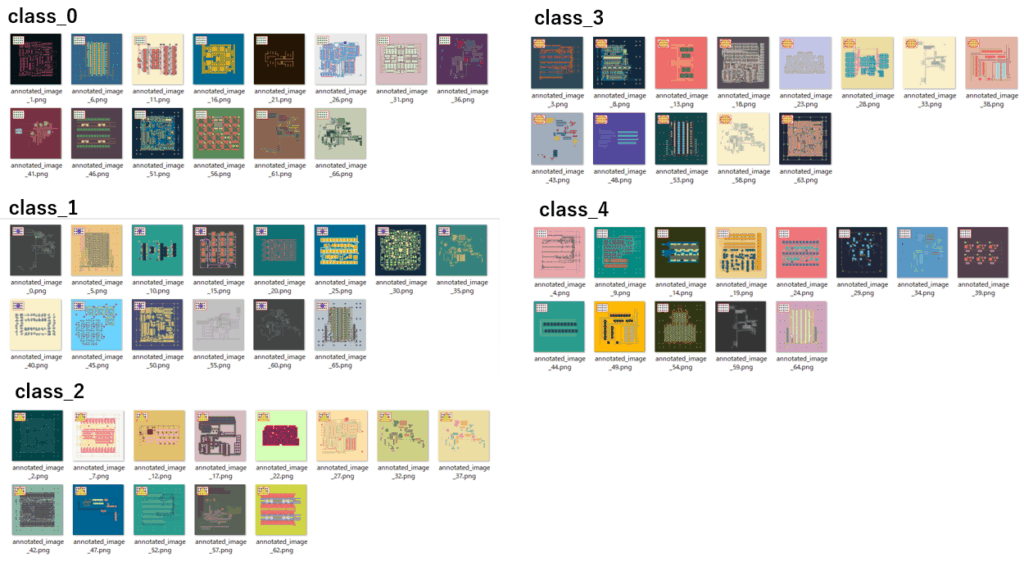
今回も、「【Python実践】YOLOv8で物体検出&追加学習を試す(コピペで使えるサンプルソース付き)」で紹介した方法で作ったサンプル画像(上図)を使用しています。
サンプル画像の左上には、下記の5種類のマーク画像が書き込まれています。

このマーク画像の部分を切り出して、畳み込みニューラルネットワーク(CNN)を使って特徴抽出 を行い、K-meansクラスタリング に適用して画像を分類します。
下記のサンプルプログラムは、image_folderで指定したフォルダに格納されているファイルから特徴量を抽出し、クラスタリングで分類後、output_folderで指定したフォルダに分類結果を出力します。
具体的には、output_folderで指定したフォルダの中に、クラス毎のフォルダが自動作成され、該当するファイルがコピー されます。
画像全体から特徴量を抽出したい場合、crop_coords = Noneを、画像の一部から特徴量を抽出したい場合、crop_coords = (x1,y1,y2,y2) でクリップ領域を指定します。
import cv2
import numpy as np
import os
import shutil
import torch
import torchvision.models as models
import torchvision.transforms as transforms
from sklearn.cluster import KMeans
from PIL import Image
def get_cnn_features(image_pil, model, transform):
"""
PIL形式の画像からCNN(ResNet-50)を使って特徴量を抽出する。
Args:
image_pil (PIL.Image.Image): 特徴量を抽出するPIL形式の画像
model (torch.nn.Module): 特徴量抽出に使用する学習済みCNNモデル(ここではResNet-50)
transform (torch.transforms.Compose): 画像をモデルに入力する前に適用する変換処理
Returns:
np.ndarray: 抽出されたCNN特徴量(flattenされた1次元配列)
"""
# 画像テンソルに変換し、バッチ次元を追加
image_tensor = transform(image_pil).unsqueeze(0)
# 勾配計算を行わないコンテキスト内で推論を実行
with torch.no_grad():
# モデルに画像を入力して特徴量を取得
features = model(image_tensor)
# 特徴量をNumPy配列に変換し、flattenして1次元配列にする
return features.numpy().flatten()
def extract_cnn_features(image_folder, crop_coords=None):
"""
指定フォルダ内の画像を読み込み、指定した領域を切り取り、2倍に拡大した後、
学習済みCNN(ResNet-50)を使って各画像から特徴量を抽出する。
Args:
image_folder (str): 画像ファイルが格納されているフォルダのパス
crop_coords (tuple, optional): (x, y, w, h) の形式で、切り取る画像の領域を指定するタプル
Returns:
np.array: 各画像から抽出されたCNN特徴量を格納したNumPy配列(各行が1つの画像の特徴ベクトル)
list: 処理した画像のファイル名のリスト
"""
# 学習済みのResNet-50モデルをロード
model = models.resnet50(pretrained=True)
model.eval()
# 画像をモデルに入力する前に適用する変換処理を定義
transform = transforms.Compose([
transforms.Resize((224, 224)), # 画像サイズを224x224にリサイズ
transforms.ToTensor(), # PIL画像をPyTorchテンソルに変換
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # ImageNetの統計値で正規化
])
feature_list = []
image_names = []
# 指定フォルダ内のすべてのファイルに対してループ処理
for filename in os.listdir(image_folder):
image_path = os.path.join(image_folder, filename)
# 画像を読み込む
image = cv2.imread(image_path)
# 画像が正常に読み込めた場合のみ処理
if image is not None:
# 画像をグレースケールに変換
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if crop_coords is not None:
# 切り取る領域の座標を取得
x, y, w, h = crop_coords
# 指定した領域で画像を切り取る
cropped_image = image_gray[y:y+h, x:x+w]
# 切り取った画像を2倍に拡大
resized_image = cv2.resize(cropped_image, (w * 2, h * 2), interpolation=cv2.INTER_CUBIC)
else:
# crop_coordsがNoneの場合、画像をそのまま使用し、2倍に拡大
resized_image = cv2.resize(image_gray, (image.shape[1] * 2, image.shape[0] * 2), interpolation=cv2.INTER_CUBIC)
# OpenCV画像をPIL形式に変換し、RGBに変換
image_pil = Image.fromarray(resized_image).convert("RGB")
# CNNから特徴量を抽出
features = get_cnn_features(image_pil, model, transform)
# 抽出した特徴量をリストに追加
feature_list.append(features)
# 画像ファイル名をリストに追加
image_names.append(filename)
# 特徴量のリストをNumPy配列に変換して返す
return np.array(feature_list), image_names
def cluster_features(feature_vectors, image_names, num_clusters=5):
"""
CNNから取得した特徴ベクトルを用いてK-meansクラスタリングを行い、画像を分類する。
Args:
feature_vectors (np.array): CNNで抽出された特徴量のリスト(各行が1つの画像の特徴ベクトル)
image_names (list): 対応する画像ファイル名のリスト
num_clusters (int): 生成するクラスタの数(デフォルトは5)
Returns:
list: 各画像ファイル名に対応するクラスタラベルのリスト
"""
# もしfeature_vectorsが1D配列の場合、reshapeして2Dに変換
if feature_vectors.ndim == 1:
feature_vectors = feature_vectors.reshape(1, -1) # 1つのサンプルを持つ場合
# K-meansクラスタリングモデルを初期化
kmeans = KMeans(n_clusters=num_clusters, random_state=0)
# 特徴ベクトルを用いてクラスタリングを実行
kmeans.fit(feature_vectors)
# 各画像に割り当てられたクラスタラベルを取得
image_classes = kmeans.labels_
# 画像ファイル名と割り当てられたクラスを表示
for idx, filename in enumerate(image_names):
print(f"画像: {filename} -> クラス: {image_classes[idx]}")
# クラスタラベルのリストを返す
return image_classes
def organize_images(image_folder, image_names, image_classes, output_folder):
"""
クラスタリングの結果に基づいて、画像をクラスごとのサブフォルダに振り分けてコピーする。
Args:
image_folder (str): 元の画像ファイルが格納されているフォルダのパス
image_names (list): 画像ファイル名のリスト
image_classes (list): 各画像に対応するクラスタラベルのリスト
output_folder (str): 分類結果を保存する親フォルダのパス
"""
# 出力フォルダが存在しない場合は作成
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 各画像とそのクラスラベルに基づいて処理
for idx, filename in enumerate(image_names):
# クラスに対応するサブフォルダ名を作成
class_folder = os.path.join(output_folder, f"class_{image_classes[idx]}")
# クラスフォルダが存在しない場合は作成
if not os.path.exists(class_folder):
os.makedirs(class_folder)
# 元の画像のパス
source_path = os.path.join(image_folder, filename)
# コピー先のパス
dest_path = os.path.join(class_folder, filename)
# 画像ファイルをコピー
shutil.copy(source_path, dest_path)
print("画像の分類とコピーが完了しました!")
#=============================================================
# 実行部分
#=============================================================
# 分類したい画像が格納されているフォルダのパス
image_folder = r"P:\annotated_images"
# 分類結果を保存するフォルダのパス
output_folder = r"P:\classified_images"
# 切り取る画像の領域 (x, y, width, height)
crop_coords = (50, 50, 150, 300)
# CNNを使って画像から特徴量を抽出
features_vector, image_names = extract_cnn_features(image_folder, crop_coords)
# 特徴量が正常に抽出できた場合
if features_vector is not None:
# 抽出した特徴量をクラスタリングして画像のクラスを予測
image_classes = cluster_features(features_vector, image_names, num_clusters=5)
# 予測されたクラスに基づいて画像をフォルダに整理
organize_images(image_folder, image_names, image_classes, output_folder)
# 特徴量が抽出できなかった場合のエラーメッセージ
else:
print("画像から特徴量を取得できませんでした。")p:\DataAnalysis\python-3.12.3.amd64\Lib\site-packages\torchvision\models_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
p:\DataAnalysis\python-3.12.3.amd64\Lib\site-packages\torchvision\models_utils.py:223: UserWarning: Arguments other than a weight enum or None for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing weights=ResNet50_Weights.IMAGENET1K_V1. You can also use weights=ResNet50_Weights.DEFAULT to get the most up-to-date weights.
warnings.warn(msg)
画像: annotated_image_0.png -> クラス: 1
画像: annotated_image_1.png -> クラス: 0
画像: annotated_image_10.png -> クラス: 1
画像: annotated_image_11.png -> クラス: 0
画像: annotated_image_12.png -> クラス: 2
~~~~以下省略~~~~
実行した結果、見事に全てのマーク画像が分類できました。やはりCNNの力は偉大です。
まとめ
本記事では、画素数が少なく類似性の高い画像分類という課題に対し、CNN(畳み込みニューラルネットワーク)と非教師あり学習であるクラスタリングを組み合わせた新たなアプローチをご紹介しました。
従来のSIFTによる分類では困難であった、微妙な差異しか持たない単純な画像群に対しても、CNNが捉える高度な特徴表現とクラスタリングによるグルーピングは、驚くべき分類精度を実現しました。
ご紹介したサンプルコードを通じて、CNNが画像からいかに効果的に特徴を抽出し、それをクラスタリングに応用することで、新たな画像分類の可能性を切り開くかをご体験いただけたことと思います。
ぜひ、本記事でご紹介したサンプルコードを参考に、様々な画像データでCNNとクラスタリングの力を試してみてください。








コメント