
Prophetは、季節性や休日効果など複雑な時系列パターンを簡単に扱えるのが強みで、ビジネス現場での需要予測や異常検知に幅広く利用されています。Python初心者でも扱いやすい設計で、手軽に高精度な予測モデルを構築可能です。
本記事では、Facebookが開発した時系列予測ライブラリ「Prophet」について、基本的な特徴や仕組みから、Pythonを使った具体的な実装方法、さらに予測・異常検知・補正への応用例まで詳しく解説します。
時系列データ分析全般に関する情報、他の手法について知りたい方は、「【Python実践】時系列データ分析で未来予測・異常検知・補正に挑戦!」をご一読ください。

Prophet とは
ProphetはFacebook(現Meta)が開発した時系列予測モデルで、トレンド変化や季節性、祝日効果を柔軟に捉えることができるのが特徴です。シンプルなAPIで使いやすく、欠損値や異常値があるデータにも比較的頑健に対応できます。
非専門家でも扱いやすい設計で、マーケティングや売上予測、Webトラフィック解析など幅広い分野で利用されています。
得意な分野
✅ 複雑なトレンド変動の把握:トレンドの変化点を自動検出し、柔軟にモデル化可能。
✅ 季節性の多重対応:日次・週次・年次など複数の季節性を同時に扱える。
✅ 祝日やイベント効果の組み込み:特定日の影響をモデルに加えられる。
✅ 欠損値や外れ値に強い:データの不完全性に対して比較的ロバスト。
✅ 直感的で簡単な操作:Python/R用にAPIが用意されており、導入が容易。
不得意な分野
❌ 非線形な複雑パターンの捕捉:単純な非線形性や複雑な相互作用は苦手な場合もある。
❌ 多変量時系列の直接処理:基本的に単変量時系列モデルで、多変量対応は限定的。
❌ 短期データや非常に不規則なデータ:十分な期間の履歴が必要。
❌ モデルチューニングの複雑さ:トレンド変化点の数など調整が難しい場合がある。
準備
本記事で紹介しているプログラムを実行する場合、こちらに掲載しているプログラムを実行し、ダミーデータを作成の上、各プログラムの read_csv() のファイル参照パスを適宜変更してください。
また、下記のコマンドで必要なモジュールをインストールしてください。
pip install pandas numpy matplotlib prophet
Prophet による未来予測
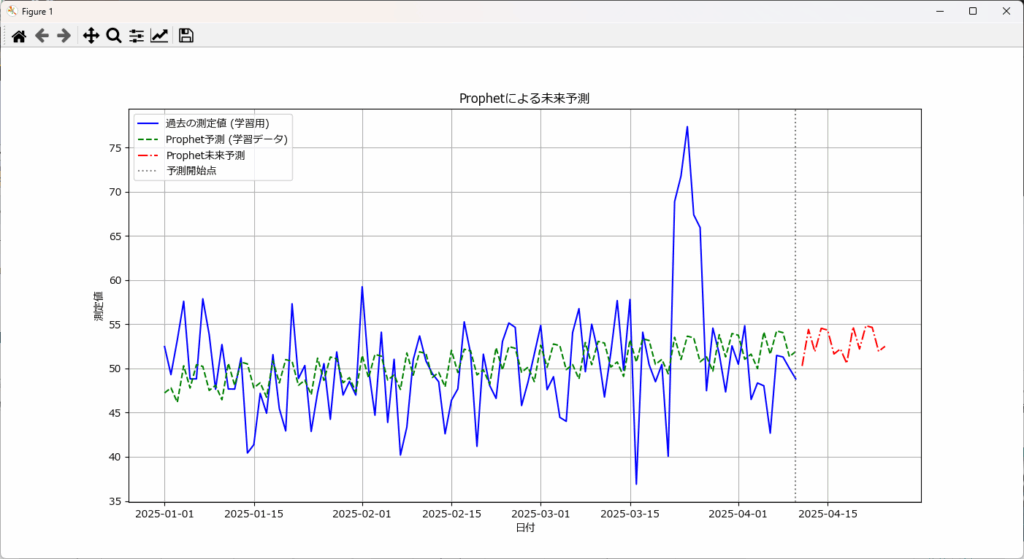
予測値(赤い破線)と測定値(青い実線)の間には、比較的大きな乖離が見受けられます。 特に、測定値が大きく上下する場面で、Prophetの予測値がその変動に追従しきれておらず、より平滑化された、平均的な動きを示していることがわかります。
これは、Prophetが長期的なトレンドや季節性といったデータの大きな構造を抽出することに長けている一方で、日々の細かなノイズや、突発的・不規則な変動を「外れ値」として吸収(あるいは無視)する傾向があるためです。この特性は、予測が一時的なノイズに過度に引っ張られるのを防ぐメリットがある一方で、細かな日々の変動や、本当に重要な急激な変化を捉えきれないという課題でもあります。
Prophetのパラメータ(例:changepoint_prior_scaleやseasonality_prior_scale)の調整、外部要因を説明変数(extra regressors)として追加する、あるいは外れ値の事前処理などを試すことで、実態に即した予測に近づけられるかもしれません。
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
from prophet import Prophet
import warnings
warnings.filterwarnings("ignore") # 警告を無視
# 日本語フォントの設定
rcParams['font.family'] = 'Meiryo'
def prophet_forecast_future(df: pd.DataFrame, timestamp_col: str, value_col: str, forecast_steps: int = 14):
"""
Prophetを使用して未来予測を行う。
Parameters:
df (pd.DataFrame): 時系列データのDataFrame。
timestamp_col (str): タイムスタンプの列名。
value_col (str): 対象の数値データの列名。
forecast_steps (int): 未来の予測ステップ(日数単位)。
Returns:
pd.DataFrame: 予測結果(未来の予測値を含む)。
"""
# Prophet用に列名を変更
df_processed = df.rename(columns={timestamp_col: "ds", value_col: "y"}).copy()
# 欠損値を線形補完
df_processed["y"] = df_processed["y"].interpolate(method="linear").fillna(method="bfill").fillna(method="ffill")
# モデル定義・学習
print(f"\n--- Prophetによる未来予測 ({forecast_steps}日先まで) ---")
model = Prophet(daily_seasonality=True)
model.fit(df_processed)
print("Prophetモデルの学習が完了しました。")
# 未来の期間データ作成
future = model.make_future_dataframe(periods=forecast_steps)
forecast = model.predict(future)
# フィッティング範囲と未来予測範囲に分割
past_forecast = forecast.iloc[:len(df_processed)]
future_forecast = forecast.iloc[len(df_processed):]
# 結果のプロット
plt.figure(figsize=(14, 7))
# 過去の実測値(青実線)
plt.plot(df_processed["ds"], df_processed["y"], label="過去の測定値 (学習用)", color="blue")
# 学習データに対する予測(緑点線)
plt.plot(past_forecast["ds"], past_forecast["yhat"], label="Prophet予測 (学習データ)", color="green", linestyle="--")
# 未来予測(赤点線)
plt.plot(future_forecast["ds"], future_forecast["yhat"], label="Prophet未来予測", color="red", linestyle="-.")
# 予測開始点の縦点線
forecast_start = df_processed["ds"].max()
plt.axvline(x=forecast_start, color="gray", linestyle=":", label="予測開始点")
# グラフ体裁
plt.xlabel("日付")
plt.ylabel("測定値")
plt.title("Prophetによる未来予測")
plt.legend()
plt.grid(True)
plt.show()
# 未来予測だけを返す
forecast_result = future_forecast[["ds", "yhat"]].set_index("ds")
print("予測結果:")
print(forecast_result)
return forecast_result
if __name__ == "__main__":
# データ読み込み
csv_filename = "dummy_timeseries.csv"
df = pd.read_csv(csv_filename, parse_dates=["timestamp"])
# 未来予測の実行
prophet_predictions = prophet_forecast_future(df, "timestamp", "value", forecast_steps=14)
Prophetモデルの学習が完了しました。
予測結果:
yhat
ds
2025-04-11 50.288324
2025-04-12 54.422316
2025-04-13 51.907291
2025-04-14 54.550533
2025-04-15 54.355342
2025-04-16 51.643083
2025-04-17 52.218810
2025-04-18 50.583732
2025-04-19 54.717725
2025-04-20 52.202700
2025-04-21 54.845941
2025-04-22 54.650750
2025-04-23 51.938491
2025-04-24 52.514218
Prophet による異常検知
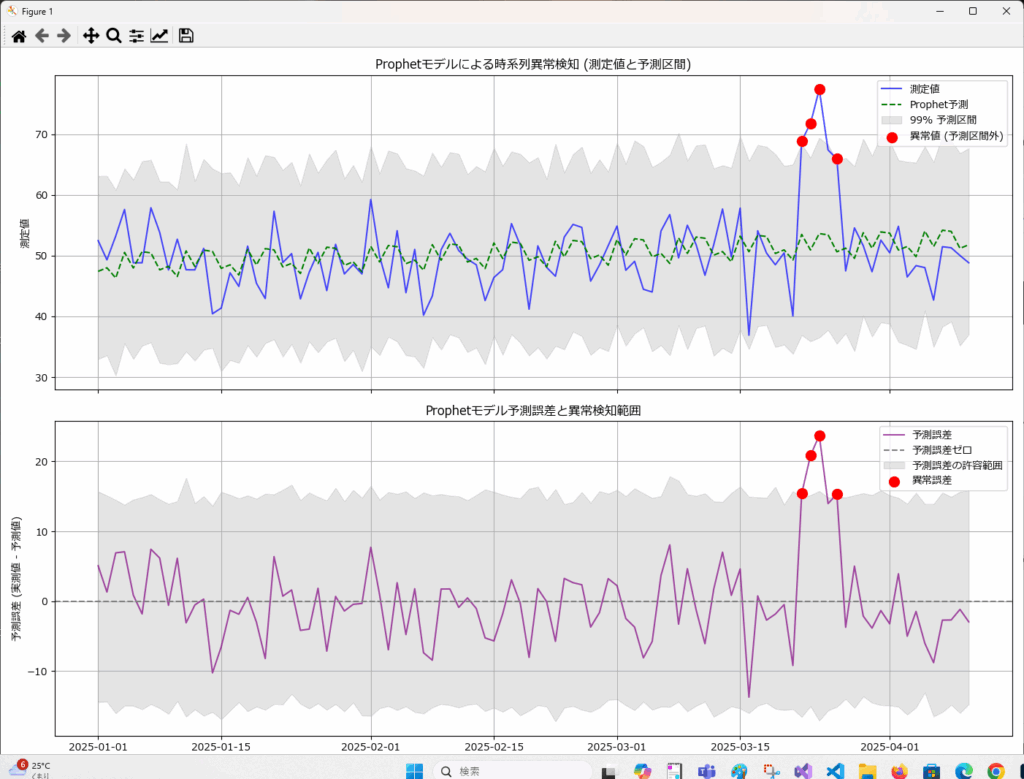
Prophetは、短期的なノイズではなく構造的な外れ値に強いことが特徴です。
はじめに、データの基盤となるトレンドや季節性といった主要なパターンを学習し、それに基づいて予測値(yhat)と、その予測が取りうる範囲を示す予測区間(yhat_lowerとyhat_upperで定義される信頼区間)を算出します。
そして、実際の値がこの予測区間から大きく外れた場合、その点を「異常値」と判断します。 つまり、Prophetは学習した通常のパターンから逸脱している点を異常と識別します。異常と判断するための上限(閾値)は、interval_widthで指定することが可能です。
# pip install Prophet
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
from prophet import Prophet
import warnings
warnings.filterwarnings("ignore") # 警告メッセージを非表示にする
# 日本語フォントの設定 (お使いの環境に合わせて適宜変更してください)
rcParams['font.family'] = 'Meiryo' # Windowsの場合
# rcParams['font.family'] = 'AppleGothic' # Macの場合
# rcParams['font.family'] = 'DejaVu Sans' # デフォルト、日本語対応しない場合がある
def prophet_anomaly_detection(df: pd.DataFrame, time_col: str, value_col: str,
interval_width: float = 0.95,
yearly_seasonality: bool = False,
weekly_seasonality: bool = True,
daily_seasonality: bool = False):
"""
Prophetモデルを使用して時系列データの異常検知を行います。
予測区間からの逸脱を異常と見なします。
Args:
df (pd.DataFrame): 処理するデータフレーム。Prophetの要件に合わせて、
タイムスタンプ列は 'ds'、値の列は 'y' に内部でリネームされます。
time_col (str): タイムスタンプの元の列名。
value_col (str): 時系列データの値の元の列名。
interval_width (float, optional): 予測区間の幅(信頼水準)。デフォルトは0.95 (95%)。
この範囲外が異常となる。
yearly_seasonality (bool, optional): 年次季節性を考慮するか。デフォルトはFalse。
weekly_seasonality (bool, optional): 週次季節性を考慮するか。デフォルトはTrue。
daily_seasonality (bool, optional): 日次季節性を考慮するか。デフォルトはFalse。
Returns:
pd.DataFrame: 'ds', 'y', 'yhat', 'yhat_lower', 'yhat_upper', 'is_anomaly', 'residuals' 列が追加されたデータフレーム。
"""
# Prophetの要件に合わせて列名をリネーム
df_prophet = df.rename(columns={time_col: 'ds', value_col: 'y'})
# Prophetモデルの構築と学習
print(f"--- Prophetモデルの適用 (予測区間幅: {interval_width*100}%) ---")
try:
model = Prophet(
interval_width=interval_width,
yearly_seasonality=yearly_seasonality,
weekly_seasonality=weekly_seasonality,
daily_seasonality=daily_seasonality
)
# 祝日がある場合は model.add_country_holidays(country_name='JP') などで追加可能
model.fit(df_prophet)
print("Prophetモデルの学習が完了しました。")
except Exception as e:
print(f"Prophetモデルの学習中にエラーが発生しました: {e}")
return None
# 学習データ期間内での予測(fitted valuesに相当)
forecast = model.predict(df_prophet)
# 予測結果を元のデータフレームに結合
df_result = df_prophet.set_index('ds').copy()
df_result = df_result.join(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].set_index('ds'))
# 残差(予測誤差)を計算
df_result['residuals'] = df_result['y'] - df_result['yhat']
# 異常検知 (予測区間からの逸脱)
# 実際の値が予測区間 (yhat_lower, yhat_upper) の外にある場合を異常とする
df_result['is_anomaly'] = (df_result['y'] < df_result['yhat_lower']) | \
(df_result['y'] > df_result['yhat_upper'])
# 検出された異常値の表示
anomalies = df_result[df_result['is_anomaly']]
if not anomalies.empty:
print("\n--- 検出された異常値 ---")
# 元の列名に戻して表示 (オプション)
print(anomalies.rename(columns={'ds': time_col, 'y': value_col})[[value_col, 'yhat', 'yhat_lower', 'yhat_upper', 'residuals', 'is_anomaly']])
else:
print("\n--- 異常値は検出されませんでした ---")
# --- 結果の可視化 (グラフを縦に並べる) ---
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(14, 10), sharex=True) # 2行1列でグラフを配置
# 1つ目のサブプロット: 測定値、Prophet予測、予測区間
axes[0].plot(df_result.index, df_result['y'], label='測定値', color='blue', alpha=0.7)
axes[0].plot(df_result.index, df_result['yhat'], label='Prophet予測', color='green', linestyle='--')
# 予測区間のプロット
axes[0].fill_between(df_result.index, df_result['yhat_lower'], df_result['yhat_upper'],
color='gray', alpha=0.2, label=f'{int(interval_width*100)}% 予測区間')
if not anomalies.empty:
axes[0].scatter(anomalies.index, anomalies['y'], color='red', s=100, zorder=5, label='異常値 (予測区間外)')
axes[0].set_title('Prophetモデルによる時系列異常検知 (測定値と予測区間)')
axes[0].set_ylabel('測定値')
axes[0].legend()
axes[0].grid(True)
# 2つ目のサブプロット: 残差と閾値 (Prophetは残差を直接計算しないため、ここでは「予測誤差」を示す)
# 修正点: anomalies['residuals'] ではなく df_result['residuals'] を参照する
axes[1].plot(df_result.index, df_result['residuals'], label='予測誤差', color='purple', alpha=0.7)
axes[1].axhline(0, color='gray', linestyle='--', label='予測誤差ゼロ')
# 予測区間の上下限を誤差の視点から描画
axes[1].fill_between(df_result.index,
df_result['yhat_lower'] - df_result['yhat'],
df_result['yhat_upper'] - df_result['yhat'],
color='gray', alpha=0.2, label='予測誤差の許容範囲')
if not anomalies.empty:
# ここを修正: anomalies['residuals'] -> df_result.loc[anomalies.index, 'residuals']
# または、anomalies データフレームに 'residuals' 列がある前提ならそのまま使えるが、
# より安全に、anomalies['y'] - anomalies['yhat'] を使う
axes[1].scatter(anomalies.index, anomalies['y'] - anomalies['yhat'], color='red', s=100, zorder=5, label='異常誤差')
axes[1].set_title('Prophetモデル予測誤差と異常検知範囲')
axes[1].set_xlabel('日付')
axes[1].set_ylabel('予測誤差 (実測値 - 予測値)')
axes[1].legend()
axes[1].grid(True)
plt.tight_layout() # サブプロット間のスペースを自動調整
plt.show()
return df_result
# --- メインの実行部分 ---
if __name__ == "__main__":
# CSVを読み込んで関数を実行
df = pd.read_csv("dummy_timeseries.csv", parse_dates=["timestamp"])
result_df = prophet_anomaly_detection(df,
time_col="timestamp",
value_col="value",
interval_width=0.99, # 99%予測区間を閾値とする (より厳しく)
yearly_seasonality=False,
weekly_seasonality=True,
daily_seasonality=False)
if result_df is not None:
print("\n--- 関数実行結果 (異常値検出フラグ含む) ---")
print(result_df.tail())--- 検出された異常値 ---
value yhat yhat_lower yhat_upper residuals is_anomaly
ds
2025-03-22 68.901641 53.504546 36.931610 68.384867 15.397094 True
2025-03-23 71.785563 50.936106 35.892285 66.095528 20.849457 True
2025-03-24 77.389470 53.636941 36.525449 69.396055 23.752529 True
2025-03-26 65.9575
Prophet によるデータ補正/クリーニング
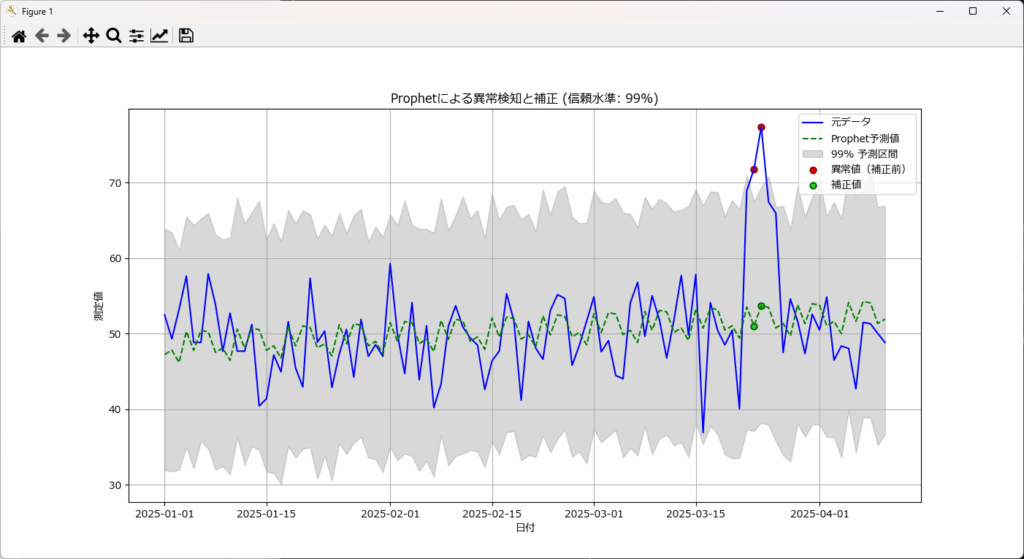
Prophetにより検出した「異常値」を、「予測値」で置き換えることでデータ補正が行えます。突発的・不規則な変動を異常値として扱いたい場合、Prophetは最適です。
しかし、逆に正常な範囲で突発的・不規則な変動が存在する場合、Prophet では期待するほどの補正効果が得られないかもしれません。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
from prophet import Prophet
import warnings
warnings.filterwarnings("ignore")
rcParams['font.family'] = 'Meiryo'
def prophet_anomaly_detection_and_cleaning(df: pd.DataFrame,
time_col: str,
value_col: str,
interval_width: float = 0.95, # New parameter
correction_method: str = "mean"):
"""
Prophetを使って異常検知&補正を行う関数
Parameters:
df (pd.DataFrame): 時系列データ
time_col (str): タイムスタンプ列名
value_col (str): 測定値の列名
interval_width (float): 予測区間の幅(信頼水準)。0から1の間の値。デフォルトは0.95 (95%)。
correction_method (str): "mean"(Prophet予測)または "median"(移動中央値)
Returns:
pd.DataFrame: 異常値を補正したデータフレーム
"""
# Prophet 用に整形
df_prophet = df[[time_col, value_col]].rename(columns={time_col: "ds", value_col: "y"}).copy()
df_prophet["y"] = df_prophet["y"].interpolate(method="linear").fillna(method="bfill").fillna(method="ffill")
# モデル構築と予測
# interval_width を Prophet モデルに渡す
model = Prophet(daily_seasonality=True, interval_width=interval_width)
model.fit(df_prophet)
forecast = model.predict(df_prophet)
# 異常値の検出: 実際の値が予測区間外にあるかを判定
df_prophet["yhat"] = forecast["yhat"]
df_prophet["yhat_lower"] = forecast["yhat_lower"]
df_prophet["yhat_upper"] = forecast["yhat_upper"]
df_prophet["is_anomaly"] = (df_prophet["y"] < df_prophet["yhat_lower"]) | \
(df_prophet["y"] > df_prophet["yhat_upper"])
# 異常値補正
if correction_method == "mean":
df_prophet["corrected"] = df_prophet.apply(
lambda row: row["yhat"] if row["is_anomaly"] else row["y"], axis=1
)
elif correction_method == "median":
rolling_median = df_prophet["y"].rolling(window=7, center=True, min_periods=1).median()
df_prophet["corrected"] = df_prophet.apply(
lambda row: rolling_median[row.name] if row["is_anomaly"] else row["y"], axis=1
)
else:
raise ValueError("correction_method は 'mean' または 'median' のいずれかを指定してください。")
# 元のタイムスタンプに戻す
df_result = df.copy()
df_result["補正後"] = df_prophet["corrected"].values
df_result["異常値"] = df_prophet["is_anomaly"].values
df_result["予測値"] = df_prophet["yhat"].values
df_result["予測下限"] = df_prophet["yhat_lower"].values
df_result["予測上限"] = df_prophet["yhat_upper"].values
# 可視化
plt.figure(figsize=(14, 7))
plt.plot(df_prophet["ds"], df_prophet["y"], label="元データ", color="blue")
plt.plot(df_prophet["ds"], df_prophet["yhat"], label="Prophet予測値", color="green", linestyle="--")
plt.fill_between(df_prophet["ds"], df_prophet["yhat_lower"], df_prophet["yhat_upper"],
color='lightgreen', alpha=0.3, label=f'{int(interval_width*100)}% 予測区間')
plt.scatter(df_prophet["ds"][df_prophet["is_anomaly"]],
df_prophet["y"][df_prophet["is_anomaly"]],
color="red", label="異常値(補正前)", edgecolors="darkred", linewidths=1.5)
plt.scatter(df_prophet["ds"][df_prophet["is_anomaly"]],
df_prophet["corrected"][df_prophet["is_anomaly"]],
color="limegreen", label="補正値", edgecolors="darkgreen", linewidths=1.5)
plt.xlabel("日付")
plt.ylabel("測定値")
plt.title(f"Prophetによる異常検知と補正 (信頼水準: {int(interval_width*100)}%)")
plt.legend()
plt.grid(True)
plt.show()
return df_result
# --- 実行例 ---
if __name__ == "__main__":
# Assuming 'dummy_timeseries.csv' exists and has 'timestamp' and 'value' columns
# For demonstration, let's create a dummy CSV if it doesn't exist
try:
df = pd.read_csv("dummy_timeseries.csv", parse_dates=["timestamp"])
except FileNotFoundError:
print("dummy_timeseries.csv not found. Creating a sample dummy_timeseries.csv.")
dates = pd.to_datetime(pd.date_range(start="2023-01-01", periods=100, freq="D"))
values = np.sin(np.linspace(0, 20, 100)) * 10 + 50 + np.random.randn(100) * 5
# Introduce some anomalies
values[10] = 100
values[50] = 10
values[80] = 120
df = pd.DataFrame({"timestamp": dates, "value": values})
df.to_csv("dummy_timeseries.csv", index=False)
print("dummy_timeseries.csv created.")
df = pd.read_csv("dummy_timeseries.csv", parse_dates=["timestamp"])
cleaned_df = prophet_anomaly_detection_and_cleaning(df,
time_col="timestamp",
value_col="value",
interval_width=0.99, # 信頼水準を99%に設定
correction_method="mean")
print("\n--- 補正後のデータ ---")
print(cleaned_df.tail())--- 補正後のデータ ---
timestamp value 補正後 異常値 予測値
95 2025-04-06 42.682425 42.682425 False 51.611883
96 2025-04-07 51.480601 51.480601 False 54.255124
97 2025-04-08 51.305276 51.305276 False 54.059934
98 2025-04-09 50.025567 50.025567 False 51.347675
99 2025-04-10 48.827064 48.827064 False 51.923402
まとめ
本記事では、Prophetの特徴と基本的な使い方、Pythonでのモデル構築手順、さらに実際の時系列データを使った予測・異常検知・補正の活用例を解説しました。
Prophetは季節性やトレンド、休日効果などを柔軟に捉えられるため、複雑な時系列データに対しても高精度な予測が可能です。
また、Pythonの使いやすいAPIで、比較的簡単にモデルを作成できるため、多くのビジネスシーンで効果的に活用されています。
ぜひProphetを使って、より実践的で精度の高い時系列データ分析に挑戦してみてください。








コメント