
大量にスキャンされた設計図や技術資料の中から、特定のマークやロゴが含まれているものだけを自動で選別したい。
こうしたニーズは、古い図面の整理やドキュメントの分類など、現場業務でしばしば発生します。
このような「画像内に特定の要素が含まれているかどうか」というシンプルな判定には、PyTorchのResNetを活用した画像分類モデルが有効です。
本記事では、サンプルデータとサンプルプログラムを用いながら、その構築過程と評価結果を実践的に解説しています。
同様の課題をお持ちの方や、画像分類モデルの導入を検討されている方は、ぜひ参考にしてみてください。
ResNetとは
ResNet(Residual Network)は、Convolutional Neural Network(CNN:畳み込みニューラルネットワーク)の一種です。
CNNは画像の形状や模様、色、構造などを自動で学習するのに適したアーキテクチャで、画像分類や認識といったタスクに広く用いられています。
ResNetの最大の特徴は、「残差接続(Residual Connection)」と呼ばれる構造にあります。
通常、ニューラルネットワークの層を深くすればするほど表現力が増しますが、ある深さを超えると学習が進まなくなる「勾配消失」や「性能の劣化」といった問題が発生します。
ResNetはこの課題に対し、「出力を直接計算するのではなく、入力との差分(残差)だけを学習する」というアプローチを採用しました。
これにより、数十層〜100層を超えるような深いネットワークでも、安定して学習できるようになっています。
ResNetの活用パターン
ResNetには2通りの使い方があります。
- 分類器として使う(教師あり学習)
「対象物が含まれている画像」と「含まれていない画像」を用意して学習させることで、画像分類モデルとして活用できます。
たとえば「ロゴが写っているか否か」などの2値分類や、「A/B/Cいずれのパターンか」といった多クラス分類にも対応できます。 - 特徴量抽出器として使う(教師なし学習)
ResNetの中間層から出力される特徴ベクトルを利用すれば、クラスタリングや類似度計算などの教師なし学習にも応用できます。
このような使い方に興味のある方は、以下の記事をご覧ください。
YOLO、ResNet、SIFTとの違い
画像に関するAIタスクでは、YOLOやSIFT(あるいはGrad-CAM)といった手法もよく登場します。それぞれの目的と役割りを整理しておきましょう。
| 項目 | ResNet | YOLO | SIFT | Grad-CAM |
|---|---|---|---|---|
| 主な役割 | 画像分類(対象が含まれているか) | 物体検出(どこにあるか) | 特徴点抽出と画像照合 | モデルの判断根拠を可視化 |
| アプローチ | 深層学習(CNN) | 深層学習(CNNベース) | 古典的画像処理アルゴリズム | 深層学習モデルの中間層の可視化 |
| 出力 | 「ロゴあり/なし」などのクラス | バウンディングボックスとクラスラベル | 画像内のキーポイントベクトル | ヒートマップ(注目領域の可視化) |
| 応用フェーズ | 学習/推論 | 推論 | 特徴マッチング/前処理/照合 | モデル解釈/信頼性検証 |
| 使いどころ | スクリーニング/分類 | ロゴ位置の特定・カウント | ロゴの一致判定/特徴点比較 | モデルが“なぜそう判断したか”を説明・可視化 |
今回ご紹介している分類モデルは、「ロゴが含まれているかどうか」を画像全体を通じて判定する ResNet の分類アプローチです。
ただし、モデルの判断根拠を確認したい場合には、Grad-CAMやSIFTのような可視化手法を併用することで、より信頼性の高い運用が可能になります。
サンプルデータについて

上図は、本記事で使用したサンプルデータです。ランダムな升目の中に、位置とサイズをランダムにして、下記の文字列を描いています
"◎AB◎"、"◎●◎●◎"、"◎◎◎◎"、"■■■■"、"■◎■◎"、"●●●●"、"ABCD"、"A◎B◎"
これをロゴと見立て、"◎AB◎" が描かれている画像をResNetを用いて分類します。
下記はサンプルデータを生成するためのプログラムです。生成する枚数は gen_cnt 、生成先フォルダは root_folder で指定しますので、ご自身の環境に合わせて適宜変更してください。
from PIL import Image, ImageDraw, ImageFont
import os, random
import numpy as np
from PIL import ImageFilter
def generate_image(path, logo_list, size=(1024, 512)):
"""
ランダムな背景線とロゴ文字列を描いた画像を生成する
Parameters:
- path: 未使用(互換性のため保持。実際は return された画像オブジェクトを使って保存)
- logo_list: ロゴ候補の文字列リスト(例: ["◎◎◎", "ABCD"])。この中からランダムに1つ選んで描画される
- size: 出力画像のサイズ(幅, 高さ)。デフォルトは 1024×512
Returns:
- PIL.Image.Image オブジェクト(加工済みのロゴ画像)
使用例:
logo_patterns = ["◎AB◎", "◎◎◎◎", "■●■●"]
img = generate_image(None, logo_patterns)
img.save("sample.jpg")
"""
img = Image.new("RGB", size, (255, 255, 255))
draw = ImageDraw.Draw(img)
# 背景に縦線と横線(線幅ランダム)
for x in range(0, size[0], 40):
width = random.randint(1, 5)
draw.line([(x, 0), (x, size[1])], fill=(200, 200, 200), width=width)
for y in range(0, size[1], 40):
width = random.randint(1, 5)
draw.line([(0, y), (size[0], y)], fill=(200, 200, 200), width=width)
# ランダムなフォントサイズ・位置で「◎◎◎」を描画
font_size = random.randint(50, 150)
try:
font = ImageFont.truetype(r"c:\WINDOWS\Fonts\MEIRYOB.TTC", font_size)
except:
font = ImageFont.load_default()
text = random.choice(logo_list) # 🔹 ロゴパターンをランダムに選ぶ
text_size = draw.textbbox((0, 0), text, font=font)[2:]
max_x = size[0] - text_size[0]
max_y = size[1] - text_size[1]
pos = (random.randint(0, max_x), random.randint(0, max_y))
draw.text(pos, text, font=font, fill=(0, 0, 0))
# 全体に軽いノイズ(点状)を追加
np_img = np.array(img).astype(np.int16)
noise = np.random.randint(-20, 20, size=np_img.shape).astype(np.int16)
noisy_img = np.clip(np_img + noise, 0, 255).astype(np.uint8)
img = Image.fromarray(noisy_img)
# 軽いぼかしで“にじみ”を加える
img = img.filter(ImageFilter.GaussianBlur(radius=0.7))
return img
def generate_dataset(folder, logo_list, prefix="logo", count=10):
"""
指定フォルダに分類用画像を保存する関数
Parameters:
- folder: 画像を保存するベースフォルダ(例:"d:/DataSet/train")
- logo_list: ロゴ候補の文字列リスト(例:["◎◎◎", "ABCD", ...])
- prefix: ファイル名の先頭に付けるPrefix(例:"logo", "none")
- count: 生成する画像の枚数(例:100)
"""
os.makedirs(folder, exist_ok=True)
for i in range(count):
img = generate_image(path=None, logo_list=logo_list)
filename = f"{prefix}_{i}.jpg"
img.save(os.path.join(folder, filename))
# ================================================================================
# sampleデータの生成
# ================================================================================
gen_cnt=50 # 生成する枚数
root_folder=r"P:\logo_classification\dataset" # <== ご自身の環境に変更してください。
logo = ["◎AB◎"]
none = ["◎●◎●◎","◎◎◎◎","■■■■","■◎■◎","●●●●","ABCD","A◎B◎"]
# 修正例:順序を揃えて呼び出す
generate_dataset(os.path.join(root_folder, "train/logo"), logo, prefix="logo", count=gen_cnt)
generate_dataset(os.path.join(root_folder, "train/none"), none, prefix="none", count=gen_cnt)
generate_dataset(os.path.join(root_folder, "val/logo"), logo, prefix="logo", count=gen_cnt)
generate_dataset(os.path.join(root_folder, "val/none"), none, prefix="none", count=gen_cnt)
generate_dataset(os.path.join(root_folder, "test"), logo, prefix="logo", count=int(gen_cnt / 2))
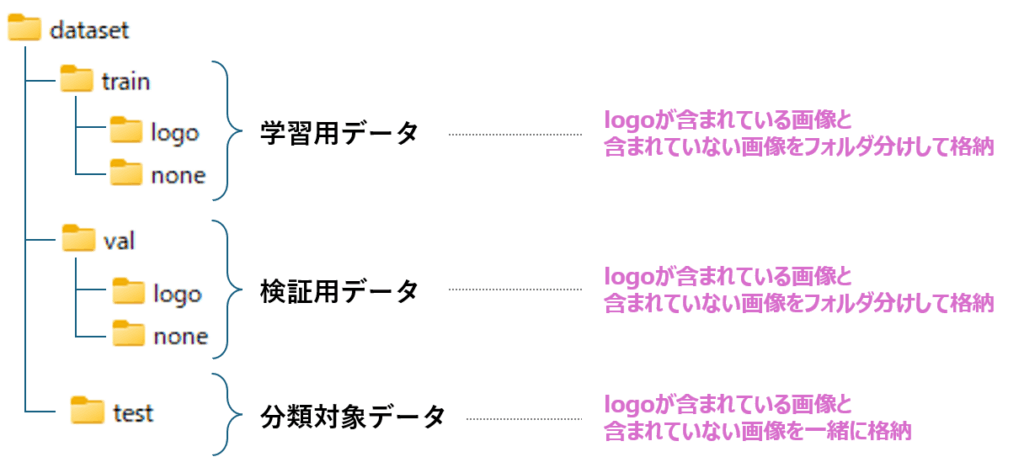
generate_dataset(os.path.join(root_folder, "test"), none, prefix="none", count=int(gen_cnt / 2))プログラムを実行すると、下記のフォルダ構成でデータが生成されます。
train と val は学習用のデータセットであるため、ロゴ有りとロゴ無しの画像がフォルダ分けして格納されます。
test は学習や検証に使われることはありませんが、学習済みモデルを使った分類のデモを目的として、ロゴ有りと無しの画像を1つのフォルダに保存しています。
ResNet画像分類の使い方
あらかじめ、下記のインストールをしておいてください。
pip install scikit-learn matplotlib seaborn
下記が学習と精度評価を行うサンプルプログラムです。前述のサンプルデータ作成プログラムで作成したフォルダを、26行目と27行目に指定します。
import torch
import torch.nn as nn
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import numpy as np
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
# ---------------------------------------
# デバイス設定(GPUが使えれば使用)
# ---------------------------------------
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("使用デバイス:", device)
# ---------------------------------------
# データ変換と読み込み
# ---------------------------------------
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# 学習データを格納したフォルダを指定
train_ds = datasets.ImageFolder(r"P:\logo_classification\dataset\train", transform=transform) # ← 環境に合わせて変更
# 検証データを格納したフォルダを指定
val_ds = datasets.ImageFolder(r"P:\logo_classification\dataset\val", transform=transform) # ← 環境に合わせて変更
train_loader = DataLoader(train_ds, batch_size=16, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=16)
# ---------------------------------------
# モデル構築(ResNet18 → 2クラス分類)
# ---------------------------------------
model = models.resnet18(pretrained=True)
model.fc = nn.Linear(model.fc.in_features, 2)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# ---------------------------------------
# 学習ループ(エポックあり)
# ---------------------------------------
num_epochs = 10 # ← 必要に応じて変更
train_losses = []
train_accuracies = []
val_accuracies = []
for epoch in range(num_epochs):
model.train()
running_loss = 0
correct = 0
total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
preds = torch.argmax(outputs, dim=1)
correct += (preds == labels).sum().item()
total += labels.size(0)
train_loss = running_loss / len(train_loader)
train_acc = correct / total
train_losses.append(train_loss)
train_accuracies.append(train_acc)
# 検証精度
correct = total = 0
model.eval()
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
preds = torch.argmax(outputs, dim=1)
correct += (preds == labels).sum().item()
total += labels.size(0)
val_acc = correct / total
val_accuracies.append(val_acc)
print(f"Epoch {epoch+1}/{num_epochs} | Loss: {train_loss:.4f} | Train Acc: {train_acc:.2%} | Val Acc: {val_acc:.2%}")
# ---------------------------------------
# モデル保存
# ---------------------------------------
torch.save(model.state_dict(), "model.pth")
print("\nモデルを model.pth に保存しました。")
# ---------------------------------------
# 検証セットでの詳細レポート+混同行列
# ---------------------------------------
y_true, y_pred = [], []
model.eval()
with torch.no_grad():
for images, labels in val_loader:
images = images.to(device)
outputs = model(images)
preds = torch.argmax(outputs, dim=1)
y_true.extend(labels.numpy())
y_pred.extend(preds.cpu().numpy()) # predsはGPU上のTensorなのでcpu()が必要
print("\n=== 混同行列 ===")
cm = confusion_matrix(y_true, y_pred)
print(cm)
print("\n=== レポート ===")
print(classification_report(y_true, y_pred, target_names=val_ds.classes))
# ---------------------------------------
# 学習曲線プロット(Loss / Accuracy)
# ---------------------------------------
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label="Train Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss")
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(train_accuracies, label="Train Accuracy")
plt.plot(val_accuracies, label="Val Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.title("Accuracy")
plt.legend()
plt.tight_layout()
plt.show()
# ---------------------------------------
# 混同行列のヒートマップ
# ---------------------------------------
labels = val_ds.classes
plt.figure(figsize=(5, 4))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=labels, yticklabels=labels)
plt.xlabel("予測ラベル")
plt.ylabel("正解ラベル")
plt.title("混同行列(Validation)")
plt.tight_layout()
plt.show()Epoch 1/10 | Loss: 0.6521 | Train Acc: 62.00% | Val Acc: 64.00%
Epoch 2/10 | Loss: 0.2044 | Train Acc: 90.00% | Val Acc: 67.00%
Epoch 3/10 | Loss: 0.0663 | Train Acc: 97.00% | Val Acc: 67.00%
Epoch 4/10 | Loss: 0.4674 | Train Acc: 99.00% | Val Acc: 73.00%
Epoch 5/10 | Loss: 0.1738 | Train Acc: 94.00% | Val Acc: 97.00%
Epoch 6/10 | Loss: 0.3677 | Train Acc: 95.00% | Val Acc: 81.00%
Epoch 7/10 | Loss: 0.0638 | Train Acc: 99.00% | Val Acc: 95.00%
Epoch 8/10 | Loss: 0.0579 | Train Acc: 99.00% | Val Acc: 88.00%
Epoch 9/10 | Loss: 0.0359 | Train Acc: 100.00% | Val Acc: 93.00%
Epoch 10/10 | Loss: 0.0184 | Train Acc: 100.00% | Val Acc: 96.00%
モデルを model.pth に保存しました。
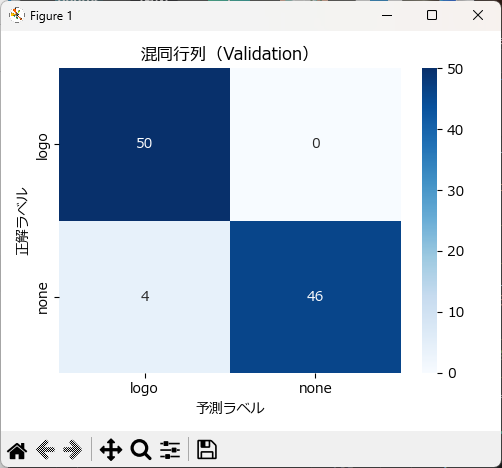
=== 混同行列 ===
[[50 0]
[ 4 46]]
=== レポート ===
precision recall f1-score support
logo 0.93 1.00 0.96 50
none 1.00 0.92 0.96 50
accuracy 0.96 100
macro avg 0.96 0.96 0.96 100
weighted avg 0.96 0.96 0.96 100
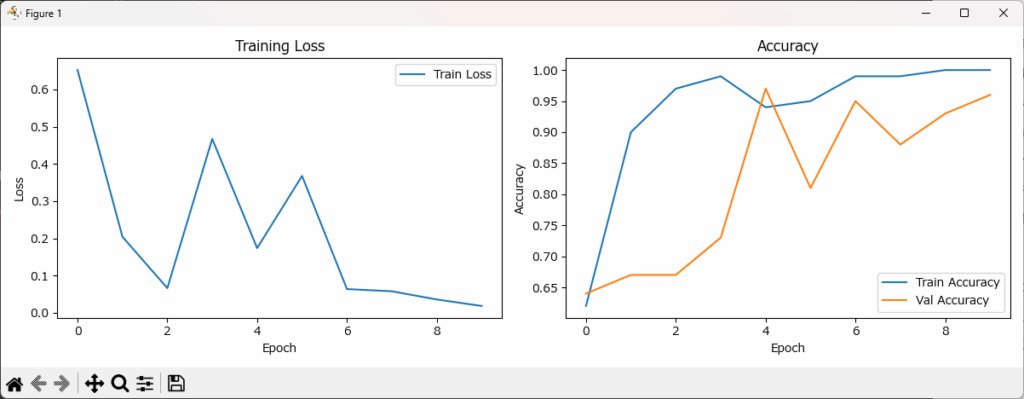
実行すると次の学習曲線グラフと混同行列のヒートマップが表示されます。同じデータであっても、毎回結果が異なるため、皆さんの実行結果のグラフとは違うかもしれませんが、ご了承ください。
左側の Training Loss(学習損失)を見ると、エポック6あたりから損失が収束し始めており、モデルが安定して学習できていることが分かります。
一方、右側の Accuracy(分類精度)では、学習データ(青線)の精度が同じくエポック6付近で高止まりし、それに続く形で検証データ(オレンジ線)の精度も緩やかに向上しています。
エポックを重ねるごとに両者の精度が揃って上昇しているため、過学習(=Val Accuracyの低下や Trainとの乖離)や、学習不足(=Train Accuracyの伸び悩み)といった問題は見られません。
さらに精度を向上させるためには、いくつかの工夫が考えられます。
たとえば、学習エポック数をもう数回延ばしてみることで、検証精度がさらに安定する可能性があります。
また、学習データに回転・ぼかし・明度変化などの拡張を加えることで、モデルの汎化能力を高めることも期待できます。
ResNet画像分類の便利クラス
ResNet による画像分類モデル作成において、必要な機能(学習、精度評価、モデルの保存と読み出し、新しいデータの分類)を一通り実装したクラス(LogoClassifier)を作成しました。
画像分類モデルの学習
学習は train() を使います。学習データのフォルダを data_dir に、検証データのフォルダを val_dir に指定することで、学習を行います。エポック数、バッチサイズ、 学習率は引数で指定可能です。
Parameters:
- data_dir (str): ImageFolder形式の学習データパス
- val_dir (str): ImageFolder形式の検証データパス(省略可)
- epochs (int): エポック数。(省略時は10)
- batch_size (int): バッチサイズ(省略時は8)
- lr (float): 学習率(省略時は 1e-4)
# インスタンスの生成
clf = LogoClassifier()
# 学習
clf.train(data_dir=r"P:\logo_classification\dataset/train",
val_dir=r"P:\logo_classification\dataset/val",
epochs=10)使用デバイス: cuda
Epoch 1/10: Loss=0.4536, Accuracy=80.00% | Val Accuracy=80.00%
Epoch 2/10: Loss=0.1867, Accuracy=93.00% | Val Accuracy=93.50%
Epoch 3/10: Loss=0.0516, Accuracy=99.00% | Val Accuracy=96.50%
Epoch 4/10: Loss=0.1209, Accuracy=97.50% | Val Accuracy=94.50%
Epoch 5/10: Loss=0.0815, Accuracy=97.50% | Val Accuracy=96.50%
Epoch 6/10: Loss=0.0579, Accuracy=98.00% | Val Accuracy=100.00%
Epoch 7/10: Loss=0.1033, Accuracy=97.00% | Val Accuracy=98.50%
Epoch 8/10: Loss=0.0444, Accuracy=98.50% | Val Accuracy=100.00%
Epoch 9/10: Loss=0.0924, Accuracy=97.00% | Val Accuracy=99.50%
Epoch 10/10: Loss=0.0516, Accuracy=99.00% | Val Accuracy=97.00%
学習完了(所要時間: 27.4 秒)
モデルの精度評価
evaluate() を使うことで、検証用データに対してモデルの分類性能を確認できます。
評価対象となる画像フォルダを data_dir に、クラス名のリストを class_names に指定します。
また、results には予測結果のCSVや混同行列を保存したいフォルダパスを指定できます。
Parameters:
- data_dir (str): ImageFolder形式の検証データが格納されたディレクトリ
- batch_size (int): DataLoaderのバッチサイズ(デフォルト: 8)
- class_names (list of str or None): クラス名リスト(インデックスに対応)。Noneなら整数で扱う。
- results (str): 評価結果(混同行列・分類曲線・CSV)を保存する出力フォルダパス
ちなみに、ここのbatch_size は推論時の処理を効率化するためなので、学習時の値に合わせる必要はありません。
# 評価
clf.evaluate(data_dir=r"P:\logo_classification\dataset\val",
class_names=["logo", "none"],results=r"P:\logo_classification\dataset\results")
この呼び出しにより、以下が実行されます。
- 検証精度の計算と表示(例: 97.5%)
- クラスごとの詳細な分類レポート(precision, recall, F1-score)
- 混同行列の描画と保存(confusion_matrix.png)
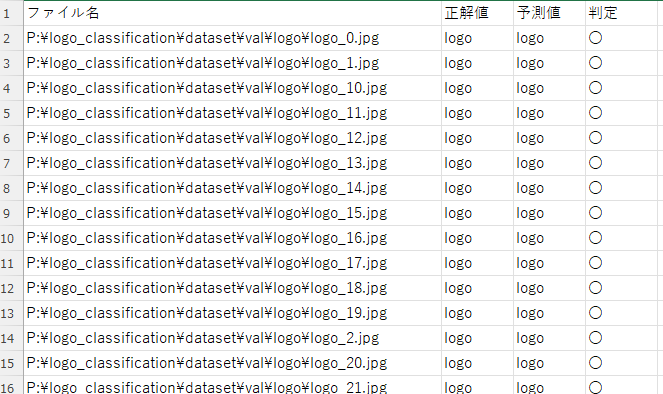
- 判定結果CSVの保存(val_result.csv)
評価精度: 97.00%
precision recall f1-score support
logo 0.94 1.00 0.97 100
none 1.00 0.94 0.97 100
accuracy 0.97 200
macro avg 0.97 0.97 0.97 200
weighted avg 0.97 0.97 0.97 200
results で指定したフォルダに、混合行列ヒートマップ、学習曲線、分類結果のCSVファイルが出力されます。


モデルの保存と読込
学習が完了したら、save() を使ってモデルを .pt ファイルとして保存できます。
後日再利用する際には load() を呼び出すことで、保存済みのモデルを復元できます。
保存時は自動的にディレクトリが作成され、読込後は .eval() モードに切り替わるため、すぐに予測や分類が可能な状態になります
# モデルの保存
clf.save(r"P:\logo_classification\dataset/logo_classifier.pt")
# モデルの読込
clf.load(r"P:\logo_classification\dataset/logo_classifier.pt")新しいファイルの分類
classify_folder() を使うことで、指定フォルダ内の画像を分類し、クラスごとのフォルダに自動振り分けできます。
分類対象の画像フォルダを input_dir に、出力先フォルダを output_dir に指定し、class_names には分類対象のクラス名(インデックス順)を渡します。
# 分類の実行
clf.classify_folder(
input_dir=r"P:\logo_classification\dataset\test",
output_dir=r"P:\logo_classification\result",
class_names=["logo", "none"]
)このコードにより、例えば test フォルダにある画像が以下のように振り分けられます。

クラスのソースコード全体
下記はLogoClassifierクラスの全ソースコードです。
import os
import torch
import torch.nn as nn
import pandas as pd
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
from sklearn.metrics import classification_report, confusion_matrix
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib import rcParams
import seaborn as sns
import shutil
import time
rcParams['font.family'] = 'Meiryo'
class LogoClassifier:
def __init__(self, num_classes=2, image_size=(224, 224), device=None):
"""
LogoClassifier クラスの初期化
Parameters:
- num_classes (int): 分類するクラスの数(デフォルトは2)
- image_size (tuple): 入力画像のサイズ(デフォルトは224×224)
- device (torch.device or None): 使用するデバイス(Noneの場合は自動判定)
処理内容:
- ResNet18 をベースとしたモデルを構築し、最終層を num_classes に合わせて再定義
- 指定デバイス(GPUまたはCPU)にモデルを移動
- 使用デバイスを標準出力に表示
"""
self.image_size = image_size
self.num_classes = num_classes
self.device = device or torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.model = models.resnet18(pretrained=True)
self.model.fc = nn.Linear(self.model.fc.in_features, num_classes)
self.model = self.model.to(self.device)
print(f"使用デバイス: {self.device}")
def train(self, data_dir, val_dir=None, epochs=10, batch_size=8, lr=1e-4):
"""
学習を実行。val_dir を指定すると各エポック後に検証精度も記録されます。
Parameters:
- data_dir (str): ImageFolder形式の学習データパス
- val_dir (str): ImageFolder形式の検証データパス(省略可)
- epochs (int): エポック数
- batch_size (int): バッチサイズ
- lr (float): 学習率
"""
transform = transforms.Compose([
transforms.Resize(self.image_size),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2),
transforms.ToTensor()
])
train_dataset = datasets.ImageFolder(data_dir, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = None
if val_dir:
val_dataset = datasets.ImageFolder(val_dir, transform=transforms.Compose([
transforms.Resize(self.image_size),
transforms.ToTensor()
]))
val_loader = DataLoader(val_dataset, batch_size=batch_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(self.model.parameters(), lr=lr)
self.train_losses = []
self.train_accuracies = []
self.val_accuracies = [] # ← ここが追加ポイント
start = time.time()
self.model.train()
for epoch in range(epochs):
running_loss = 0.0
correct = total = 0
for images, labels in train_loader:
images, labels = images.to(self.device), labels.to(self.device)
optimizer.zero_grad()
outputs = self.model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
preds = torch.argmax(outputs, 1)
correct += (preds == labels).sum().item()
total += labels.size(0)
avg_loss = running_loss / len(train_loader)
acc = correct / total
self.train_losses.append(avg_loss)
self.train_accuracies.append(acc)
log_msg = f"Epoch {epoch+1}/{epochs}: Loss={avg_loss:.4f}, Accuracy={acc:.2%}"
# バリデーション精度の記録(オプション)
if val_loader:
self.model.eval()
val_correct = val_total = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(self.device), labels.to(self.device)
outputs = self.model(images)
preds = torch.argmax(outputs, 1)
val_correct += (preds == labels).sum().item()
val_total += labels.size(0)
val_acc = val_correct / val_total
self.val_accuracies.append(val_acc)
log_msg += f" | Val Accuracy={val_acc:.2%}"
self.model.train()
else:
self.val_accuracies = []
print(log_msg)
print(f"学習完了(所要時間: {time.time() - start:.1f} 秒)")
def evaluate(self, data_dir, batch_size=8, class_names=None, results=None):
"""
検証用データセットに対して分類精度を評価し、結果を出力・保存します。
Parameters:
- data_dir (str): ImageFolder形式の検証データが格納されたディレクトリ
- batch_size (int): DataLoaderのバッチサイズ(デフォルト: 8)
- class_names (list of str or None): クラス名リスト(インデックスに対応)。Noneなら整数で扱う。
- results (str): 評価結果(混同行列・分類曲線・CSV)を保存する出力フォルダパス
処理内容:
- モデルを検証データで推論し、全体の精度を表示
- classification_report を標準出力に表示(class_names 指定時)
- 混同行列のヒートマップ画像を保存(confusion_matrix.png)
- 学習曲線をPNG画像として保存(training_curve.png)
- 各画像の正解・予測・判定結果をCSVとして保存(result.csv)
Returns:
- accuracy (float): 全体の分類精度(百分率)
"""
transform = transforms.Compose([
transforms.Resize(self.image_size),
transforms.ToTensor()
])
dataset = datasets.ImageFolder(data_dir, transform=transform)
loader = DataLoader(dataset, batch_size=batch_size)
correct = 0
total = 0
all_preds = []
all_labels = []
all_paths = []
self.model.eval()
with torch.no_grad():
for imgs, labels in loader:
imgs, labels = imgs.to(self.device), labels.to(self.device)
outputs = self.model(imgs)
_, preds = torch.max(outputs, 1)
correct += (preds == labels).sum().item()
total += labels.size(0)
all_preds += preds.cpu().numpy().tolist()
all_labels += labels.cpu().numpy().tolist()
all_paths += [p for p, _ in dataset.samples[len(all_paths):len(all_paths)+len(preds)]]
accuracy = 100 * correct / total
print(f"評価精度: {accuracy:.2f}%")
os.makedirs(results, exist_ok=True)
if class_names:
print("\n" + classification_report(all_labels, all_preds, target_names=class_names))
cm = confusion_matrix(all_labels, all_preds)
plt.figure(figsize=(6, 5))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues",
xticklabels=class_names, yticklabels=class_names)
plt.xlabel("Predicted")
plt.ylabel("True")
plt.title("Confusion Matrix")
plt.tight_layout()
plt.savefig(os.path.join(results,"confusion_matrix.png"))
self.plot_training_curve(os.path.join(results,"training_curve.png"))
df = pd.DataFrame({
"ファイル名": all_paths,
"正解値": [class_names[l] for l in all_labels],
"予測値": [class_names[p] for p in all_preds],
"判定": ["〇" if t == p else "×" for t, p in zip(all_labels, all_preds)]
})
df.to_csv(os.path.join(results,"result.csv"), index=False, encoding="shift-jis")
print(f"{results} に結果を保存しました")
return accuracy
def plot_training_curve(self,path=None):
"""
学習過程の損失と分類精度を可視化します。
Parameters:
- path (str or None): 保存パスを指定するとPNG画像として保存。Noneなら画面に表示。
描画内容:
- Train Loss(オレンジ)
- Train Accuracy(緑)
- Val Accuracy(青, 存在する場合)
注意:
- train() 実行後にのみ使用可能
"""
if not hasattr(self, 'train_losses') or not hasattr(self, 'train_accuracies'):
print("学習履歴が見つかりません。train() 実行後に使用してください。")
return
plt.figure(figsize=(12, 4))
# ─── 損失 ───
plt.subplot(1, 2, 1)
plt.plot(self.train_losses, label="Train Loss", color="orange")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("学習損失")
plt.grid(True)
plt.legend()
# ─── 精度 ───
plt.subplot(1, 2, 2)
plt.plot(self.train_accuracies, label="Train Accuracy", color="green")
if hasattr(self, 'val_accuracies') and self.val_accuracies:
plt.plot(self.val_accuracies, label="Val Accuracy", color="blue")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.title("分類精度")
plt.grid(True)
plt.legend()
plt.tight_layout()
if path:
plt.savefig(path)
else:
plt.show()
def save(self, model_path):
"""
学習済みモデルを指定パスに保存します。
Parameters:
- model_path (str): 保存先のファイルパス(例: "model/logo_classifier.pt")
備考:
- 保存前にCPUへ移動させ、保存後に再び self.device に戻します。
"""
os.makedirs(os.path.dirname(model_path), exist_ok=True)
self.model.cpu()
torch.save(self.model.state_dict(), model_path)
print(f"モデル保存済: {model_path}")
self.model = self.model.to(self.device)
def load(self, model_path):
"""
指定パスのモデルファイルを読み込み、使用可能な状態にします。
Parameters:
- model_path (str): 読み込むファイルのパス(例: "model/logo_classifier.pt")
"""
self.model.load_state_dict(torch.load(model_path, map_location=self.device))
self.model = self.model.to(self.device)
self.model.eval()
print(f"モデル読み込み済: {model_path}")
def predict(self, image_path, class_names=None):
"""
1枚の画像ファイルに対してクラス分類を実行します。
Parameters:
- image_path (str): 入力画像のファイルパス
- class_names (list or None): インデックスに対応するクラス名(省略時は数字で返す)
Returns:
- str or int: 推論されたクラス(ラベル名またはインデックス)
"""
transform = transforms.Compose([
transforms.Resize(self.image_size),
transforms.ToTensor()
])
img = Image.open(image_path).convert("RGB")
input_tensor = transform(img).unsqueeze(0).to(self.device)
self.model.eval()
with torch.no_grad():
output = self.model(input_tensor)
_, predicted = torch.max(output, 1)
class_index = predicted.item()
return class_names[class_index] if class_names else class_index
def classify_folder(self, input_dir, output_dir, class_names=None, extensions=("jpg", "jpeg", "png", "bmp", "tif", "tiff")):
"""
フォルダ内の画像をクラスごとに分類し、出力フォルダにコピー整理します。
Parameters:
- input_dir (str): 分類対象の画像が格納されたディレクトリ
- output_dir (str): 分類結果を保存するルートディレクトリ
- class_names (list of str): クラス名(インデックスに対応)
- extensions (tuple): 対象とする画像拡張子の一覧(デフォルトは一般的な画像形式)
出力例:
- output_dir/logo/xxx.jpg
- output_dir/none/yyy.png
"""
transform = transforms.Compose([
transforms.Resize(self.image_size),
transforms.ToTensor()
])
os.makedirs(output_dir, exist_ok=True)
for cname in class_names:
os.makedirs(os.path.join(output_dir, cname), exist_ok=True)
image_files = [f for f in os.listdir(input_dir) if f.lower().endswith(extensions)]
for fname in image_files:
path = os.path.join(input_dir, fname)
img = Image.open(path).convert("RGB")
input_tensor = transform(img).unsqueeze(0).to(self.device)
self.model.eval()
with torch.no_grad():
output = self.model(input_tensor)
_, pred = torch.max(output, 1)
predicted_class = class_names[pred.item()] if class_names else str(pred.item())
dest = os.path.join(output_dir, predicted_class, fname)
shutil.copy2(path, dest)
print(f">>> {fname} を {predicted_class} にコピーしました。")
まとめ
本記事では、古い設計図や技術資料に含まれる特定のマークやロゴを自動で識別するために、ResNetを用いた画像分類モデルの構築・評価方法を紹介しました。
特に以下の点がポイントです。
- ResNetの活用により、「ロゴがあるかないか」といったシンプルな2値分類が高精度に実現可能
- 自動データ生成スクリプト+学習・評価のための統合クラス(LogoClassifier)により、類似タスクへの応用が容易
- 分類結果の可視化(混同行列、学習曲線)やCSV出力により、業務での説明責任や精度検証にも対応しやすい
こうした仕組みを導入することで、大量のスキャン画像の中から特定の要素を自動で抽出・整理する作業が効率化され、現場のドキュメント管理やデジタルアーカイブ業務における大幅な工数削減が期待できます。
同様の課題をお持ちの方は、ぜひ本記事のコードや手法を参考にしてください。








コメント