
機機械設備の予兆検知といえば、真っ先に「振動センサーを用いたFFT(周波数解析)」を思い浮かべる方が多いでしょう。ベアリングの傷などを高周波のピークとして捉える、非常に強力で王道の手法です。
しかし、実際の製造現場やデータ分析の現場では、理想的なデータばかりではありません。以下のような壁にぶつかり、頭を抱えることが多々あります。
- サンプリングレートが低すぎる(PLCの仕様やネットワークの都合で、1Hz〜数Hzしかデータが取れない)
- データが振動ではない(温度、圧力、回転数、車速といったゆっくり変化する物理量しかない)
- 稼働状態が一定ではない(常に加減速を繰り返すため、定常状態の綺麗な波形が得られない)
実は、サンプリングレートが低くてFFTが使えない状況でも、時間波形のまま異常の芽を鋭く炙り出す実践的なアプローチがあります。それが今回ご紹介する「Rolling Window(移動窓)」を用いた特徴量抽出です。
本記事では、ただの移動平均や標準偏差にとどまらず、現場の「泥臭いデータ」から微小な異常を捉えるための強力な指標(波高率や移動エントロピーなど)を、Pythonの実装コード付きで分かりやすく解説します。
但し、FFTでも使い方を割り切れば予兆検知にも使えますので、興味のある方は是非下記の記事をご一読ください。

Rolling Window(移動窓)とは
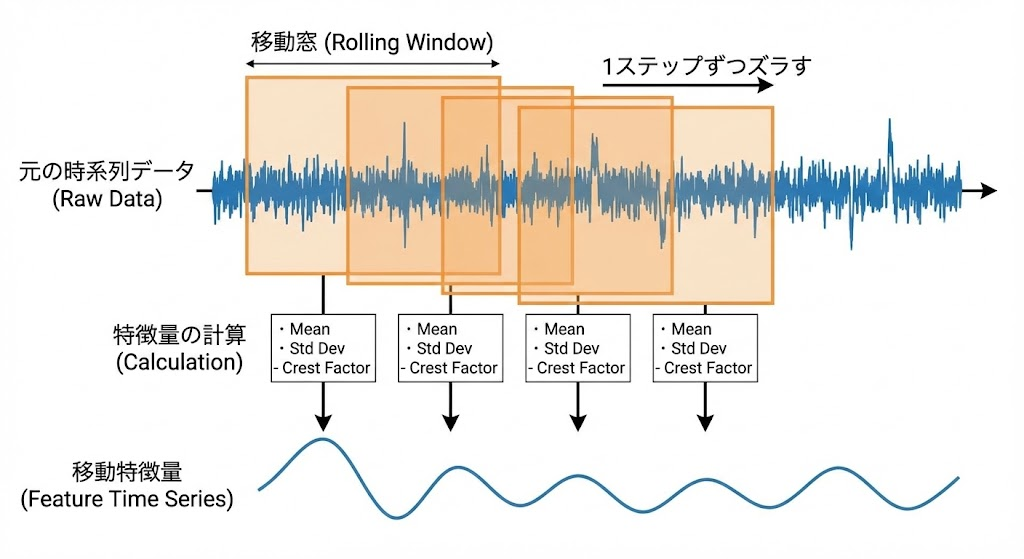
Rolling Window(移動窓)とは、時系列データに対して「一定の区間(窓)を少しずつズラしながら、その区間内のデータを使って統計量などを計算し続ける手法」です。
FFTが使えないほどサンプリングレートが低いデータであっても、直近のN点(窓幅)を切り出すこの「移動窓処理」を使うことで、ノイズに埋もれた波形の『性格の変化』を的確に抽出することが可能になります。
なぜ予兆検知に必要なのか?
設備データから異常の予兆を捉える際、1日分や1バッチ分といった「データ全体の平均や分散」を一度に計算してしまうと、「ごく最近発生した微小な異常」が、過去の正常な大量のデータに薄められて消えてしまいます。
移動窓を使うことで、以下のような絶大なメリットが生まれます。
- 「波形の性格」の変化を時系列で追える
「直近100データ分の波形の暴れ具合(分散)」や「直近100データ分の乱雑さ(エントロピー)」を連続して計算することで、「ついさっきから急にガタつき始めた」といった状態の変化を、新たな1つの波形としてグラフ化できます。 - 突発的なノイズに騙されない
センサー特有の「1点だけポツンと跳ねる通信ノイズ」に過剰反応することなく、実質的なトレンドや、塊としての異常だけを安定して検知できるようになります。
Rolling Windowは生データをそのまま監視するのではなく、「波形の性格(特徴)が、時間とともにどう変化しているか」を抽出するための強力なフィルターとして機能します。
Rolling Windowで用いる計算式とは
サンプリングレートが低いデータにおいては、波形を単なる「点(数値)の集まり」として見るのではなく、「意味を持った塊(性質)」として捉える必要があります。
そのため、分析目的に応じて特定の計算式を使い分け、データに潜む特徴を抽出します。こうして算出された値を「特徴量」と呼び、これによってデータの状態や変化を客観的に評価することが可能になります。
具体的には、以下の4つの観点から波形の性質を数値化します。各指標はデータのどの側面を捉えるかに応じて、大きく『トレンド』『ばらつき』『衝撃』『乱れ』のカテゴリに分類されます。
| カテゴリ | 手法 | 主な用途・捉えられる変化 |
|---|---|---|
| ① トレンド・代表値 | 移動平均 (Mean) | 全体的な推移、低周波な変動の把握 |
| 移動中央値 (Median) | 外れ値に影響されない趨勢の把握 | |
| 移動最大/最小 (Max/Min) | データの限界値、レンジの境界監視 | |
| 移動95%値 | 突発的なノイズを除いた実質的な最大値(ロバスト最大) | |
| ② ばらつき・エネルギー | 移動標準偏差 (Std) | データの散らばり具合、不安定さの検知 |
| 移動範囲 (Range) | 最大値と最小値の差。変動幅の単純比較 | |
| 移動相対レンジ | 平均や中央値に対する変動幅の比率 | |
| 移動実効値 (RMS) | 信号の物理的なエネルギー(強さ)の測定 | |
| 移動総変動 | 波形の「道のり」の長さ。激しい上下動の蓄積 | |
| ③ 突発的な衝撃(スパイク) | 波高率 (Crest Factor) | 平均的な強さに対する衝撃の鋭さ(摩耗・損傷など) |
| 移動歪度 (Skewness) | 分布の左右非対称性。波形の偏りの発生 | |
| 移動尖度 (Kurtosis) | 分布の尖り具合。突発的なスパイク(衝撃)の発生 | |
| ④ 乱れ・周期性 | 移動エントロピー | 波形の「予測しにくさ・複雑さ」。不規則な乱れの検知 |
| 符号変化率 (ZCR) | 波形が中心線を横切る頻度。周波数変化の簡易指標 | |
| 自己相関 (Lag-1) | 直前の値との相関。周期性の崩れやパターンの変化 |
代表的な特徴量計算の具体例(単変量)
この章では、カテゴリの中から最も効果が高いものを厳選して紹介します。
下記はサンプルデータとグラフ描画のソースコードです。以降に紹介するサンプルコードを末尾に張り付けて実行すると、本記事に掲載しているグラフが描画されます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import entropy
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
# ---------------------------------------------------------
# 1. 共通のダミーデータ生成関数(3つの異常を仕込む)
# ---------------------------------------------------------
def generate_dummy_data(n=800):
np.random.seed(42)
t = np.linspace(0, 100, n)
# ベースライン: 正常な稼働波形 (サイン波 + 軽いノイズ)
base_wave = np.sin(t)
noise = np.random.normal(0, 0.2, n)
data = base_wave + noise
# 【異常①】突発的なショック (t=200, 250付近)
data[200] += 4.0
data[250] -= 3.5
# 【異常②】部品の劣化によるガタつき増大 (t=400〜550)
data[400:550] += np.random.normal(0, 0.8, 150)
# 【異常③】パッキン劣化等による微小なドリフト (t=600以降)
data[600:] += 0.5 # ベースラインが0.5だけ浮き上がる
return pd.DataFrame({'sensor_val': data})
# ---------------------------------------------------------
# 2. 共通のグラフ描画関数(生データと特徴量を上下に並べる)
# ---------------------------------------------------------
def plot_feature(df, feature_col, title, color='blue'):
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 5), sharex=True)
# 上段:生データ
ax1.plot(df['sensor_val'], color='gray', alpha=0.7)
ax1.set_title("Raw Data (生データ:3つの異常が潜んでいます)")
# 異常区間のハイライト(読者に分かりやすくするため)
ax1.axvspan(190, 260, color='red', alpha=0.1, label='①突発ショック')
ax1.axvspan(400, 550, color='orange', alpha=0.1, label='②ガタつき増大')
ax1.axvspan(600, 800, color='green', alpha=0.1, label='③微小ドリフト')
ax1.legend(loc='upper left')
# 下段:計算した特徴量
ax2.plot(df[feature_col], color=color, linewidth=2)
ax2.set_title(title)
plt.tight_layout()
plt.show()
# ▼▼▼▼▼▼▼▼▼===================▼▼▼▼▼▼▼▼▼==================▼▼▼▼▼▼▼▼▼
# ここに、以降に紹介するサンプルソースコードを貼り付けて実行してください。
トレンド系の代表:ノイズに強い「移動95%値(ロバスト最大)」
単純なMax(最大値)は、1点のスパイクノイズでアラートが鳴ってしまいます。そこで、窓内のデータを並び替えて「上から5%の位置にある値」を実質的な最大値として使います。
ノイズを無視しつつ、高負荷側の異常な底上げを安定して捉えられます。
# 特徴量の計算関数
def calc_rolling_95pct(df, window_size=30):
df_calc = df.copy()
# ノイズを無視して実質的な最大値(高負荷側への底上げ)を捉える
df_calc['rolling_95pct'] = df_calc['sensor_val'].rolling(window=window_size).quantile(0.95)
return df_calc
# 実行とグラフ化
df = generate_dummy_data()
df_result = calc_rolling_95pct(df)
plot_feature(df_result, 'rolling_95pct', "移動95%値 (③微小ドリフトによるベース上昇に反応)", color='red')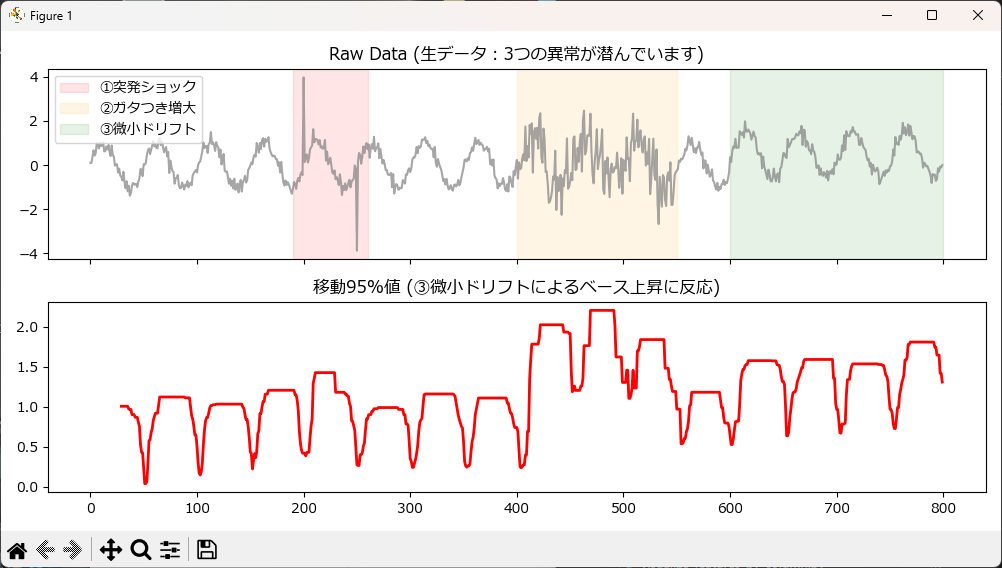
ばらつき系の代表:異常検知の基本「移動標準偏差(Std)」
シンプルですが、データの「暴れ具合(分散)」を見る基本中の基本です。
摩耗や劣化によって部品の「ガタつき」が大きくなると、平均値(トレンド)は変わらなくても、この標準偏差がジワジワと上昇を始めます。
# 特徴量の計算関数
def calc_rolling_std(df, window_size=30):
df_calc = df.copy()
# 波形の「暴れ具合」を捉える
df_calc['rolling_std'] = df_calc['sensor_val'].rolling(window=window_size).std()
return df_calc
# 実行とグラフ化
df = generate_dummy_data()
df_result = calc_rolling_std(df)
plot_feature(df_result, 'rolling_std', "移動標準偏差 (②ガタつき増大の区間だけが綺麗に浮き上がる)", color='blue')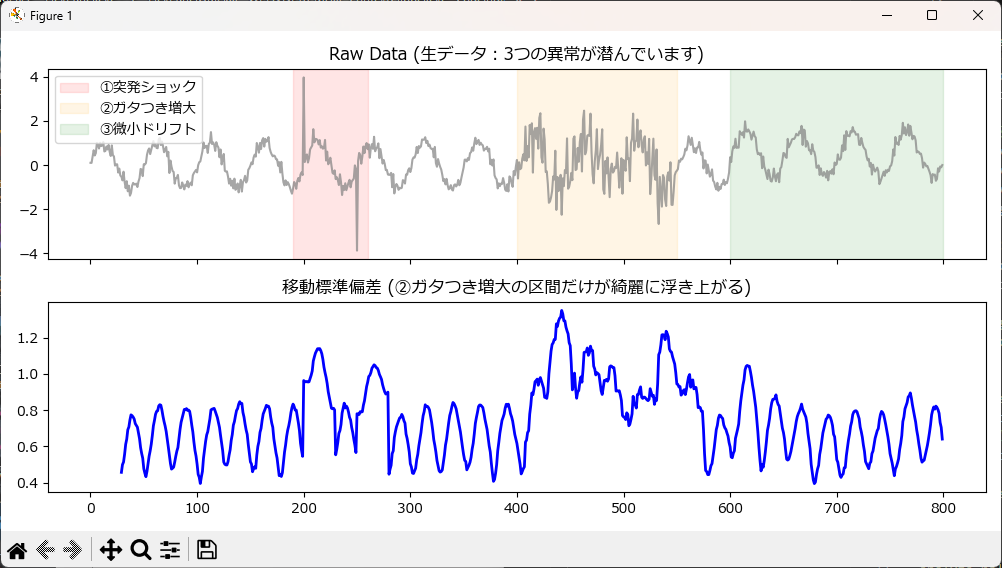
衝撃系の代表:突発的な引っ掛かりを捉える「波高率(クレストファクタ)」
ベアリングやギアの初期摩耗など、「普段は滑らかなのに、たまにカチンッと引っ掛かる」ような異常を捉える最強の指標です。
窓内の「最大絶対値」を「実効値(RMS)」で割ります。全体の振幅が変わらなくても、一瞬のピークが混じるだけで鋭く跳ね上がります。
# 特徴量の計算関数
def calc_crest_factor(df, window_size=30):
df_calc = df.copy()
# 最大絶対値 ÷ 実効値(RMS)
def _crest(x):
rms = np.sqrt(np.mean(x**2))
return 0 if rms == 0 else np.max(np.abs(x)) / rms
df_calc['crest_factor'] = df_calc['sensor_val'].rolling(window=window_size).apply(_crest, raw=True)
return df_calc
# 実行とグラフ化
df = generate_dummy_data()
df_result = calc_crest_factor(df)
plot_feature(df_result, 'crest_factor', "波高率 (①突発的なショックにだけ鋭く反応)", color='orange')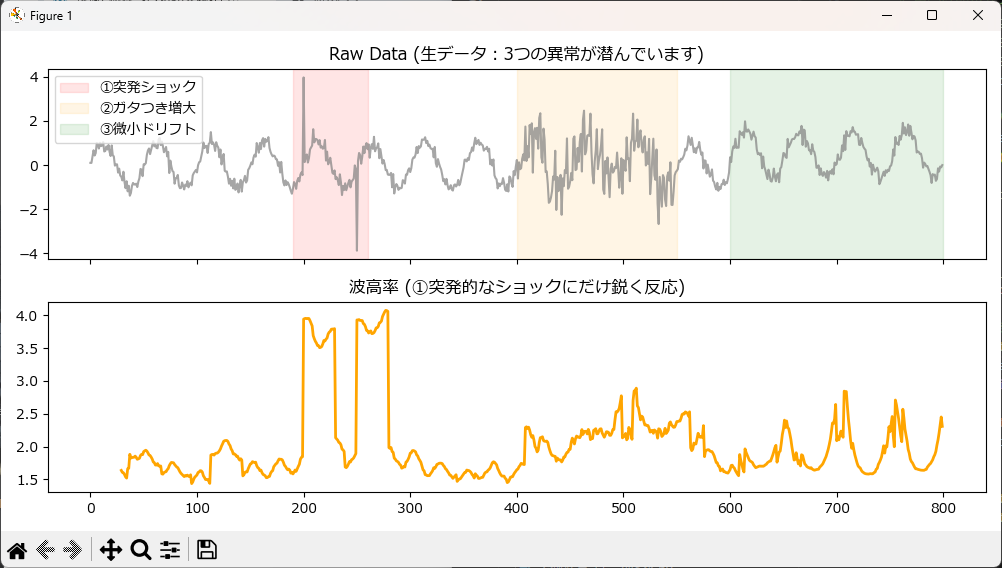
乱れ系の代表:波形の不規則さを捉える「移動エントロピー」
部品の劣化が進み、予測不可能な微小ノイズが乗るようになると、振幅自体の大きさは変わらなくても「乱雑さ」が増します。
窓内のヒストグラムからシャノンエントロピーを計算します。逆に、油圧バルブが固着して波形がのっぺりした時はエントロピーが低下するため、動作不良の検知にも使えます。
# 特徴量の計算関数
def calc_rolling_entropy(df, window_size=30):
df_calc = df.copy()
# ヒストグラムからシャノンエントロピーを計算
def _entropy(x, bins=10):
counts, _ = np.histogram(x, bins=bins)
return entropy(counts)
df_calc['rolling_entropy'] = df_calc['sensor_val'].rolling(window=window_size).apply(_entropy, raw=True)
return df_calc
# 実行とグラフ化
df = generate_dummy_data()
df_result = calc_rolling_entropy(df)
plot_feature(df_result, 'rolling_entropy', "移動エントロピー (②ガタつきによる波形の乱れを検知)", color='purple')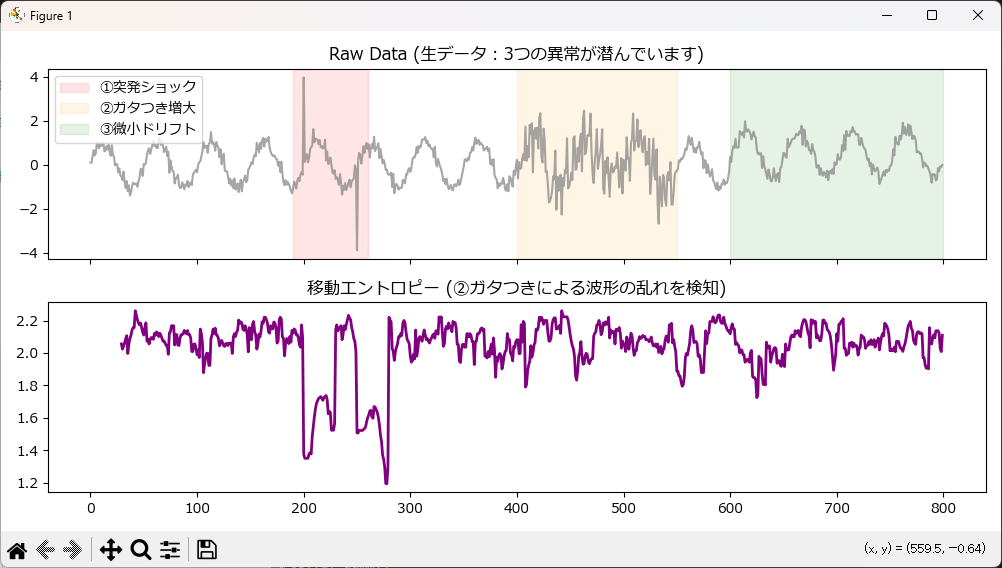
【番外編】微小な異常の蓄積を捉える「CUSUM(累積和)」
これは移動窓(直近の記憶)ではなく、過去からのズレを「蓄積(長期記憶)」し続ける特殊な手法です。
効果: 「毎回0.1℃だけ基準より高い」といった、移動平均ではノイズに埋もれてしまう微小な進行性異常(ドリフト)を、右肩上がりのグラフとして強烈に可視化します。
# 特徴量の計算関数
def calc_cusum(df):
df_calc = df.copy()
# 正常時(最初の100データ)の平均値を基準に、ズレを累積していく
baseline_mean = df_calc['sensor_val'][:100].mean()
df_calc['cusum'] = (df_calc['sensor_val'] - baseline_mean).cumsum()
return df_calc
# 実行とグラフ化
df = generate_dummy_data()
df_result = calc_cusum(df)
plot_feature(df_result, 'cusum', "CUSUM (③微小ドリフトが蓄積し、右肩上がりのトレンドになる)", color='green')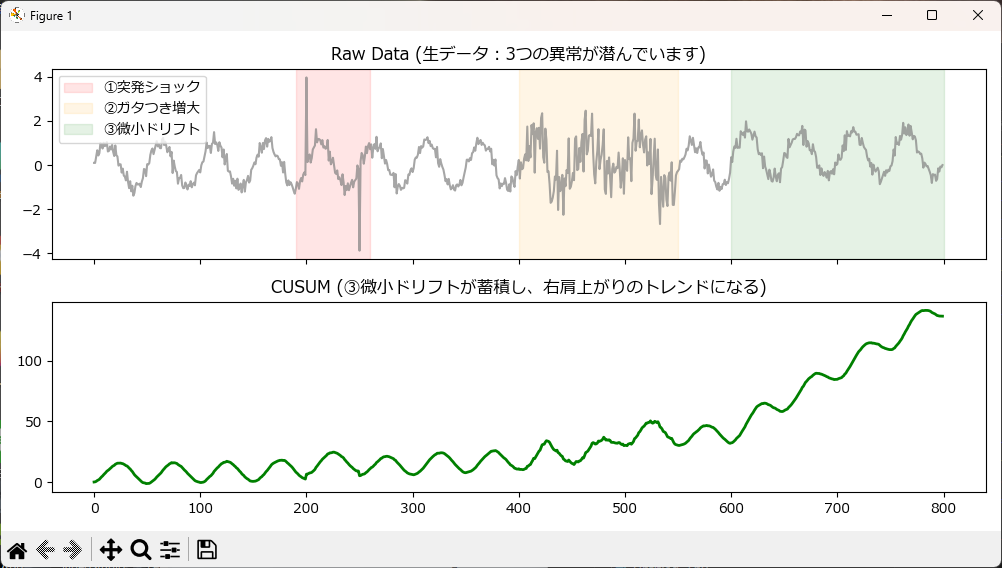
代表的な特徴量計算の具体例(多変量)
ここまで、1つのセンサーデータ(単変量)に対してRolling Windowを適用し、波形の「性格」から異常の予兆を捉える手法をご紹介しました。常に一定のスピードで動き続ける装置であれば、これだけでも十分な威力を発揮します。
しかし、実際の製造現場では「常に加減速を繰り返す」「加工する製品によって負荷が変わる」といったケースがほとんどです。
稼働状態が変わると、当然センサーの値も変動します。単一のセンサーだけを見ていると、「温度が上がったのは、冷却系の異常発熱なのか? それとも単に装置のスピードを上げて頑張っているからなのか?」の区別がつきません。単変量の特徴量(移動標準偏差など)も、稼働スピードの変化につられて一緒に変動してしまうため、固定の閾値でアラートを鳴らすのが難しくなります。
複数のセンサーは1つに束ねて「代表値」に変える
この壁を突破するには、1つのセンサーを深く掘り下げるのではなく、複数のセンサーを束ねて監視する「多変量解析」のアプローチが必要になります。
これは、速度、加速度、回転数、温度といった複数のパラメーターの"いつものバランス"(相関関係)を評価し、「正常な関係性からどれくらい崩れているか」を1つの代表値(異常スコア)に圧縮する考え方です。代表的な手法として、以下のような計算アルゴリズムがあります。
- マハラノビス距離
複数のセンサーデータを多次元空間にプロットし、正常稼働時の「いつものデータの群れ」からどれくらい逸脱しているかを計算する王道手法です。 - PCA再構成誤差(主成分分析)
正常時のセンサー間の「連動ルール」を学習し、新しいデータを一度圧縮・復元して、元データとのズレ(Q統計量)を計算します。「値自体は正常範囲内だけど、車速は上がっているのに回転数だけが普段と違う」といった関係性の崩れに極めてシャープに反応します。
束ねた代表値に「Rolling Window」手法を適用する
複数のセンサーから相関を表す代表値に変換してしまえば、あとは本記事で紹介した「Rolling Window」手法を活用して、異常や予兆をあぶり出すことができるようになります。
複数のセンサーを1つに束ねるためのアルゴリズムの詳細とサンプルコードについては、「【Python実践】複雑な相関関係は「次元削減」で解決!予兆検知のための多変量⇒単変量変換アプローチ」で紹介しています。

まとめ
FFTが使えない低周期データでも、時間波形の中には確実に故障の予兆が隠れている可能性があります。
「移動窓」を使ってノイズに埋もれた波形の性格を炙り出し、さらに「多変量解析」でセンサー間の関係性を束ねる。このアプローチを組み合わせれば、機械が発する「以前より苦しそうに動いている」というSOSのサインを、捉えることができます。
低周期データで予兆検知に取り組まれる方は、是非本記事を参考にしてください。





コメント