
HDBSCANは、密度に基づいてデータをグループ化するアルゴリズムで、DBSCANをさらに進化させた手法です。ノイズに強いという特徴はそのままに、「データの密度の違いを自動で判別する」という非常に強力な機能を持っています。
製造業では、センサーから得られる複雑な振動データをHDBSCANで分析し、正常な状態からわずかに外れた「予兆」を、パラメータ調整の手間なく高精度に検知することが可能です。異常検知や設備の故障予兆の分析、品質管理において、従来のDBSCAN以上に柔軟な活用が期待されています。
この記事では、製造現場でのHDBSCANの活用メリットを紹介し、アルゴリズムの仕組みや実装方法を解説します。 すぐに実践したい方のために、DBSCAN版をさらに強化した「コピペで使える自作クラス」も公開していますので、ぜひご一読ください。
HDBSCANとは
HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)は、密度ベースのクラスタリング手法として有名なDBSCANの考え方に「階層構造(Hierarchical)」を取り入れたアルゴリズムです。2013年にRicardo Campelloらによって提案されました。
DBSCANの「密度が高い場所をクラスターとする」という良さを引き継ぎつつ、「密度の濃淡がバラバラなデータでも、それぞれの密度に合わせて自動でクラスターを切り出す」ことができる、より実用的な進化を遂げています。
アルゴリズムの概要
HDBSCANは、一言で言えば「データのつながりやすさを変えながら、家系図(デンドログラム)を作る」手法です。
- 相互到達距離の計算
各ポイントの密度(周囲の点までの距離)を計算し、密度の低い(離れた)ポイント同士をより「遠い」と見なすように距離を補正します。 - 最小全域木(MST)の構築
補正された距離に基づき、すべての点を結ぶ最も効率的なネットワークを作ります。 - 階層構造の作成(デンドログラム)
距離が近い順にポイントを結合していき、大きな「家系図」のような階層構造を構築します。 - クラスターの抽出(安定性の計算)
家系図を上から下へ見ていき、設定したmin_cluster_sizeより小さい枝はノイズとして切り捨てます。残った枝の中で、「広い距離の範囲にわたって、分裂せずに存在し続けている塊(安定性が高いもの)」を最終的なクラスターとして選定します。
HDBSCANのメリット
- 密度の違いを自動調整
DBSCANのように「半径 ε」を固定しないため、ギュッと詰まったグループと、ふわっと広がったグループが混在していても同時に検出できます。 - パラメータ設定が極めてシンプル
実質的に調整が必要なのは「最小クラスターサイズ(min_cluster_size)」のみで、DBSCAN最大の悩みだった「最適な半径の探索」から解放されます。 - 「確信度」がわかる
各データポイントがどの程度そのクラスターに属しているか(メンバーシップ確率)を算出できるため、より詳細な分析が可能です。
HDBSCANの課題
- 計算コスト(メモリ消費)
DBSCANと比較して、階層構造を作るための計算量やメモリ消費が多くなる傾向があります。数百万件を超えるような超大規模データでは工夫が必要です。 - 境界の扱いの変化
DBSCANの「境界ポイント」という概念がなくなり、少しでも密度が低い点は「ノイズ(外れ値)」として厳格に分類される傾向があります(これはメリットでもあります)。
クラスタリングに必要なモジュールのインストール
HDBSCANを実装するには、Python環境に加えて hdbscan ライブラリが必要です。以下のコマンドで、必要なライブラリを一括でインストールできます。
pip install hdbscan
pip install scikit-learn
pip install numpy
pip install pandas
pip install matplotlib
HDBSCANを使ったクラスタリングの実装例
HDBSCANは、DBSCANと同様にデータの距離(密度)を計算するため、事前に標準化や正規化を行ってスケールを整える前処理が非常に重要です。また、高次元すぎるデータ(特徴量が数十個以上)の場合は、主成分分析(PCA)などで次元削減を行ってから適用すると計算効率と精度が向上します。
HDBSCANでは、主なパラメータとして「クラスターを構成する最小のデータ数(min_cluster_size)」を指定します。DBSCANのように「半径 $\epsilon$」を細かく調整する必要がないため、初めてデータに触れる際でも非常に扱いやすいのが特徴です。
例えば、min_cluster_size=2 と設定した場合、2つ以上のデータが「安定した塊」として存在すればクラスターとして認識され、それ以外はノイズとして分類されます。
import hdbscan
import numpy as np
# 5個の説明変数を持つ6組分のテストデータを生成
data = [
[5.1, 3.5, 1.4, 0.2, 0.3],
[4.9, 3.0, 1.4, 0.2, 0.4],
[4.7, 3.2, 1.3, 0.2, 0.3],
[4.5, 3.1, 1.5, 0.2, 0.3],
[5.0, 3.6, 1.4, 0.2, 0.4],
[4.6, 3.1, 1.3, 0.2, 0.3]
]
# HDBSCANクラスタリングの実行
# min_cluster_size: クラスターとして認める最小の点数
clusterer = hdbscan.HDBSCAN(min_cluster_size=2)
labels = clusterer.fit_predict(data)
# 各ポイントの「確信度」(どれだけしっかりクラスターに属しているか)
probabilities = clusterer.probabilities_
print("====分類結果====")
print(labels)
print("====各データの確信度 (0.0~1.0)====")
print(probabilities)下記は分類結果です。DBSCAN同様、クラスタリングできない外れ値には -1(ノイズ)のラベルが付きます。 また、HDBSCAN特有の probabilities_ を見ることで、そのデータが「自信を持ってそのクラスターと言えるか」を数値で確認できます。
====分類結果====
[-1 -1 -1 -1 -1 -1]
====各データの確信度 (0.0~1.0)====
[0. 0. 0. 0. 0. 0.]
パラメータ設定について
HDBSCANは多くの計算を自動で行いますが、以下の2つのパラメータを調整することで、現場の感覚に合ったクラスタリングが可能になります。
| パラメータ名 | 説明 |
|---|---|
| min_cluster_size | 最も重要なパラメータ。 クラスターとして認める最小のデータ数です。例えば「5」に設定すると、4つ以下の塊はすべてノイズ(外れ値)として処理されます。 |
| min_samples | クラスターの「保守さ」を決定します。値を大きくするほどノイズ判定が厳しくなり、より密度の高い中心部分だけがクラスターとして残ります。省略した場合は min_cluster_size と同じ値になります。 |
パラメータ選定の考え方
DBSCANでは「k距離プロット」で最適な半径を探しましたが、HDBSCANでは「その現象が何個以上のデータで発生したら意味があるか」というビジネス視点で min_cluster_size を決めるのが基本です。
階層構造の可視化(Dendrogram / Condense Tree)
DBSCANの「エルボー法」に代わるものとして、HDBSCANでは階層構造を可視化します。どの程度の「安定性」でクラスターが切り出されているかを確認できます。
import hdbscan
import matplotlib.pyplot as plt
import numpy as np
# 1. 離れた2つのグループ(各10点、計20点)を生成
group1 = np.random.normal(loc=0.0, scale=0.1, size=(10, 5))
group2 = np.random.normal(loc=5.0, scale=0.1, size=(10, 5))
data = np.vstack([group1, group2])
# 2. min_cluster_sizeを小さく設定(データ規模に合わせる)
clusterer = hdbscan.HDBSCAN(min_cluster_size=3, gen_min_span_tree=True)
clusterer.fit(data)
# 3. 描画
clusterer.condensed_tree_.plot(select_clusters=True)
plt.show()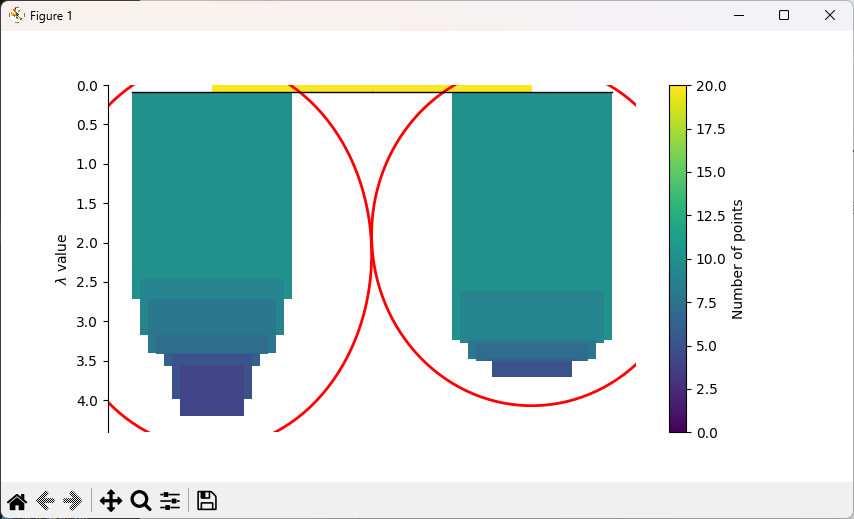
シルエットスコア(Silhouette Score)
DBSCAN同様、クラスタリングの品質を測る指標として利用できます。HDBSCANでは $\epsilon$ の代わりに min_cluster_size を動かして最適なスコアを探します。
import numpy as np
import hdbscan
from sklearn.metrics import silhouette_score
group1 = np.random.normal(loc=0.0, scale=0.1, size=(10, 5))
group2 = np.random.normal(loc=5.0, scale=0.1, size=(10, 5))
data = np.vstack([group1, group2])
# min_cluster_sizeの候補
size_values = range(2, 11)
best_size = 0
best_score = -1
for size in size_values:
clusterer = hdbscan.HDBSCAN(min_cluster_size=size)
labels = clusterer.fit_predict(data)
# クラスターが2つ以上(ノイズを除く)ある場合のみ評価
if len(set(labels[labels != -1])) > 1:
score = silhouette_score(data, labels)
if score > best_score:
best_score = score
best_size = size
print(f"最適なmin_cluster_size: {best_size}, シルエットスコア: {best_score}")最適なmin_cluster_size: 2, シルエットスコア: 0.9745545893478518
- ノイズが多すぎる場合
min_samplesを小さくすると、境界付近のデータがクラスターに取り込まれやすくなります。 - クラスターが細かすぎる場合
min_cluster_sizeを大きくして、より大きな塊だけを抽出するようにします。 - スコアが低い場合
シルエットスコアは「球状のクラスター」を高く評価する傾向があるため、HDBSCANのような密度ベースの手法ではスコアが低くても「実態に即した良い分類」ができていることが多々あります。可視化結果と併せて判断しましょう。
可視化
HDBSCANのクラスタリング結果を可視化することで、データの分布や異常値(ノイズ)の判定基準を直感的に理解できます。ここでは2次元・3次元のプロットに加え、高次元データをPCA(主成分分析)で圧縮して可視化する方法を紹介します。
2次元データのクラスタリング結果を可視化
HDBSCANの非常に強力な機能の一つに、各データがそのクラスターに属する「確信度(probabilities_)」を算出できる点があります。
従来のクラスタリングでは「属するか、属さないか」の二択(ハードクラスタリング)でしたが、HDBSCANは「どれくらい確実にそのグループと言えるか」を0.0〜1.0の数値で教えてくれます。
- 確信度が高い点(1.0に近い): クラスターの「核」となる安定したデータ。
- 確信度が低い点(0.0に近い): クラスターの縁(ふち)にあり、ノイズに近い不安定なデータ。
これをグラフ上の「点の大きさ」として表現することで、単なる色分け以上の情報を読み取ることができます。例えば、製造ラインのデータにおいて「色はクラスター0(正常)だけど、点が極端に小さい」ものがあれば、それは「正常グループの端っこにいる、異常の予兆かもしれないデータ」として注意を向けることができます。
下記は、2次元のダミーデータを分類するサンプルプログラムです。
import hdbscan
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
# 1. 2次元のテストデータを生成(密度とバラツキが異なる2つの塊)
np.random.seed(0)
# クラスター0:ギュッと詰まった塊
cluster_dense = np.random.normal(loc=[1, 1], scale=0.1, size=(50, 2))
# クラスター1:ふわっと広がった塊
cluster_sparse = np.random.normal(loc=[-1, -1], scale=0.5, size=(50, 2))
# ノイズ:どこにも属さない点
noise = np.random.uniform(low=-2, high=2, size=(10, 2))
data_2d = np.vstack([cluster_dense, cluster_sparse, noise])
# 2. HDBSCANの実行
clusterer = hdbscan.HDBSCAN(min_cluster_size=5)
labels = clusterer.fit_predict(data_2d)
probs = clusterer.probabilities_ # 確信度を取得
# 3. 可視化
plt.figure(figsize=(10, 7))
unique_labels = set(labels)
colors = plt.cm.get_cmap("Set1")(np.linspace(0, 1, len(unique_labels)))
for k, col in zip(unique_labels, colors):
if k == -1:
col = 'lightgray'
label = 'ノイズ'
else:
label = f'クラスター {k}'
mask = (labels == k)
# ポイント:s(サイズ)に確信度を反映
plt.scatter(data_2d[mask, 0], data_2d[mask, 1], c=[col], label=label,
s=probs[mask]*120 + 20, edgecolors='k', alpha=0.6)
plt.title('HDBSCAN 2D可視化:密度の異なるクラスターの同時検出')
plt.xlabel('変数 A')
plt.ylabel('変数 B')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()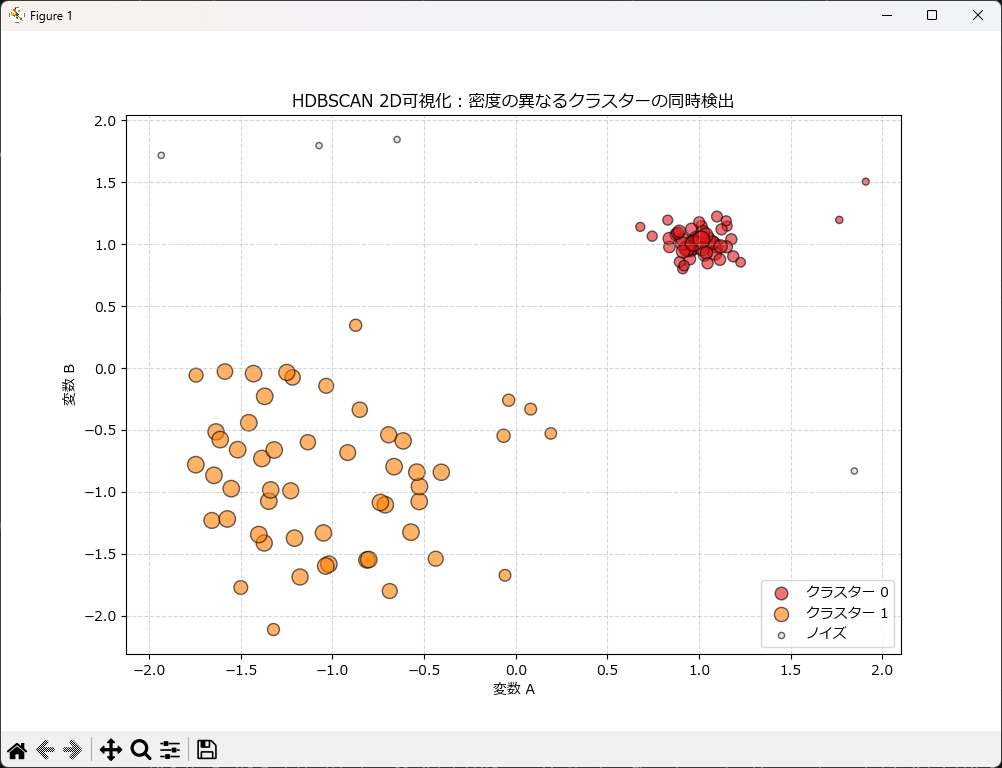
3次元データのクラスタリング結果を可視化
高さ・幅・奥行きを持つ空間に浮かぶ「データの塊」をHDBSCANがどう捉えるかを確認します。
下記は、密度がバラバラな3つの塊を生成し、HDBSCANで分類するサンプルプログラムです。
import hdbscan
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
# 1. 3次元空間に3つのクラスターを生成(各30点、合計90点)
np.random.seed(42)
group1 = np.random.normal(loc=[1, 1, 1], scale=0.2, size=(30, 3))
group2 = np.random.normal(loc=[3, 3, 3], scale=0.5, size=(30, 3)) # 少し広がった塊
group3 = np.random.normal(loc=[5, 1, 3], scale=0.3, size=(30, 3))
# 離れた場所に「ノイズ」となる点を数件追加
noise = np.array([[0, 5, 0], [5, 5, 5], [2, 0, 4]])
data = np.vstack([group1, group2, group3, noise])
# 2. HDBSCANの実行
# min_cluster_sizeを少し小さめの5に設定して、細かい塊も拾えるようにします
clusterer = hdbscan.HDBSCAN(min_cluster_size=5)
labels = clusterer.fit_predict(data)
# 3. 可視化
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
unique_labels = set(labels)
# 色の設定
colors = plt.cm.get_cmap("tab10")(np.linspace(0, 1, len(unique_labels)))
for k, col in zip(unique_labels, colors):
if k == -1:
col = 'lightgray' # ノイズは薄いグレー
label = 'ノイズ'
else:
label = f'クラスター {k}'
mask = (labels == k)
xyz = data[mask]
ax.scatter(xyz[:, 0], xyz[:, 1], xyz[:, 2], color=col, label=label, alpha=0.7, edgecolors='w')
ax.set_title('HDBSCAN 3Dクラスタリング結果')
ax.set_xlabel('説明変数 1')
ax.set_ylabel('説明変数 2')
ax.set_zlabel('説明変数 3')
ax.legend()
plt.show()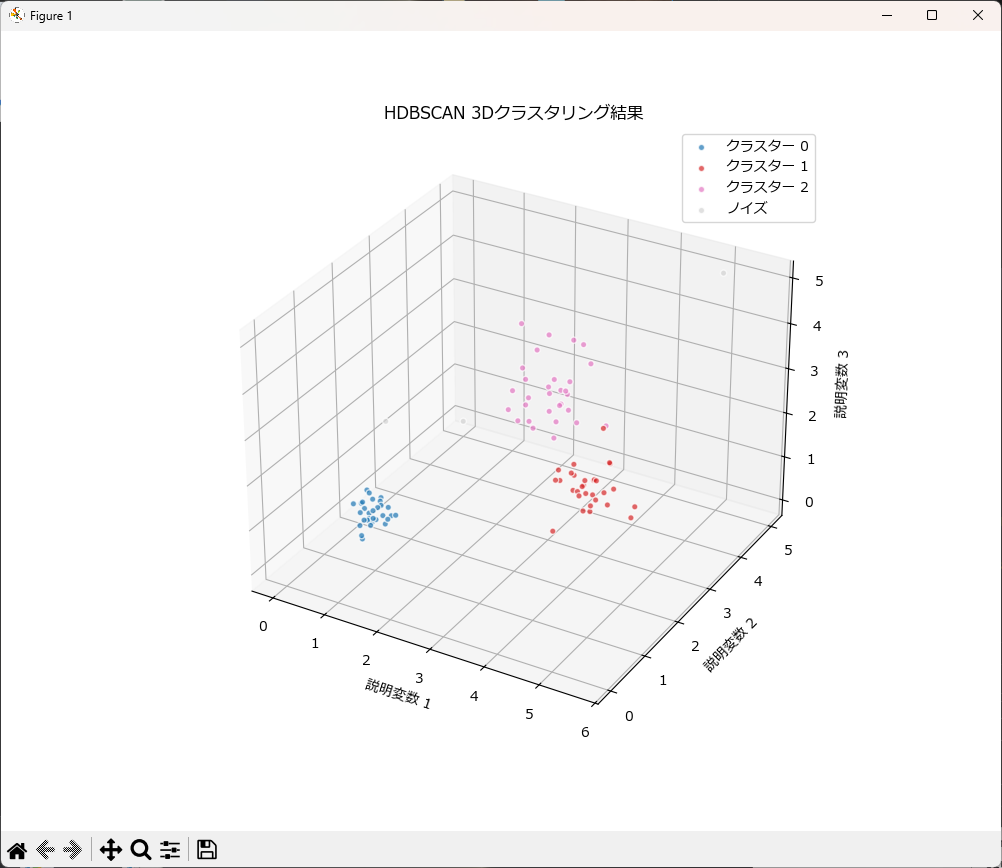
2次元の時と違い、データが空間内に立体的に配置されているのが分かります。
- 空間的な分離
2次元では重なりそうだったクラスター0とクラスター1が、3次元空間では明確に距離を保っていることが確認できます。 - 外れ値の隔離
孤立したノイズが、どの塊にも巻き込まれずに「グレー」として正しく弾かれているのが見て取れます。
多次元データの次元圧縮(PCA)と可視化
多次元データの場合は、PCAで情報を凝縮してからHDBSCANを適用、あるいは可視化のみPCA後の空間で行うのが一般的です。
import hdbscan
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
# 1. 6次元の多次元データを生成(実は3つのグループに分かれている設定)
np.random.seed(42)
# 各グループ、6次元空間の中の異なる場所に分布させる
group1 = np.random.normal(loc=[1, 2, 3, 4, 5, 6], scale=0.3, size=(40, 6))
group2 = np.random.normal(loc=[5, 4, 3, 2, 1, 0], scale=0.5, size=(40, 6))
group3 = np.random.normal(loc=[3, 3, 3, 3, 3, 3], scale=0.4, size=(40, 6))
# 完全にランダムなノイズデータ
noise = np.random.uniform(low=0, high=6, size=(10, 6))
data = np.vstack([group1, group2, group3, noise])
# 2. PCAによる次元削減(6次元 → 2次元)
# 人間には見えない6次元のつながりを、見える2次元に凝縮します
pca = PCA(n_components=2)
data_pca = pca.fit_transform(data)
# 3. HDBSCANの実行
# 削減後の2次元空間でクラスタリング
clusterer = hdbscan.HDBSCAN(min_cluster_size=5)
labels = clusterer.fit_predict(data_pca)
probs = clusterer.probabilities_
# 4. 可視化
plt.figure(figsize=(10, 7))
unique_labels = set(labels)
colors = plt.cm.get_cmap("Set1")(np.linspace(0, 1, len(unique_labels)))
for k, col in zip(unique_labels, colors):
mask = (labels == k)
label_name = f'クラスター {k}' if k != -1 else 'ノイズ'
color = 'lightgray' if k == -1 else col
plt.scatter(data_pca[mask, 0], data_pca[mask, 1],
c=[color], label=label_name,
s=probs[mask]*100 + 20, edgecolors='k', alpha=0.6)
plt.title('多次元データ(6D)をPCAで2次元に圧縮してHDBSCANで分類')
plt.xlabel('第1主成分(データの変化が一番大きい軸)')
plt.ylabel('第2主成分(データの変化が二番目に大きい軸)')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()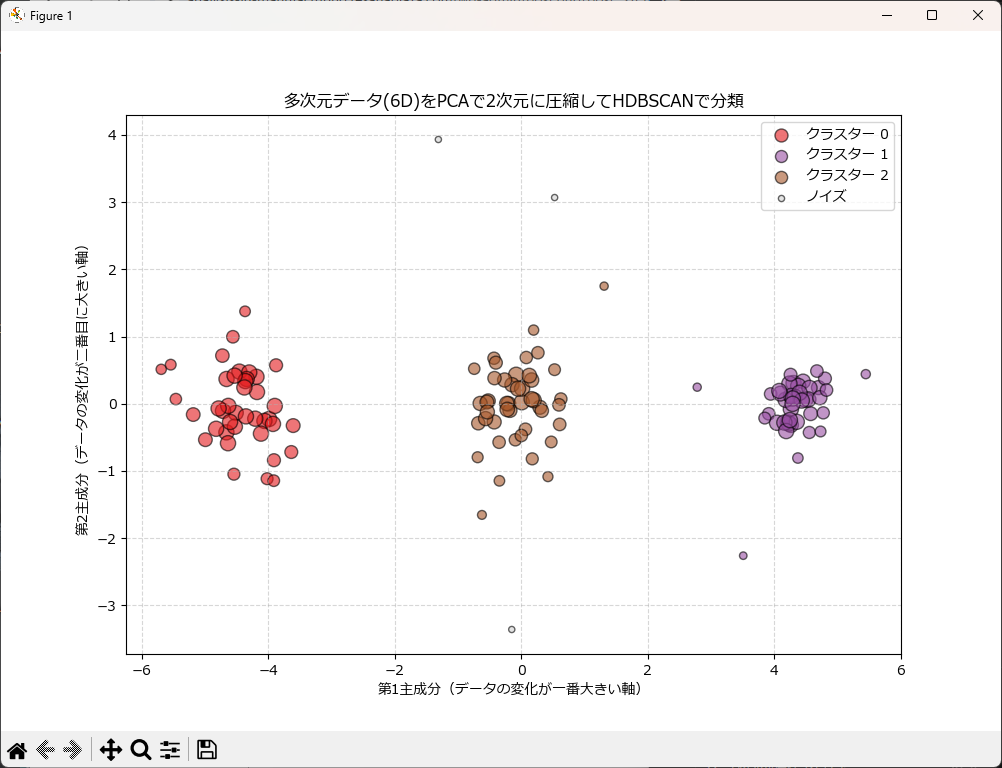
HDBSCANを実務で使う場合のポイント
HDBSCANは非常に強力なアルゴリズムですが、製造現場の実データに投入する際には、特有の「壁」にぶつかることがあります。ここでは、現場で直面しやすい課題とその対策を整理します。
「小さなゴミ」を拾いすぎる、または無視しすぎる
min_cluster_size の設定一つで結果が激変します。
- 課題
小さく設定しすぎると、ただの測定誤差(ノイズ)を「異常グループ」として報告してしまいます。逆に大きくしすぎると、本当に見つけたい「数件だけの初期不良」がノイズとして消されてしまいます。 - 対処
現場のドメイン知識(「最低でも3件連続して発生したら異常とみなす」など)を基準に設定し、複数の値で結果を比較することが不可欠です。
計算コスト(メモリと時間の壁)
HDBSCANは内部で「全ての点同士の距離の木(最小全域木)」を計算します。
- 課題
データ数が数万件を超えると、急激にメモリを消費し、計算が終わらなくなります。 - 対処
10万件を超えるようなビッグデータの場合、事前にランダムサンプリング(間引き)を行うか、k-meansなどで代表点を作ってからHDBSCANにかけるといった工夫が必要になります。
「密度の差」が激しすぎるデータ
- 課題
非常に高密度なグループと、非常に低密度なグループが混在している場合、低密度な方がすべて「ノイズ」と判定されることがあります。 - 対処
min_samplesパラメータを調整して、どれくらい「密集」していればクラスターと認めるかの感度を調整します。また、一度に全部を分類しようとせず、段階的にクラスタリングを行うことも検討します。
製造業向けのクラスタリング自作クラス
最後に、これら一連の処理を実務で効率的に回すための「HDBSCAN対応版 ユーティリティクラス」を紹介します。
このクラスは、前述のDBSCAN版をベースに、HDBSCAN特有の「確信度(probabilities_)」を可視化に反映できるよう拡張したものです。
HDBSCANUtilクラスの使い方
HDBSCANでクラスタリングを行う手順は非常にシンプルです。 HDBSCANUtil のインスタンスを生成し、fit() メソッドで対象のカラムを指定するだけで、計算から結果の保持までを完結できます。
# 1. データの準備(DataFrame形式)
import pandas as pd
df = pd.DataFrame([
[1.0, 2.0, 1.5], [1.2, 3.2, 1.8], [1.8, 1.8, 1.0], [1.3, 1.3, 0.9], [0.7, 1.7, 1.2],
[5.0, 6.0, 5.5], [4.3, 6.3, 5.8], [3.7, 5.7, 5.0], [5.4, 6.4, 5.6], [4.1, 5.5, 5.3],
[9.0, 8.0, 9.5], [9.3, 9.3, 9.8], [8.2, 9.7, 8.9], [9.1, 7.4, 9.0], [8.2, 9.6, 9.3]
], columns=['Feature1', 'Feature2','Feature3'])
# 2. HDBSCANUtilのインスタンス化
# PCAを適用したい場合は pca=2 のように指定可能です
hdb = HDBSCANUtil(df)
# 3. モデルの作成と学習
# min_cluster_size(最小クラスターサイズ)を指定します
hdb.fit(['Feature1', 'Feature2','Feature3'], min_cluster_size=2)
# 4. 結果の取得と可視化
print("クラスターラベル:", hdb.labels)
print("各データの確信度:", hdb.probabilities)
# 3次元グラフの表示(確信度に基づいたプロット)
plot_clusters_3d(hdb)HDBSCANUtil クラス
DBSCAN版からの主な変更点は次の通りです。
- 確信度の保持
self.probabilitiesを追加しました。これにより、後ほどグラフを描画する際に「点の大きさ」を調整できるようになります。 - パラメータの柔軟性
hdbscan_paramsとすることで、min_cluster_sizeやmin_samplesなど、HDBSCANの豊富な引数をそのまま渡せるようにしました。 - PCAの統合
インスタンス生成時にpca=2などと指定すれば、内部で自動的に次元圧縮してからクラスタリングを行う流れを維持しています。
| メソッド名 | 説明 | パラメータ | 戻り値 |
|---|---|---|---|
| __init__(df, pca=0) | クラスの初期化を行います。 | df: 解析対象のDataFramepca: 次元圧縮を行う場合の次元数(0は不使用) | なし |
| fit(columns, df=None, **hdb_params) | HDBSCANによる学習を実行します。 | columns: 使用するカラム名のリストdf: 別途指定する場合のDataFramehdb_params: min_cluster_sizeなどのパラメータ | HDBSCANモデル |
| read_csv(file_name, encoding="sjis") | CSVからデータを読み込みます。 | file_name: ファイルパスencoding: エンコーディング | なし |
import pandas as pd
import hdbscan
from sklearn.decomposition import PCA
class HDBSCANUtil:
def __init__(self, df=None, pca=0):
"""
HDBSCANUtilクラスの初期化
:param df: 初期データフレーム (pd.DataFrame)
:param pca: PCAを適用する次元数 (0: 使用しない)
"""
self.df = df.copy() if df is not None else None
self.model = None
self.labels = []
self.probabilities = [] # HDBSCAN特有の確信度を保持
self.columns = []
self.pca_dim = pca
def fit(self, columns: list, df: pd.DataFrame = None, **hdbscan_params):
"""
HDBSCANモデルの学習
:param columns: 使用するカラム名のリスト
:param hdbscan_params: HDBSCANのパラメータ (min_cluster_size等)
"""
if df is not None:
self.df = df
self.columns = columns
# 学習データの抽出
X = self.df[columns].values
# PCAによる次元削減(指定がある場合)
if self.pca_dim > 0:
pca_model = PCA(n_components=self.pca_dim)
X = pca_model.fit_transform(X)
# HDBSCANモデルを作成と実行
self.model = hdbscan.HDBSCAN(**hdbscan_params)
self.labels = self.model.fit_predict(X)
# 確信度(属する確率)を保存
self.probabilities = self.model.probabilities_
return self.model
def read_csv(self, file_name, encoding="shift-jis"):
self.df = pd.read_csv(file_name, encoding=encoding)グラフ描画関数
HDBSCANには「コアサンプル」という概念がDBSCANとは異なる形(階層的)で存在するため、代わりに「確信度(probabilities)」を点のサイズに反映させるようにしています。
2次元グラフ描画
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
def plot_clusters(util, x_col=None, y_col=None):
"""
HDBSCANクラスタリング結果を可視化
- util: HDBSCANUtilのインスタンス
- x_col, y_col: プロットするカラム名(省略時にはutil.columnsを使用)
"""
if not isinstance(util, HDBSCANUtil):
raise ValueError("引数はHDBSCANUtilのインスタンスでなければなりません。")
# カラムの自動設定
if x_col is None or y_col is None:
if len(util.columns) < 2:
raise ValueError("x_col と y_col が指定されていない場合、columnsに2つ以上のカラムが必要です。")
x_col = util.columns[0]
y_col = util.columns[1]
plt.figure(figsize=(10, 7))
# クラスタごとにデータポイントをプロット
unique_labels = np.unique(util.labels)
# 色のバリエーションを生成
colors = plt.cm.get_cmap("Set1")(np.linspace(0, 1, len(unique_labels)))
for cluster, col in zip(unique_labels, colors):
mask = (util.labels == cluster)
cluster_data = util.df[mask]
cluster_probs = util.probabilities[mask]
if cluster == -1:
c = 'lightgray'
label = "ノイズ"
else:
c = [col]
label = f"クラスター {cluster}"
# ポイント:s(サイズ)に確信度を反映させる
# 0だと見えなくなるので、最小サイズを20に設定
plt.scatter(
cluster_data[x_col],
cluster_data[y_col],
label=label,
c=c,
s=cluster_probs * 120 + 20,
edgecolors='k',
alpha=0.6
)
plt.xlabel(x_col)
plt.ylabel(y_col)
plt.legend()
plt.title("HDBSCAN クラスタリング可視化\n(点の大きさ = クラスターへの確信度)")
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()3次元グラフ描画
3次元空間では、2次元以上に「どの点が塊の中心にいるか」が見えにくくなることがあります。そのため、確信度が高い点ほどドットを大きく、不透明度(alpha)を高く設定することで、クラスターの「芯」がどこにあるのかを立体的に把握しやすくしています。
| 関数名 | 説明 | 引数 | 戻り値 | 備考 |
|---|---|---|---|---|
| plot_clusters | 2次元クラスタリングの結果を可視化します。各点のサイズに確信度を反映します。 | util: HDBSCANUtilのインスタンスx_col: x軸のカラム名y_col: y軸のカラム名 | なし | x_col, y_col未指定時は、使用したカラムの最初の2つを自動選択します。 |
| plot_clusters_3d | 3次元クラスタリングの結果を可視化します。空間的な分布と確信度を同時に確認できます。 | util: HDBSCANUtilのインスタンスx_col/y_col/z_col: 各軸のカラム名 | なし | x_col/y_col/z_col未指定時は、使用したカラムの最初の3つを自動選択します。 |
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
def plot_clusters_3d(util, x_col=None, y_col=None, z_col=None):
"""
3D HDBSCAN クラスタリング結果を可視化
- util: HDBSCANUtilのインスタンス
- x_col, y_col, z_col: プロットするカラム名(省略時にはutil.columnsを使用)
"""
if not isinstance(util, HDBSCANUtil):
raise ValueError("引数はHDBSCANUtilのインスタンスでなければなりません。")
# カラムの自動設定
if x_col is None or y_col is None or z_col is None:
if len(util.columns) < 3:
raise ValueError("x_col, y_col, z_col が指定されていない場合、columnsに3つ以上のカラムが必要です。")
x_col = util.columns[0]
y_col = util.columns[1]
z_col = util.columns[2]
fig = plt.figure(figsize=(12, 9))
ax = fig.add_subplot(111, projection='3d')
unique_labels = np.unique(util.labels)
colors = plt.cm.get_cmap("tab10")(np.linspace(0, 1, len(unique_labels)))
for cluster, col in zip(unique_labels, colors):
mask = (util.labels == cluster)
cluster_data = util.df[mask]
cluster_probs = util.probabilities[mask]
if cluster == -1:
c = 'lightgray'
label = "ノイズ"
alpha = 0.3 # ノイズは目立たないように薄く
else:
c = [col]
label = f"クラスター {cluster}"
alpha = 0.7
# 3次元散布図をプロット
# s: 確信度に基づいたサイズ調整
ax.scatter(
cluster_data[x_col],
cluster_data[y_col],
cluster_data[z_col],
label=label,
c=c,
s=cluster_probs * 150 + 20, # 3Dは見づらいのでサイズを少し大きめに
edgecolors='w', # 3Dでは白の縁取りが見やすい
linewidth=0.5,
alpha=alpha
)
ax.set_xlabel(x_col)
ax.set_ylabel(y_col)
ax.set_zlabel(z_col)
ax.legend()
ax.set_title("3D HDBSCAN クラスタリング結果の可視化\n(ドットの大きさ = 確信度)")
plt.show()まとめ
本記事では、HDBSCANを活用したクラスタリングの基本から応用、製造業での実践的な活用例までを解説しました。
従来のDBSCANに「階層構造」と「確信度」という概念を加えたHDBSCANは、密度の異なる塊が混在する製造現場のデータ解析において、より強力な武器となります。その柔軟性とノイズ耐性により、製品品質のバラツキや設備保全の予兆検知において、これまで見逃していた小さな変化を「確信度の低い点」として識別することが可能になります。
一方で、実務に投入する際には以下のポイントに留意する必要があります。
- パラメータの影響
min_cluster_sizeの値ひとつで、小さな異常を「発見」するか「無視」するか結果が大きく分かれます。 - 計算コスト
アルゴリズムの特性上、データ規模が数万件を超えると計算負荷が急激に高まります。 - 密度差のジレンマ
密度の差が極端すぎると、低密度なグループがノイズとして切り捨てられるリスクがあります。
これらの弱点を克服する鍵は、「アルゴリズムに丸投げしないこと」にあります。 現場のドメイン知識を min_cluster_size の基準に反映させ、PCA(主成分分析)による次元の整理を行い、ときにはデータを適切にサンプリングする。こうした「人間の判断」と「HDBSCANの計算力」を掛け合わせることで、初めてデータは「価値ある情報」へと変わります。
本記事で紹介した可視化手法や HDBSCANUtil が、皆さんのデータ分析業務の一助になれば幸いです。








コメント