
高次元のデータを扱うとき、こんな悩みに遭遇したことはありませんか?
- 特徴量が多すぎて、モデルの学習がうまくいかない
- データの可視化が難しく、全体像がつかめない
- ノイズや冗長な情報が多くて、分析がブレやすい
そんなときに役立つのが「次元圧縮(次元削減)」というテクニックです。 これは、データの本質的な構造を保ちながら、不要な情報をそぎ落とし、より少ない次元で表現する方法。 視覚化や前処理、異常検知、クラスタリングなど、さまざまな場面で活躍します。
この記事では、Pythonで実践できる代表的な次元圧縮手法を5つ厳選し、 それぞれの特徴・向いている用途・使い方のポイントをわかりやすく解説します!
次元圧縮とは?なぜ必要なのか
現代のデータ分析では、数百〜数千もの特徴量(変数)を持つ高次元データを扱うことが当たり前になってきました。画像、音声、センサーデータ、テキストのベクトル表現など、情報が豊富なぶん、“次元の呪い(curse of dimensionality)”と呼ばれる問題にも直面します。
具体的には、次元が高いことで以下の問題が発生します。
- 可視化ができない
2次元や3次元ならグラフで直感的に見られますが、100次元のデータは人間の目では把握できません。 - 計算コストが高い
次元が増えると、距離計算やモデル学習にかかる時間やメモリが急増します。 - ノイズや冗長な情報が多くなる
すべての特徴が有用とは限らず、不要な次元がモデルの精度を下げることもあります。
次元圧縮(次元削減)とは、元の高次元データを、より少ない次元に変換しつつ、できるだけ情報を保つための手法です。 たとえば、100次元のデータを2次元に圧縮して可視化したり、10次元に圧縮してモデルの入力に使ったりします。
次元圧縮を使うことで以下のメリットが得られます。
- データの構造やパターンを可視化できる
- 学習時間の短縮や過学習の抑制ができる
- ノイズを除去して、より本質的な特徴を抽出できる
次元圧縮の注意点
次元圧縮は、データの可視化や前処理、ノイズ除去などに役立つ強力なツールですが、万能ではありません。 以下のポイントに注意して使うことで、より効果的な分析が可能になります。
圧縮しすぎに注意
- 次元を減らしすぎると、重要な情報まで失われる可能性があります。
- 特に、分類や回帰などのタスクでは、性能が低下することもあるため、寄与率や再構成誤差を確認しながら調整しましょう。
可視化結果を過信しない
- t-SNEやUMAPは視覚的に美しいクラスタを描きますが、距離や密度の意味は手法によって異なります。
- たとえば、t-SNEではクラスタ間の距離は信頼できないことが多いので、見た目だけで判断しないことが大切です。
再現性に注意
- t-SNEやUMAPなどはランダム性を含むアルゴリズムです。
random_stateを設定しないと、毎回異なる結果になることがあります。- 再現性が必要な場合は、乱数シードを固定しましょう。
圧縮後の特徴の「意味」は不明確
- PCAやAutoEncoderで得られる新しい特徴量(主成分や潜在変数)は、元の特徴と直接対応していないことが多いです。
- そのため、解釈性が重要な分析には注意が必要です。
手法ごとの前提条件を確認する
- LDAは教師あり学習が前提で、クラス分布が正規分布に近いことが仮定されています。
- PCAは線形性を仮定しているため、非線形な構造には弱いです。
- 手法ごとの前提や制約を理解して選ぶことが重要です。
次元圧縮手法の選び方
次元圧縮にはさまざまな手法がありますが、それぞれ得意分野が異なります。
下表は、代表的は5つの手法について、目的・特徴・向いているケースで比較しています。
| 手法 | 線形/非線形 | 教師あり/なし | 可視化向き | 再構成可 | 向いているケース |
|---|---|---|---|---|---|
| PCA | 線形 | 教師なし | △ | △ | 高速に特徴を圧縮したいとき、ノイズ除去したいとき |
| LDA | 線形 | 教師あり | △ | △ | クラス分離を意識した特徴抽出をしたいとき |
| t-SNE | 非線形 | 教師なし | ◎ | × | クラスタ構造を2D/3Dで可視化したいとき |
| UMAP | 非線形 | 教師なし | ◎ | △ | t-SNEより高速に可視化したいとき、クラスタリング前処理 |
| AutoEncoder | 非線形 | 教師なし | ○ | ◎ | 非線形な特徴を圧縮したいとき、再構成や異常検知にも使いたいとき |
代表的な5つの手法と使い方
この章では、代表的な次元圧縮手法5つ(PCA, LDA, t-SNE, UMAP, AutoEncoder)について、それぞれの特徴や向いている用途、Pythonによる実装例(サンプルコード)を紹介します。
サンプルコードでは、主に Irisデータセット(4次元)やMNISTデータセット(784次元の手書き数字画像)を使用し、2次元への圧縮を前提としています。可視化や特徴抽出の参考としてご活用ください。
PCA(主成分分析)
PCA(Principal Component Analysis)は、最も基本的で広く使われている次元圧縮手法のひとつです。 データの分散が最大になる方向(主成分)を軸として再構成し、情報をできるだけ保ったまま次元を減らします。
数学的には、共分散行列の固有値分解や特異値分解(SVD)を使って、元の特徴空間を回転・射影するイメージです。
特徴と向いているケース
| 項目 | 内容 |
|---|---|
| 圧縮タイプ | 線形 |
| 教師あり/なし | 教師なし |
| 可視化向き | △(2〜3次元ならOK) |
| 再構成可 | △(ある程度可能) |
| 向いている場面 | 高速に特徴を圧縮したいとき、ノイズ除去、前処理、可視化の補助 |
メリット・デメリット
| 項目 | 内容 |
|---|---|
| メリット | ・実装が簡単で計算が高速 ・特徴量の寄与率がわかる ・ノイズ除去に有効 |
| デメリット | ・線形変換しかできない(非線形な構造には弱い) ・主成分の意味が直感的にわかりにくい |
サンプルソース
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# データ読み込み
data = load_iris()
X = data.data
y = data.target
# PCAで2次元に圧縮
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 可視化
plt.figure(figsize=(8, 6))
for label in set(y):
plt.scatter(X_pca[y == label, 0], X_pca[y == label, 1], label=data.target_names[label])
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.title('PCA of Iris Dataset')
plt.legend()
plt.show()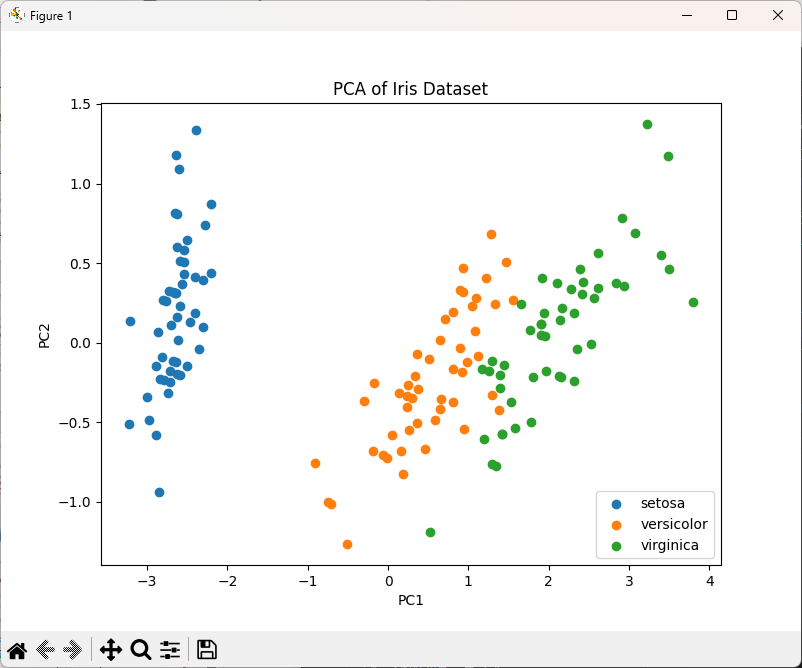
LDA(線形判別分析)
LDA(Linear Discriminant Analysis)は、ラベル付きデータ(教師あり)に対して使う次元圧縮手法です。 クラスごとの分布を考慮しながら、クラス間の分離が最大になるような軸(判別軸)を見つけて、データを射影します。
PCAが「データの分散」に注目するのに対して、LDAは「クラスの分離」に注目するのが大きな違いです。
特徴と向いているケース
| 項目 | 内容 |
|---|---|
| 圧縮タイプ | 線形 |
| 教師あり/なし | 教師あり |
| 可視化向き | △(クラスが3つ以下ならOK) |
| 再構成可 | ×(再構成は目的ではない) |
| 向いている場面 | 分類タスクの前処理、クラス間の分離を強調したいとき |
メリット・デメリット(表形式)
| 項目 | 内容 |
|---|---|
| メリット | ・クラス間の分離が明確になる ・分類精度の向上に貢献 ・次元数がクラス数−1に制限されるためシンプル |
| デメリット | ・教師ありでしか使えない ・クラス分布が正規分布に近いことが前提 ・非線形な分離には弱い |
サンプルソース
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# データ読み込み
data = load_iris()
X = data.data
y = data.target
# LDAで2次元に圧縮
lda = LinearDiscriminantAnalysis(n_components=2)
X_lda = lda.fit_transform(X, y)
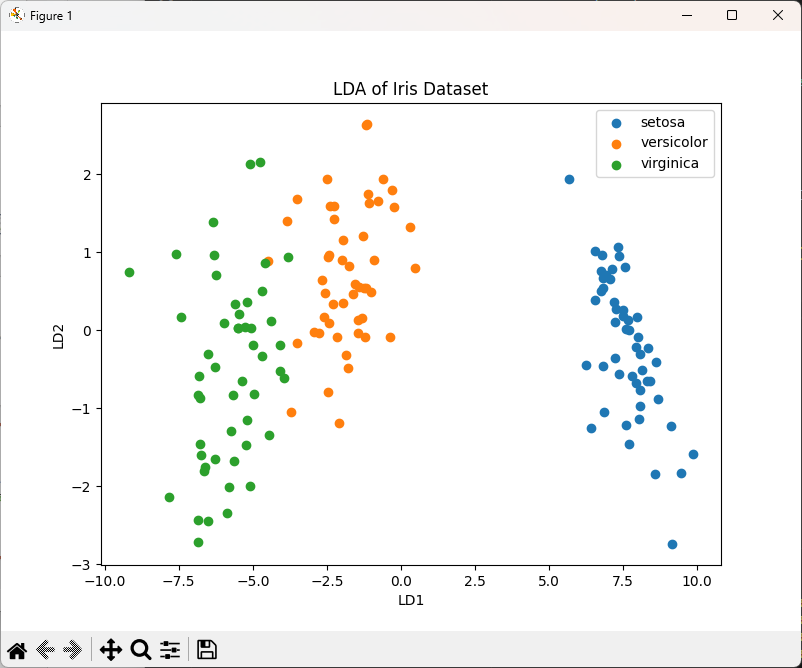
# 可視化
plt.figure(figsize=(8, 6))
for label in set(y):
plt.scatter(X_lda[y == label, 0], X_lda[y == label, 1], label=data.target_names[label])
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.title('LDA of Iris Dataset')
plt.legend()
plt.show()
t-SNE(t-分布型確率的近傍埋め込み)
t-SNE(t-Distributed Stochastic Neighbor Embedding)は、高次元データを2次元や3次元に非線形で圧縮して可視化するための手法です。 データの局所的な類似性(近さ)を保つことに特化していて、クラスタ構造を視覚的にとらえるのに非常に優れています。
ただし、再構成や新しいデータの変換には向いていないため、あくまで「可視化専用」として使うのが基本です。
特徴と向いているケース
| 項目 | 内容 |
|---|---|
| 圧縮タイプ | 非線形 |
| 教師あり/なし | 教師なし |
| 可視化向き | ◎(2〜3次元での可視化に特化) |
| 再構成可 | ×(不可) |
| 向いている場面 | 高次元データのクラスタ構造を視覚的に確認したいとき |
メリット・デメリット(表形式)
| 項目 | 内容 |
|---|---|
| メリット | ・クラスタ構造が視覚的にわかりやすい ・非線形な関係も表現できる ・教師なしで使える |
| デメリット | ・再構成や新規データの変換ができない ・次元数は基本2〜3に限定 ・パラメータ調整(perplexityなど)に敏感 |
サンプルソース
from sklearn.manifold import TSNE
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
# データ読み込み(手書き数字データ)
digits = load_digits()
X = digits.data
y = digits.target
# t-SNEで2次元に圧縮
tsne = TSNE(n_components=2, perplexity=30, random_state=42)
X_tsne = tsne.fit_transform(X)
# 可視化
plt.figure(figsize=(10, 8))
scatter = plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='tab10', alpha=0.7)
plt.colorbar(scatter, label='Digit Label')
plt.title('t-SNE Visualization of Digits Dataset')
plt.xlabel('t-SNE 1')
plt.ylabel('t-SNE 2')
plt.show()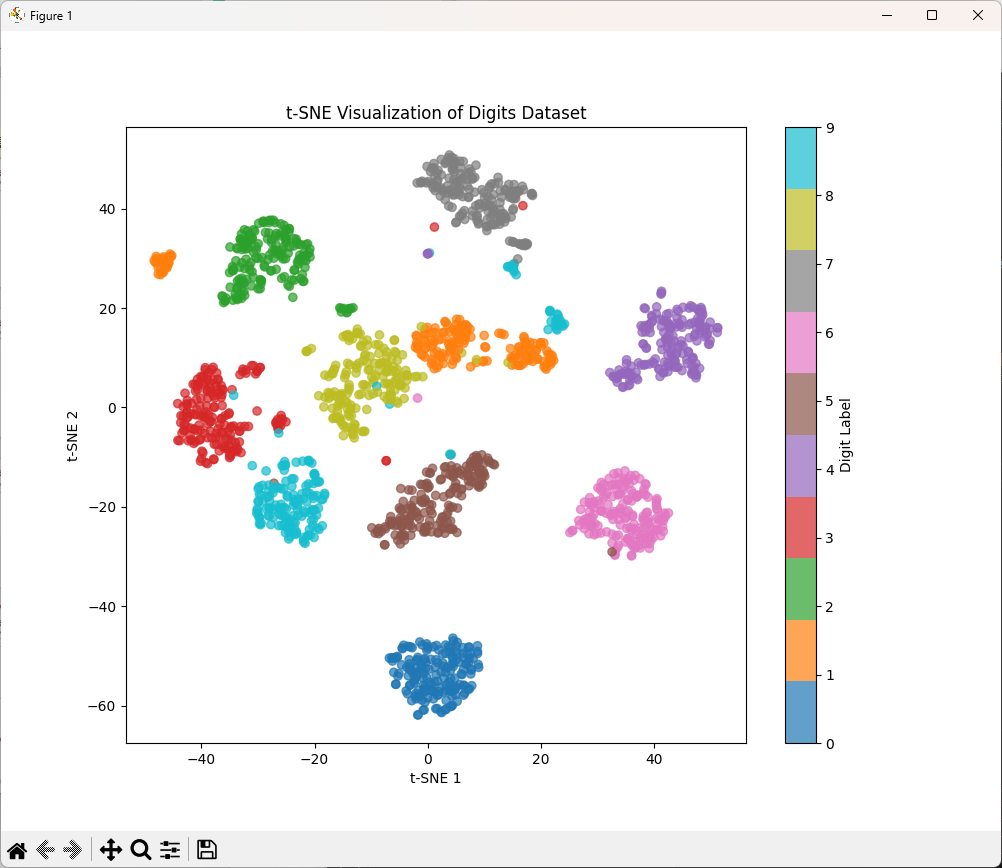
UMAP(Uniform Manifold Approximation and Projection)
UMAPは、高次元データを低次元に非線形で圧縮する手法で、t-SNEと似た目的(可視化やクラスタリング前処理)で使われます。 t-SNEと比べて、計算が高速でスケーラブル、さらに新しいデータの変換にも対応できるという強みがあります。
局所構造だけでなく、グローバルな構造もある程度保持できるのが特徴で、クラスタ間の距離感も比較的信頼できます。
特徴と向いているケース
| 項目 | 内容 |
|---|---|
| 圧縮タイプ | 非線形 |
| 教師あり/なし | 教師なし(教師ありも可能) |
| 可視化向き | ◎(2〜3次元での可視化に強い) |
| 再構成可 | △(新規データの変換は可能、完全な再構成は不可) |
| 向いている場面 | 高速な可視化、大規模データのクラスタリング前処理、t-SNEの代替 |
メリット・デメリット
| 項目 | 内容 |
|---|---|
| メリット | ・t-SNEより高速&スケーラブル ・新しいデータにも対応可能 ・局所+グローバル構造を保持しやすい |
| デメリット | ・パラメータが多く、調整がやや複雑 ・再構成はできない ・結果の解釈はやや難しいことも |
サンプルソース
# pip install umap-learn
import umap.umap_ as umap
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
# データ読み込み
digits = load_digits()
X = digits.data
y = digits.target
# UMAPで2次元に圧縮
reducer = umap.UMAP(n_components=2, random_state=42)
X_umap = reducer.fit_transform(X)
# 可視化
plt.figure(figsize=(10, 8))
scatter = plt.scatter(X_umap[:, 0], X_umap[:, 1], c=y, cmap='tab10', alpha=0.7)
plt.colorbar(scatter, label='Digit Label')
plt.title('UMAP Visualization of Digits Dataset')
plt.xlabel('UMAP 1')
plt.ylabel('UMAP 2')
plt.show()
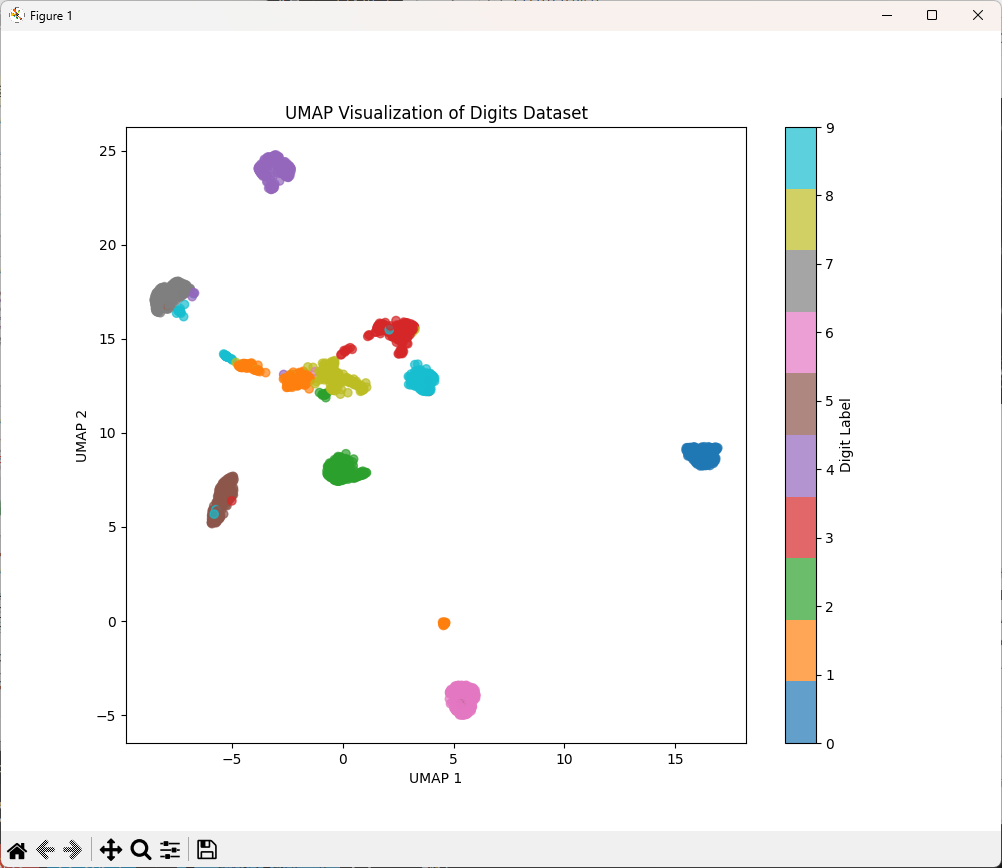
AutoEncoder(自己符号化器)
AutoEncoderは、入力データをいったん圧縮(エンコード)し、そこから元のデータを再構成(デコード)する自己教師ありのニューラルネットワーク。 このとき、中間層(ボトルネック層)に現れる表現が、圧縮された特徴ベクトル(潜在変数)になります。
この潜在空間を使えば、非線形な構造を捉えたまま、次元圧縮ができます。
特徴と向いているケース
| 項目 | 内容 |
|---|---|
| 圧縮タイプ | 非線形 |
| 教師あり/なし | 教師なし(自己教師あり) |
| 可視化向き | ○(2〜3次元に圧縮すれば可視化可能) |
| 再構成可 | ◎(再構成が目的のひとつ) |
| 向いている場面 | 非線形な特徴抽出、異常検知、生成モデルの前段階、再構成が必要なタスク |
メリット・デメリット
| 項目 | 内容 |
|---|---|
| メリット | ・非線形な圧縮が可能 ・再構成ができる ・潜在空間を使ってクラスタリングや生成も可能 |
| デメリット | ・学習に時間がかかる ・ハイパーパラメータの調整が必要 ・解釈性が低いこともある |
サンプルソース
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
# データ読み込み
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.reshape(-1, 784) / 255.0
x_test = x_test.reshape(-1, 784) / 255.0
# AutoEncoder構築
input_dim = 784
encoding_dim = 2 # 2次元に圧縮して可視化
input_layer = Input(shape=(input_dim,))
encoded = Dense(128, activation='relu')(input_layer)
encoded = Dense(64, activation='relu')(encoded)
bottleneck = Dense(encoding_dim, activation='linear')(encoded)
decoded = Dense(64, activation='relu')(bottleneck)
decoded = Dense(128, activation='relu')(decoded)
output_layer = Dense(input_dim, activation='sigmoid')(decoded)
autoencoder = Model(input_layer, output_layer)
encoder = Model(input_layer, bottleneck)
autoencoder.compile(optimizer='adam', loss='mse')
autoencoder.fit(x_train, x_train, epochs=20, batch_size=256, shuffle=True, validation_split=0.1)
# グラフ化
encoded_imgs = encoder.predict(x_test)
plt.figure(figsize=(10, 8))
plt.scatter(encoded_imgs[:, 0], encoded_imgs[:, 1], c='blue', alpha=0.5)
plt.title('2D Latent Space from AutoEncoder')
plt.xlabel('Latent Dimension 1')
plt.ylabel('Latent Dimension 2')
plt.show()
目的別・次元圧縮手法の選び方
次元圧縮にはさまざまな手法が存在しますが、「結局どれを使えばよいのか」と迷う方も多いのではないでしょうか。 そこで本記事では、分析の目的に応じた代表的な手法とその選び方を整理しました。
| 目的 | おすすめ手法 | 理由 |
|---|---|---|
| 可視化したい | t-SNE / UMAP | 非線形構造を2D/3Dで視覚化できる。クラスタの分布や関係性が見えやすい。 |
| 特徴抽出したい | PCA / AutoEncoder | 情報を圧縮しつつ、モデルの入力として再利用しやすい。ノイズ除去にも◎。 |
| 分類前の前処理に使いたい | LDA | クラス間の分離を最大化する軸を見つけてくれる。分類モデルの精度向上に貢献。 |
| 再構成したい | AutoEncoder | 入力を圧縮→復元できる構造を持つ。異常検知や生成モデルの基盤としても使える。 |
| 高速に処理したい | PCA / UMAP | 計算コストが低く、大規模データにも対応しやすい。UMAPはt-SNEよりも高速。 |
初めて試す場合はPCAが無難。シンプルかつ高速で、基礎的な理解にも適しています。
可視化が主目的であればUMAPが有力候補。t-SNEと比べて処理速度が速く、再現性も高めです。
再構成や生成を伴う高度なタスクには、AutoEncoderの柔軟性が活きます。
まとめ
高次元データを扱う現代の分析において、次元圧縮は欠かせないテクニックです。 PCAやLDAのような古典的手法から、t-SNEやUMAP、AutoEncoderといった非線形な手法まで、それぞれに得意分野と使いどころがあります。
本記事では、以下のポイントを中心に解説しました。
- 次元圧縮が必要な理由とその効果
- 代表的な5つの手法の特徴と使い方
- 目的別の手法選びのヒント
- 実装例と注意点
最も重要なのは、「どの手法が優れているか」ではなく、「分析の目的に応じて最適な手法を選ぶこと」です。 可視化、前処理、再構成など、目的を明確にすることで、次元圧縮の効果を最大限に引き出すことができます。
本記事が、皆さまのデータ分析や業務における一助となれば幸いです。








コメント