
前回の記事では、FFTが使えない低周期データから波形の「性格」を炙り出す「Rolling Window(移動窓)」の強力な手法をご紹介しました。一定のスピードや負荷で稼働し続ける設備であれば、この方法でも十分に予兆を捉えることができます。
しかし、実際の製造現場では、もう一つの「巨大な壁」が立ちはだかります。
- 加工する製品によって負荷(レシピ)が変わる
- 設備のタクトタイム(稼働スピード)が常に変動する
- 外気温や冷却水の影響でベースラインが上下する
このような環境下では、単一のセンサー(温度や振動など)だけを監視していても、「異常発熱による危険な温度上昇」なのか、「単に生産スピードを上げたから温度が上がっただけ」なのか、区別がつきません。
この課題を解決するのが、複数のセンサーデータを1つに束ねる「多変量解析(次元削減)」のアプローチです。
個別の値の大小を追うのではなく、「車速と回転数と温度の"いつものバランス"(相関関係)」に着目します。
本記事では、その相関ルールの崩れを学習し、複数の複雑なデータを「1つの分かりやすい異常スコア(単変量)」へと変換・圧縮する実践的なPython手法をご紹介します。
異常スコアを使った予兆・異常検知の具体的な内容については、「【Python実践】FFTが使えなくても大丈夫!低周期データから故障の予兆を見つけるRolling Window手法とは」の記事を参考にしてください。

1. 「次元圧縮(次元削減)」とは?複数センサーを1つに束ねる方法
「次元圧縮(または次元削減)」と聞くと、なんだか難しい数学の専門用語のように聞こえるかもしれません。あるいは、「データを間引いて情報を捨てること?」と誤解されがちですが、そうではありません。
予兆検知における次元圧縮の本当の目的は、「複数のセンサー間の『いつものルール(相関関係)』を見つけ出し、そこからの『ズレ具合』という1つの指標(1次元)に変換すること」です。
「値の大きさ」ではなく「ルール違反」をスコア化する
例えば、「モーターの回転数」と「モーターの表面温度」という2つのセンサーデータ(2次元)があり、両者には明確なルール(相関関係)が存在すると仮定します。
- 回転数が低い時は、温度も低い
- 回転数が高い時は、温度も高い
もし、モーターに異常な摩擦(予兆)が発生し始めたらどうなるでしょうか? 「回転数は低いのに、温度だけが異常に高い」という、普段の直線から大きく外れた場所にデータがポツンと現れます。
この相関関係の乱れを評価し、1つの代表値に集約(スコア化)することができれば、そのスコア値の変化により予兆や異常が検知できそうですよね。
複数のセンサーから相互の相関関係を算出し、1つのスコアにするために、次元圧縮のアルゴリズムを用います。 一般的なデータ分析において、次元圧縮は「機械学習の説明変数を減らす目的」でよく利用されますが、本記事で紹介する次元圧縮は「相関関係の崩れを炙り出すための圧縮方法」という点で性質が異なります。
異常・予兆検知のための次元圧縮(次元削減)手法一覧
異常・予兆検知において重要な役割を果たす「次元圧縮」の手法を、下表にまとめました。
ここで注目すべきは、カテゴリ①と④の双方に登場するPCA(主成分分析)の使い分けです。 ④におけるPCAは、一般的な機械学習と同様に「情報の凝縮・削減」を目的としていますが、①においては変数間の相関ルール(約束事)が破綻した瞬間を捉える「相関監視」に特化して活用されています。
このように、同じアルゴリズムでも「何を見るか」によって、抽出できる特徴量の意味合いは大きく異なります。
| カテゴリ | 手法 | 主な用途・捉えられる変化 |
|---|---|---|
| ① 相関ルールの崩れ | PCA再構成誤差 (SPE/Q統計量) | 変数間の「いつもの関係性」が壊れた瞬間の検知 |
| 重回帰残差 | 特定の目的変数と説明変数の予測関係の乖離 | |
| 多重相関崩れ | 複数のセンサーが連動して動かなくなった予兆 | |
| ② 正常群からの距離 | マハラノビス距離 (D2) | データの相関を考慮した、集団からの「浮き具合」 |
| L2ノルム (ユークリッド距離) | 単純な多次元空間上での中心からの距離 | |
| 最大|z| (最大標準化スコア) | 複数項目の中で、最も極端に振れている項目の特定 | |
| ③ ロバストな集約 | IQRロバストスコア | 外れ値に引きずられない、四分位範囲を用いた正規化 |
| ④ 情報の凝縮・圧縮 | PCA主成分1 (PC1) | データの変動が最も大きい「主軸」の動き |
| PCA主成分2 (PC2) | 第1主成分では説明しきれない「第2の変動」 | |
| 加重スコア | 物理的な意味(寄与度)に基づき重み付けした総合指標 |
相関の崩れを見抜く2つの代表的アルゴリズム
複数のセンサーデータの相関関係を評価し、1つの「異常スコア」に束ねるための代表的な手法として、本記事では現場で特に実績のある2つのアルゴリズムをご紹介します。
ご自身の環境でも再現できるよう、サンプルデータの生成とグラフ描画の関数を用意しました。このソースコードの最後に、以降に紹介するソースを貼り付けていただければ、掲載しているグラフと同じものが表示できます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from matplotlib import rcParams
rcParams['font.family'] = 'Meiryo'
# ---------------------------------------------------------
# 1. 4変数の多変量ダミーデータ生成関数(リアルな異常連鎖シナリオ)
# ---------------------------------------------------------
def generate_multivariate_dummy_data(n_samples=500):
np.random.seed(42)
# ① ベースライン(正常時の相関ルール)
speed = np.linspace(1000, 3000, n_samples) + np.sin(np.linspace(0, 10, n_samples)) * 500 + np.random.normal(0, 50, n_samples)
rpm = speed * 1.5 + np.random.normal(0, 50, n_samples)
pressure = rpm * 0.02 + np.random.normal(0, 1, n_samples)
temp = speed * 0.05 + 20 + np.random.normal(0, 2, n_samples)
# ② 【異常の混入】時間差を伴う相関の崩壊
anomaly_start, anomaly_end = 350, 400
temp_warning_start = 300 # 温度だけ少し前から予兆が出始める
# 車速: 変化なし(そのまま順調に走り続けている)
# 温度: 予兆区間(300)から徐々に上昇し、異常区間(350〜)でさらに上昇傾向になる(摩擦熱の蓄積)
trend = np.linspace(0, 60, anomaly_end - temp_warning_start)
temp[temp_warning_start:anomaly_end] += trend
# ★追加:異常区間が終わった後(400〜最後)も、恒久的なダメージとして温度が高いままにする
temp[anomaly_end:] += 60
# 回転数: 異常区間で「15%のスリップ(滑り)」を発生させる
rpm[anomaly_start:anomaly_end] = rpm[anomaly_start:anomaly_end] * 0.85 + np.random.normal(0, 30, 50)
# 圧力: 異常区間(350〜)で高いまま張り付く
pressure[anomaly_start:anomaly_end] = 90 + np.random.normal(0, 1, 50)
return pd.DataFrame({'Speed': speed, 'RPM': rpm, 'Temp': temp, 'Pressure': pressure})
# ---------------------------------------------------------
# 2. 共通のグラフ描画関数(2軸で4変数を1つにまとめる)
# ---------------------------------------------------------
def plot_multivariate_result(df, score_col, title, color='purple'):
fig, axes = plt.subplots(2, 1, figsize=(10, 8), sharex=True, gridspec_kw={'height_ratios': [1.8, 1]})
ax1 = axes[0]
ax2 = ax1.twinx()
# 【第1軸 (左)】 駆動力系:Speed と RPM
l1, = ax1.plot(df['Speed'], label='Speed (速度)', color='gray', alpha=0.7)
l2, = ax1.plot(df['RPM'], label='RPM (回転数)', color='blue', alpha=0.7)
ax1.set_ylabel('Speed / RPM')
# 【第2軸 (右)】 負荷系:Temp と Pressure
l3, = ax2.plot(df['Temp'], label='Temp (温度)', color='red', alpha=0.7)
l4, = ax2.plot(df['Pressure'], label='Pressure (圧力)', color='orange', alpha=0.7)
ax2.set_ylabel('Temp / Pressure')
lines = [l1, l2, l3, l4]
labels = [l.get_label() for l in lines]
ax1.legend(lines, labels, loc='upper left')
ax1.axvspan(300, 350, color='yellow', alpha=0.1, label='温度上昇の予兆')
ax1.axvspan(350, 400, color='pink', alpha=0.2, label='完全な異常発生')
ax1.set_title("Raw Data: 4変数の生データ (速度は正常だが、温度が先行上昇(黄色帯)し、回転数が少し滑る(ピンク帯)")
# 下段:変換後の異常スコア(単変量)
axes[1].plot(df[score_col], color=color, linewidth=2)
axes[1].set_title(title)
axes[1].axvspan(300, 350, color='yellow', alpha=0.1)
axes[1].axvspan(350, 400, color='pink', alpha=0.2)
axes[1].set_xlabel('Time')
plt.tight_layout()
plt.show()マハラノビス距離(Mahalanobis Distance)
「いつものデータの群れ」から、どれくらい外れているかを測る王道の手法です。 単なる直線距離(ユークリッド距離)ではなく、「データの散らばり具合(分散)と、変数間の連動性(共分散)」を考慮して距離を計算します。
- 特徴
「回転数も温度も高い状態」は正常ルートなので距離は近くなりますが、「回転数は低いのに温度が高い状態」は、通常の散らばり方から外れているため「距離が遠い(=異常)」と判定されます。計算が比較的軽く、昔から品質工学(MT法など)でよく使われる信頼性の高い手法です。 - 弱点
マハラノビス距離は、与えられた全データから平均を算出し、『平均状態』として定義します。従って極端な値の変化がその区間に含まれていると、たとえ全体のバランスが変わらなくとも異常として判定します。
例えば、機械の稼働時は停止状態から定常状態へ大きく変化するため、異常と判断されやすくなります。
従って、定常状態に入るまでの間は異常を無視する必要があります。
# ---------------------------------------------------------
# 4. マハラノビス距離の計算と実行
# ---------------------------------------------------------
def calc_mahalanobis_dist(df):
df_calc = df.copy()
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df_calc)
# 4次元空間での共分散行列とその逆行列を計算
cov_matrix = np.cov(scaled_data, rowvar=False)
inv_cov_matrix = np.linalg.inv(cov_matrix)
mean_distr = np.mean(scaled_data, axis=0)
# 4次元空間の中心(正常な群れ)からのマハラノビス距離の2乗を計算
m_dist = [mahalanobis(row, mean_distr, inv_cov_matrix)**2 for row in scaled_data]
df_calc['mahal_dist'] = m_dist
return df_calc
# 実行
df_dummy = generate_multivariate_dummy_data()
df_result2 = calc_mahalanobis_dist(df_dummy)
plot_multivariate_result(
df_result2,
'mahal_dist',
"マハラノビス距離:正常な群れから外れる温度上昇(黄色帯)と15%の滑り(ピンク帯)を検知!",
color='green'
)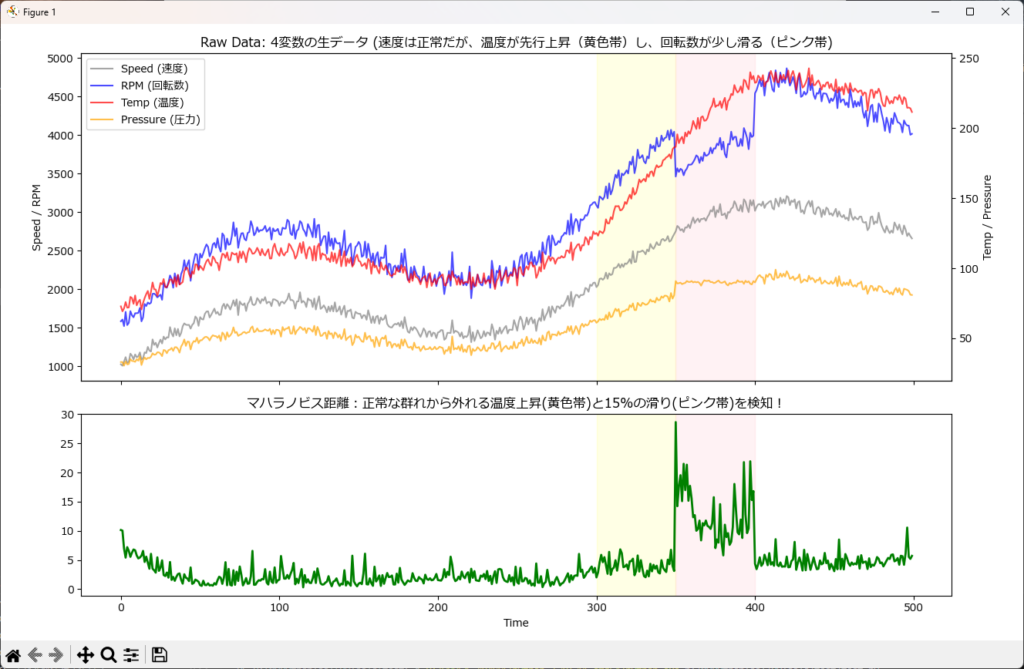
グラフを見ると、マハラノビス距離(緑)は稼働初期(t=0付近)の極端な低速運転に対してスコアが反応してしまっています。これは始動時の状態が、全データの平均(定常状態)から大きく外れた特異な状態であるため、異常として計算されたことが理由です。このような特性を考慮し、実務では始動時から一定期間(ウォームアップ中)は異常判定を無視する(マスキングする)などの対策が必要になります。」
PCA再構成誤差(主成分分析)
一般的なPCA(主成分分析)はデータを圧縮するために使いますが、予兆検知では「圧縮して、もう一度元に戻す(復元する)」という面白いアプローチをとります。
- 考え方
正常時のデータ(例:回転数と温度の連動ルール)をPCAに学習させます。新しいデータが入ってきたとき、一度PCAで次元を落とし、再び元の次元に復元します。 - 特徴
正常な相関を保ったデータは綺麗に復元できますが、相関が崩れた異常データは、元のルールに当てはまらないため元の形に復元できず、大きな「誤差」が生じます。この復元時の誤差(Q統計量)を異常スコアとして使います。多変数(数十個のセンサー)が複雑に絡み合う最新の設備で絶大な威力を発揮します。
# ---------------------------------------------------------
# 3. PCA再構成誤差の計算と実行
# ---------------------------------------------------------
def calc_pca_recon_error(df):
df_calc = df.copy()
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df_calc)
pca = PCA(n_components=1)
pca.fit(scaled_data)
compressed = pca.transform(scaled_data)
reconstructed = pca.inverse_transform(compressed)
df_calc['pca_recon_error'] = np.square(scaled_data - reconstructed).sum(axis=1)
return df_calc
# 実行
df_dummy = generate_multivariate_dummy_data()
df_result1 = calc_pca_recon_error(df_dummy)
plot_multivariate_result(df_result1, 'pca_recon_error', "PCA再構成誤差:目視しづらい温度上昇(黄色帯)と15%の滑り(ピンク帯)の相関崩れを捕捉!")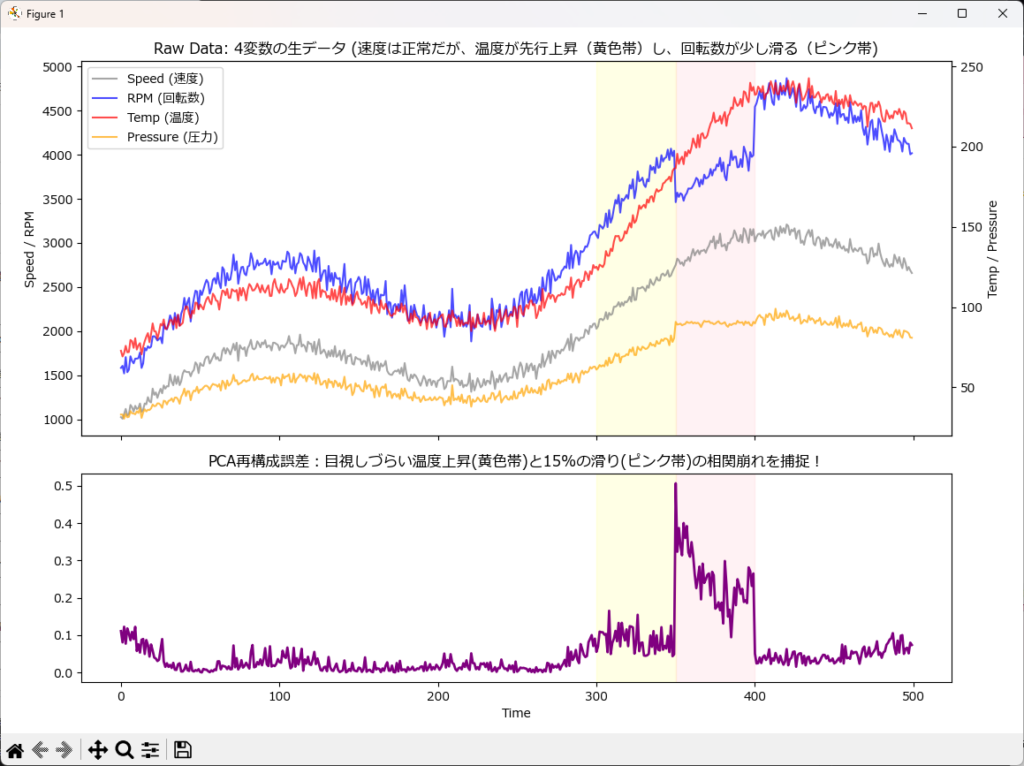
マハラノビス距離は全データの平均を基準とするため、始動時のように「値自体が極端に変化する区間」を異常として拾ってしまう弱点がありました。
PCA再構成誤差は『変数間のバランス(相関ルール)』だけを純粋に評価するため、「速度が低い時は、温度も低い」というルールさえ守られていれば、値自体の変化がどれだけ大きくても異常と判断することはありません。
まとめ
複雑に絡み合う複数センサーのデータも、「次元削減」というアプローチを使えば、相関の崩壊を示すたった1本の波形(単変量)に変換し、Rolling Window(移動窓)を使った特徴量抽出が可能になります。
本記事では、予兆・異常検知で用いられる「次元削減」の紹介と、その中で代表的な「マハラノビス距離」と「PCA再構成誤差」について、具体的なソースコードとグラフを交えて解説しました。
それぞれの手法には異なる特徴(稼働変動への強さなど)がありますので、ご自身の現場の設備特性やテーマに合わせて使い分けしていただければと思います。
単一センサーの監視で限界を感じている方は、ぜひ手元のデータで「相関の崩れ」のスコア化にチャレンジしてみてください。





コメント