
データ分析は、「依頼主が抱える課題を解決する」という目的を達成するためのツールです。必要となるデータを収集、分析、可視化(時にはモデル作成)し、得られた意味のある情報や洞察を用いて課題解決につなげます。
本記事では、入手したデータを用いて、可視化(モデル作成)するまでの手順について詳しく解説します。
これからデータ分析を始める方は、「【成功の秘訣】データ分析で最初に決めておくこと」の記事も併せてご一読くださ
い。
CRISP-DMを使った分析サイクル

CRISP-DM(Cross-Industry Standard Process for Data Mining)とは、データ分析に用いられるプロセスモデル(一連のステップや手順を体系化したも)です。
CRISP-DMは、データ分析プロジェクトを段階的かつ継続的に進めるためのプロセスフレームワークとして定義されており、このステップを逐次的に実行していくことで、効果的なデータ分析を実現します。
図の矢印の向きをご覧ください。「ビジネス課題の理解」と「データの理解」の間、および「データの準備」と「モデル作成」の間が双方向になっているのがわかります。
このように、プロセス間を行き来しながら、ビジネス→データ→モデルへと昇華させていきます。
| ステップ | 概要 |
|---|---|
| ビジネス課題の理解 | ビジネスの目標や課題を理解し、データマイニングプロジェクトの目的を明確にする。 (最初に決めておくこと) |
| データの理解 | データを収集/分析し、その特性や品質を評価する。また、データの問題点やパターンを見つける。 (事前分析、探索的分析) |
| データの準備 | モデリングに必要なデータに対して、クリーニング、統合、選択、変換を施し、データセットをモデリングに適した形式に整形する。 (データクレンジング) |
| モデル作成 | データセットを使用してモデルを構築し、パターンやトレンドを発見する。さまざまなモデルやアルゴリズムを適用し、最も効果的なモデルを特定する。 (モデル選定、特徴量エンジニアリング、モデル作成) |
| 評価 | 構築したモデルを評価し、ビジネス目標に対する有用性を検証する。モデルの性能を測定し、必要に応じて改善する。 |
| 展開/共有 | モデルを実環境に展開し、ビジネスプロセスに統合する。モデルの利用方法を文書化し、保守・監視を行う体制を確立する |
CRISP-DM(Cross-Industry Standard Process for Data Mining)は、1996年から1997年にかけて、欧州のデータマイニングユーザーグループ(European Union-funded CRISP project)によって開発されたプロセスモデルです。このプロジェクトの目的は、データマイニングとデータ分析の業界標準のプロセスモデルを策定することでした。CRISP-DMの開発には、欧州の多くの企業や機関が参加し、業界の専門家からのフィードバックや貢献が取り入れられました。
データ分析手順
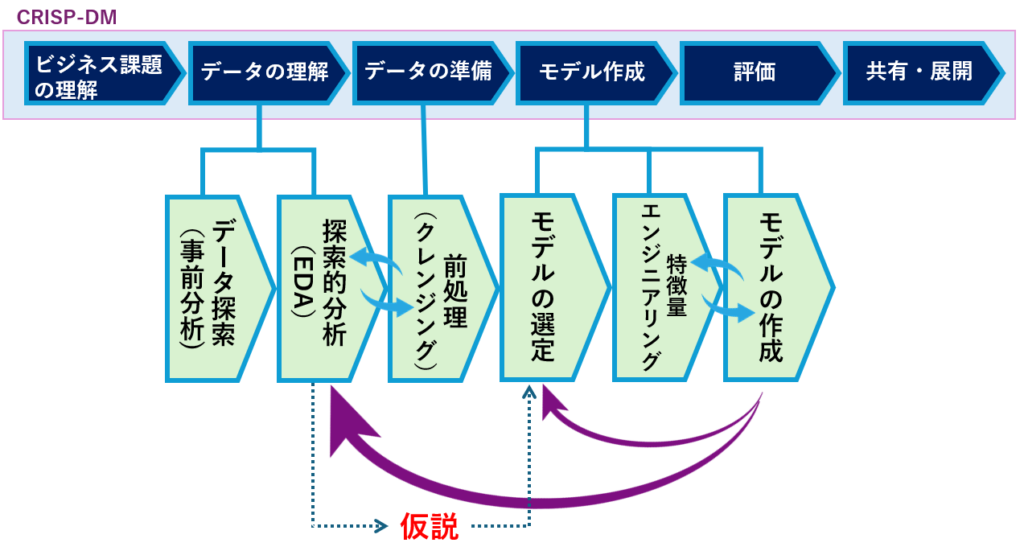
データ分析の手順について、さらに詳しく見ていきましょう。CRISP-DMの「データ理解」、「データ準備」、「モデル作成」のプロセスは、図のようにさまざまなタスクに分解されます。
また、各タスクは一度だけではなく、タスクの結果に応じて何度も繰り返し実行され、最終的なモデルの作成へとつなげられます。
完成したモデルの精度が期待に達しなかった場合や、より良い方法が見つかった場合には、前のタスクに戻ったり、時にはデータの収集に戻ることもあります。
「データ探索(事前分析)」と「探索的データ分析(EDA)」は非常に関連が深く、しばしば同義として扱われることがあります。両者とも、データの特性や品質を理解し、パターンや問題点を見つけ出すための初期段階の分析手法です。この段階では、データの概要を把握し、分析における次のステップに進むための基盤を築くことが主な目的となります。
データ探索(事前分析)
データ分析の最初のステップは、データ自体を理解することです。この段階では、データのソース、形式、内容を調査し、データにどのような問題があるかを特定します。具体的には、以下の作業を行います。
| 作業項目 | 作業内容 |
|---|---|
| データのソースを確認する | データの入手先や収集方法、信頼できるソースであるかを確認する。 |
| データの形式を確認する | データはどのような形式(テキスト、バイナリ、CSV、Json、DBなど)で保存されているかを確認する。 |
| データの内容を確認する | データにはどのような変数 (列) が含まれており、各変数の意味は何なのかを確認する。 |
| データの欠損値や異常値を確認する | データに欠損値や異常値があるかどうかを確認し、必要に応じて処理を行う。 |
| データの分布や傾向を確認する | 可視化ツールを用いて、データをヒストグラムや散布図などで可視化し、分布や傾向を把握する。 |
更に詳しい情報と合わせて、可視化のためのPythonプログラムを「【成功の秘訣】データ探索(事前分析)の手順と方法を解説(可視化ソースコード有り)」の記事で紹介しています。
探索的データ分析(EDA)
データ探索の次のステップは、EDA (Exploratory Data Analysis) です。EDAは、データの特徴、構造、異常値などを体系的に分析することで、そこから仮説を導き出し、分析方針を選定するための活動です。統計分析、機械学習、データ可視化などの手法を組み合わせることで、データの本質を深く理解することを目的としています。具体的には、以下の作業を行います。
| 作業項目 | 作業内容 |
|---|---|
| データの統計量を計算する | データの平均値、標準偏差、最小値、最大値などの統計量を計算します。 |
| データの分布を分析する | データの分布が正規分布に従っているかどうか、偏りや裾野の状態などを分析します。 |
| 変数間の関係性を分析する | 相関分析や回帰分析などの手法を用いて、変数間の関係性を分析します |
| データのクラスタリングを行う | K-means法や階層的クラスタリングなどの手法を用いて、データのクラスタリングを行います。 |
| データの次元削減を行う | 主成分分析などの手法を用いて、データの次元削減を行います。 |
| 分析方針を選定する | ここまでに得られた結果や知見をもとに、分析方針を選定します。 |
更に詳しい情報と合わせて、探索的データ分析で便利なPythonプログラムを「【成功の秘訣】探索的データ分析(EDA)の手順と方法を解説(コピペで使えるPythonサンプルコード付き)」の記事で紹介しています。
前処理(クレンジング)
EDAで得られた知見に基づいて、データの前処理 (クレンジング) を行います。前処理では、データの欠損値や異常値を処理し、データの品質を向上させます。具体的には、以下の作業を行います。
| 作業項目 | 作業内容 |
|---|---|
| 欠損値の処理 | 欠損値を削除する、または平均値や中央値、機械学習アルゴリズムなどを用いて補完します。 |
| 異常値の処理 | 異常値を削除する、またはWinsorizingやZ-score変換などの方法で処理します。 |
| データのスケーリング | データを標準化や正規化などの方法でスケーリングします。 |
| カテゴリーデータのエンコード | カテゴリー変数を数値に変換するなどの処理を行います。 |
データ品質が悪くて探索的分析(EDA)が進まない場合、先に前処理を実施してから探索的分析(EDA)を行うこともよくあります。
更に詳しい情報と合わせて、前処理(クレンジング)で便利なPythonプログラムを「【成功の秘訣】前処理(クレンジング)の手順と方法を解説(コピペで使えるPythonサンプルコード付き)」の記事で紹介しています
モデルの選定
分析目的とデータの特徴に基づいて、分析で用いるモデルやアルゴリズムを具体的に選択します。最初に決めた分析方針に問題がなければ、その時に決めた分析モデルを使用することになりますが、EDAやクレンジングの結果を受けて別のモデルに切り替えることもあります。
| 分析の目的 | 分析手法 | モデル/アルゴリズム |
|---|---|---|
| データをグループに分ける | クラスタリング | K-means, 階層的クラスタリング, DBSCAN |
| カテゴリーを予測する | 分類 | 決定木, ランダムフォレスト, SVM, ニューラルネットワーク |
| 数値を予測する | 回帰 | 線形回帰, リッジ回帰, LASSO, 勾配ブースティング |
| よく一緒に起こるパターンを見つける | アソシエーション分析 | アプリオリ, FP-growth |
| 重要な特徴を見つける | 特徴選択/抽出 | TF-IDF, 主成分分析 (PCA), LDA |
| 異常なデータを見つける | 異常検知 | イソレーションフォレスト, ワンクラスSVM, LOF |
| データの次元を減らす | 次元削減 | 主成分分析 (PCA), t-SNE, LDA |
| 時系列データを分析する | 時系列分析 | ARIMA, 指数平滑法, LSTM |
| テキストデータを分析する | テキストマイニング | BoW (Bag of Words), TF-IDF, Word2Vec |
| 画像データを分析する | 画像分析 | 畳み込みニューラルネットワーク (CNN), オートエンコーダ |
| データ間の関係や重要なノードやグループを見つける | ネットワーク分析 | グラフニューラルネットワーク(GNN)、ページランク、コミュニティ検出アルゴリズム(モジュラリティ最大化、Girvan-Newman法) |
更に詳しい情報については、「【成功の秘訣】モデルの選定手順と方法を解説(コピペで使えるPythonサンプルコード付き)」の記事で紹介しています。
特徴量エンジニアリング
モデルの精度を向上させるために、特徴量エンジニアリングを行います。特徴量エンジニアリングとは、機械学習モデルの性能向上に寄与する特徴量の選択、変換、生成を行うことです。具体的には、以下の作業を行います。
| 作業項目 | 作業内容 |
|---|---|
| 特徴量の選択 | 重要度の高い特徴量のみを選択し、モデルの精度を向上させます。 |
| 特徴量のスケーリング | データを標準化や正規化などの方法でスケーリングします。 |
| 新しい特徴量の生成 | 既存の特徴量を組み合わせたり、変換したりして、新しい特徴量を生成します |
更に詳しい情報については、「【成功の秘訣】特徴量エンジニアリングの手順と方法を解説(コピペで使えるPythonサンプルコード付き)」の記事で紹介しています。
モデル作成
特徴量エンジニアリングを通して作成したデータ(学習データ)を使ってモデルを学習させ、テストデータを用いて性能評価を行う作業です。
性能評価の結果が思わしくない場合、モデルごとの設定値(ハイパーパラメータ)を調整し、再びモデルを学習させ、性能を評価します。時には前工程(特徴量エンジニアリングや前処理、EDAなど)にさかのぼって作業を行うこともよくあります。
| 作業項目 | 作業内容 |
|---|---|
| モデルの学習 | データを用いてモデルを学習させます。 |
| モデルの評価 | 交差検証やテストデータを用いてモデルの精度を評価します。 |
| パラメータ・チューニング | モデルごとに用意されているハイパーパラメータの最適値を見つけます。 |
ここでの評価はCRISP-DMでいうところの評価とは異なります。CRISP-DMは一通りモデルが完成した段階で評価するものであるのに対して、ここでいう評価はモデル作成時の試行錯誤における精度の向上を確認することです。
更に詳しい情報については、「【成功の秘訣】モデルの作成手順と方法を解説(コピペで使えるPythonサンプルコード付き)」の記事で紹介しています。
まとめ
本記事では、「データの理解」「データの準備」「モデル作成」に焦点を当て、以下の内容について詳しく説明しました。
- データ探索(事前分析)
- 探索的分析(EDA)
- 前処理(クレンジング)
- モデルの選定
- 特徴量エンジニアリング
- モデルの作成
データ分析は、課題解決に向けた強力なツールです。データ収集・分析・可視化・モデル作成の手順を踏むことで、意味のある情報や洞察を得ることができます。
CRISP-DMは、データ分析プロジェクトを段階的に進めるためのフレームワークです。具体的には
「ビジネス課題の理解」「データの理解」「データの準備」「モデル作成」「評価」「展開/共有」
という6個のフェーズで構成されています。
CRISP-DMの枠組みとデータ分析の手順に従うことで、効果的なデータ分析が可能になります。本記事の内容をテンプレートとして活用して頂ければ幸いです。







コメント