
機械学習のアルゴリズムにはさまざまな選択肢がありますが、「高い予測精度を維持しながら、モデルの汎化性能を向上させ、複数の手法を組み合わせて最適な学習を実現したい!」そんな場面で頼れるのが スタッキング(Stacking) です。
スタッキング は、異なる機械学習モデルを組み合わせるアンサンブル学習の一種であり、複数の学習器を統合することで、各モデルの強みを活かしながら予測精度を向上させる手法 です。個々の学習器が異なる特徴を捉えるため、単一モデルよりも より柔軟で高精度な予測が可能 になります。さらに、メタモデル(Blender)を活用することで、個々の学習器の出力を最適に統合し、最終的な予測を生成します。
本記事では、スタッキングを活用して分類問題と回帰問題を解く方法を、サンプルコード付きで分かりやすく解説 します。
Pythonでの実装方法はもちろん、ランダムフォレストやブースティング系アルゴリズム(XGBoost、LightGBM、CatBoost、AdaBoost)との違い、メリット・デメリット、パラメータチューニングのポイントまで幅広く網羅しているので、スタッキングを活用してモデルの精度を向上させたい方は、ぜひご一読ください!
スタッキングとは
スタッキング(Stacking) は、異なる機械学習モデルを組み合わせて精度を向上させるアンサンブル学習の手法です。CatBoost のようなブースティングアルゴリズムと他のモデルを組み合わせることで、個々のモデルの弱点を補完しながら、より強力な予測モデルを構築できます。
スタッキングの大きな特徴は、ベースモデルの異なる予測結果を統合し、最適なメタモデルを学習することで、汎化性能を向上させる 点にあります。例えば、決定木・線形回帰・SVM・CatBoost などを組み合わせて適用できるため、複雑なデータに対しても柔軟に対応可能です。
また、カテゴリ変数を含むデータの処理においても、スタッキングを活用することで、複数のモデルが異なる特徴を学習し、総合的な予測精度を向上させることが可能 です。特に、大規模データの分析や Kaggle コンペなどでは、スタッキングを利用することで競争力の高いモデルを構築できます。
このような特性を活かし、スタッキングは 異なるモデルの強みを最大限に活用し、精度向上と汎化性能の向上を同時に実現できる 強力な手法として注目されています。

スタッキングの仕組み
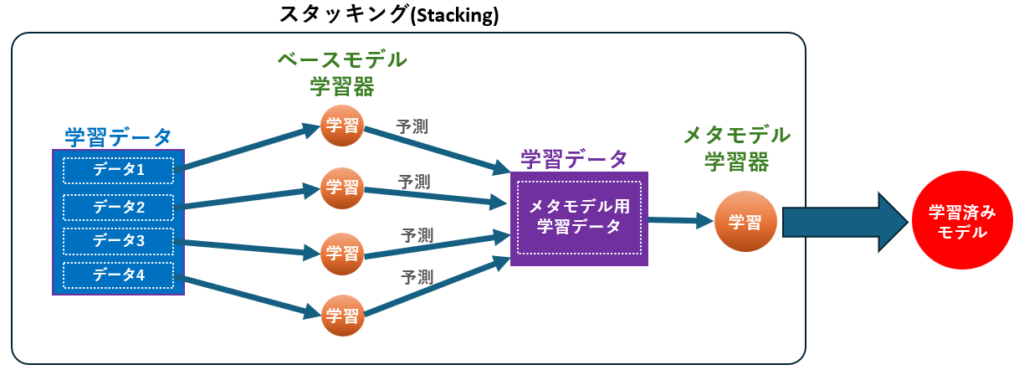
スタッキングの構築プロセスも、アンサンブル学習の考え方に基づいていますが、異なるモデルの組み合わせ や 予測精度の向上 のための独自の工夫が施されています。
スタッキングの学習ステップ
- ベースモデルの学習:
複数の機械学習モデル(決定木・線形回帰・ブースティングモデルなど)をそれぞれ学習し、各モデルの予測結果を取得します。 - メタモデルの学習:
ベースモデルの予測結果を新たな特徴量として扱い、それを学習データとして別のモデル(メタモデル)を訓練します。メタモデルには 線形回帰、ランダムフォレスト、ニューラルネットワークなどを活用可能 です。 - 最終予測:
メタモデルが複数のベースモデルの予測結果を統合し、最適な予測値を算出します。異なるモデルの強みを活かすことで、単一モデルより高い精度を実現できます。
このように、スタッキングは 異なるアルゴリズムの強みを組み合わせることで、モデルの汎化性能を向上させ、予測精度を高める ことができる手法です。
決定木・ランダムフォレストとの違い
| 特徴 | 決定木 | ランダムフォレスト | スタッキング |
|---|---|---|---|
| 構造 | 1本の木 | 複数の木(並列) | 異なるモデルを統合(多層構造) |
| 過学習のしやすさ | 高い | 低い | 低い(異種モデルの組み合わせにより抑制) |
| 学習速度 | 速い | 遅い | 遅い(複数モデルの学習が必要) |
| 精度 | 単純なデータで高い | 複雑なデータで高い | 非常に高い(複数モデルの相乗効果) |
| 特徴量選択 | 全特徴量 | ランダムに一部選択 | 各モデルが異なる特徴を学習 |
| スケーラビリティ | 低い | 高い | 高い(複数のモデルを適用可能) |
スタッキングのメリット・デメリット
スタッキングは、異なるモデルの長所を統合することで、単一モデルでは達成できない精度向上を可能にする 強力な手法ですが、計算コストや適用場面の見極めが重要です。
メリット
- 高精度な予測 → 単一モデルよりも精度が向上し、多くのケースで最適な結果を得やすい
- 非線形な関係も学習可能 → 異なるアルゴリズムの組み合わせにより複雑な関係を捉えられる
- モデルの補完効果 → ベースモデルごとに異なる特徴を学習し、弱点を補完することで安定した予測が可能
- カスタマイズ性が高い → 決定木・線形モデル・ブースティング系など、幅広いモデルを組み合わせて調整できる
デメリット
- 学習コストが高い → 複数のモデルを組み合わせるため、単一モデルより計算時間が長くなる
- ハイパーパラメータ調整が複雑 → 各ベースモデルとメタモデルの最適化が必要で、設定を誤ると精度が低下する
- リアルタイム処理には不向き → 推論速度が比較的遅く、即時の予測が求められる場面には適さない
スタッキングに適したデータ
向いているデータ
- 特徴量が多く、複雑なパターンを持つデータ
- 金融・医療・製造業など、高精度な予測が求められる業務
- カテゴリ変数を多く含む構造化データ(数値・カテゴリデータ)
- 回帰・分類どちらにも対応したいタスク
向いていないデータ
- リアルタイム予測が必要なシステム(推論速度がネック)
- 非常に高次元・スパースなデータ(例:生のテキストデータ)
- ノイズの多いデータ(過学習しやすいため注意が必要
製造業におけるスタッキングの活用例
製造業において、スタッキングは次の用途で使われています。
主な活用例
| 用途 | 概要 | タイプ | 具体例 |
|---|---|---|---|
| 異常検知 | センサーデータから異常パターンを検出し、予防保全や品質向上に貢献 | 分類 | 振動・温度・電流などの変動パターンから異常兆候を自動検出 |
| 故障予測 | 機械の状態を学習し、故障の予兆を捉える | 分類 | 異常振動の継続時間や加速度傾向をもとにベアリングの故障を予測 |
| 品質予測 | 製造条件と品質データを関連づけ、不良品の発生を抑制 | 回帰 | 温度・圧力・回転数から製品の寸法ばらつきを予測 |
| 需要予測 | 時系列データに基づき、将来の需要や在庫変動を予測 | 回帰 | 生産計画や仕入れ戦略の最適化 |
| 故障分類 | 故障発生時、その原因(電気系/機械系など)を分類 | 分類 | ログデータやセンサー値から適切な対応部門を特定 |
| 生産量最適化 | プロセス条件を調整し、最大効率の生産体制を実現 | 回帰 | 材料投入量・加工時間・気温などから最適な生産条件を推定 |
| エネルギー消費予測 | 設備や工場全体の電力使用量を予測し、省エネ施策やコスト削減に貢献 | 回帰 | 月別・時間帯別の使用傾向からピーク電力を予測し契約電力を最適化 |
スタッキングによる分類問題の解き方
スタッキングで分類問題を解く場合、ベースモデルとメタモデルの組み合わせを一覧にまとめました。
今回のサンプルプログラムは、ベースモデルにCatBoostRegressor、メタモデルにLogisticRegressionを採用しています。
| モデルの役割 | よく使われるモデル例 | 特徴 |
|---|---|---|
| ベースモデル | RandomForestClassifier | 安定して高精度、バランスの良い性能 |
GradientBoostingClassifier(例:XGBoost, LightGBM) | 強力な学習器で、Kaggleでも人気 | |
CatBoostClassifier | カテゴリ変数が多い場合に有利 | |
SVC(Support Vector Classifier) | 高次元に強い、少量データで高性能 | |
KNeighborsClassifier | 距離ベースで直感的、ローカルな構造に強い | |
| メタモデル | LogisticRegression | 解釈性が高く、分類に特化 |
RidgeClassifier | 線形で正則化あり、過学習抑制 | |
GradientBoostingClassifier | 強力な最終予測器(ただし重くなりやすい) |
1. 事前準備(ライブラリ導入とデータ準備)
まず、以下のライブラリをインストールしてください。
pip install matplotlib
pip install pandas
pip install scikit-learn
pip install catboost次に、スタッキングの分類モデルを試すためのダミーデータを作成します。今回は、7つの特徴量から4クラスを分類するデータを使用します。製造業での応用としては、センサーによる異常検知や製品の不良予測などに置き換えることができます。
from sklearn.datasets import make_classification
import pandas as pd
# ダミーデータ作成
X, y = make_classification(
n_samples=1000,
n_features=7,
n_informative=5,
n_redundant=2,
n_classes=4,
n_clusters_per_class=1,
flip_y=0.05,
random_state=42
)
# データフレーム化
df = pd.DataFrame(X, columns=[f"特徴量_{i+1}" for i in range(7)])
df['正解データ'] = y
# ファイルに保存(任意)
df.to_csv("classification_data.csv", index=False)特徴量_1~7 は一見無秩序に見えるかもしれませんが、CatBoostを用いることで目的変数(分類先)を高精度に予測できます。
スタッキングを用いた分類モデルの学習と評価(サンプルコードと解説)
以下は、スタッキングを用いて分類モデルの学習と評価を行うサンプルコードです。
このまま実行すると学習が始まり、精度評価指標(混同行列、accuracyなど)が出力されます。
学習と評価の部分は、train_stacking_classifierという名前で関数化していますので、コピペでお使いいただけます。
import pandas as pd
import catboost as cb
from sklearn.ensemble import StackingClassifier, RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
def train_stacking_classifier(df, target, columns, base_models, meta_model, test_size=0.2, random_state=42):
"""
スタッキングを用いた分類モデルを構築し、レポートを出力する関数。
引数:
df : pandas.DataFrame
データを含むデータフレーム。
target : str
予測対象となるターゲット列名。
columns : list of str
使用する特徴量の列名のリスト。
base_models : list of tuple
ベースモデルのリスト。各モデルは ('model_name', model_object) の形式。
meta_model : estimator
スタッキングの最終モデル。
test_size : float, optional (default=0.2)
テストデータの割合。
random_state : int, optional (default=42)
乱数シード。
戻り値:
model : StackingClassifier
訓練されたスタッキングモデルのオブジェクト。
cm : numpy.ndarray
混同行列を表す2次元配列。
"""
columns = [col for col in columns if col != target]
X = df[columns]
y = df[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
# スタッキング分類器の作成
model = StackingClassifier(estimators=base_models, final_estimator=meta_model)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred, target_names=[str(i) for i in range(len(df[target].unique()))])
cm = confusion_matrix(y_test, y_pred)
print(f'正解率: {accuracy:.4f}')
print('混同行列: ')
print(cm)
print('分類レポート: ')
print(report)
return model, cm
if __name__ == "__main__":
df = pd.read_csv('classification_data.csv')
# ベースモデルを関数外で作成
catboost_params = {
'loss_function': 'MultiClass',
'iterations': 500,
'learning_rate': 0.1,
'depth': 6,
'random_seed': 42
}
base_models = [
('catboost', cb.CatBoostClassifier(**catboost_params, verbose=False)),
('rf', RandomForestClassifier(n_estimators=100, random_state=42))
]
# メタモデルを関数外で作成
meta_model = LogisticRegression()
# スタッキング分類器を訓練
model, cm = train_stacking_classifier(df, target='正解データ', columns=df.columns,
base_models=base_models, meta_model=meta_model)
正解率: 0.9300
混同行列:
[[45 1 1 4]
[ 0 46 0 0]
[ 2 0 49 2]
[ 0 2 2 46]]
分類レポート:
precision recall f1-score support
0 0.96 0.88 0.92 51
1 0.94 1.00 0.97 46
2 0.94 0.92 0.93 53
3 0.88 0.92 0.90 50
accuracy 0.93 200
macro avg 0.93 0.93 0.93 200
weighted avg 0.93 0.93 0.93 200
分類結果(混同行列)の視覚化

混同行列を可視化すると、結果が直感的に分かり易くなります。下記がそのサンプルです。 plot_confusion_matrixという関数名にしていますので、コピペで利用可能です。
#---------------------------------------------------------------
# この部分に、前述した train_stacking_classifier関数 を張り付けて下さい
#---------------------------------------------------------------
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rcParams
import pandas as pd
import catboost as cb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
rcParams['font.family'] = 'Meiryo'
def plot_confusion_matrix(cm, class_names=[]):
"""
混同行列をプロットする関数。
引数:
cm : numpy.ndarray
混同行列を表す2次元配列。
class_names : list of str, optional
クラス名のリスト。省略すると連番が表示される
"""
plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=class_names, yticklabels=class_names)
plt.xlabel('予測ラベル')
plt.ylabel('実際のラベル')
plt.title('混同行列')
plt.show()
if __name__ == "__main__":
df = pd.read_csv('classification_data.csv')
# ベースモデルを関数外で作成
catboost_params = {
'loss_function': 'MultiClass',
'iterations': 500,
'learning_rate': 0.1,
'depth': 6,
'random_seed': 42
}
base_models = [
('catboost', cb.CatBoostClassifier(**catboost_params)),
('rf', RandomForestClassifier(n_estimators=100, random_state=42))
]
# メタモデルを関数外で作成
meta_model = LogisticRegression()
# スタッキング分類器を訓練
model, cm = train_stacking_classifier(df, target='正解データ', columns=df.columns,
base_models=base_models, meta_model=meta_model)
# クラス名を設定して混同行列をプロット
class_names = df['正解データ'].unique().astype(str)
plot_confusion_matrix(cm, class_names=class_names)分類結果の評価
今回のテストデータに対してスタッキングで分類した結果を整理し、評価してみました。
正解率
| 正解率(Accuracy) | 0.93 |
|---|
モデルの全体的な精度は非常に高いと言えます。
混同行列
| 正解の分類クラス | クラス 0の予測件数 | クラス 1の予測件数 | クラス 2の予測件数 | クラス 3の予測件数 |
|---|---|---|---|---|
| クラス 0 | 45 | 1 | 1 | 4 |
| クラス 1 | 0 | 46 | 0 | 0 |
| クラス 2 | 2 | 0 | 49 | 2 |
| クラス 3 | 0 | 2 | 2 | 46 |
クラス0は誤分類が7件、クラス1は誤分類が0件、クラス2は誤分類が2件、クラス3は誤分類が4件であるため、高い精度で分類されていることが分かります。
分類レポート
| クラス | 適合率 (Precision) | 再現率 (Recall) | F1スコア (F1-Score) | サポート (Support) |
|---|---|---|---|---|
| 0 | 0.96 | 0.88 | 0.92 | 51 |
| 1 | 0.94 | 1.00 | 0.97 | 46 |
| 2 | 0.96 | 0.92 | 0.93 | 53 |
| 3 | 0.88 | 0.92 | 0.90 | 50 |
| クラス | 適合率 (Precision) | 再現率 (Recall) | F1スコア (F1-Score) | サンプル数 |
|---|---|---|---|---|
| 正解率(Accuracy) | - | - | 0.93 | 200 |
| マクロ平均 | 0.93 | 0.93 | 0.93 | 200 |
| 加重平均 | 0.93 | 0.93 | 0.93 | 200 |
この分類モデルは 高い精度(正解率 0.93)を達成 しており、特に クラス 1 の予測精度が非常に優れています。クラス 1 の 適合率は 0.94、再現率は 1.00、F1スコアは 0.97 であり、ほぼ完全に正しく予測できています。
一方で、クラス 0 や クラス 3 では多少の誤分類が発生 しており、特にクラス 0 は 適合率 0.96、再現率 0.88 と、適合率は高いものの誤検出が見られます。クラス 3 も 適合率 0.88、再現率 0.92 で、予測の安定性は良好ですが、多少の誤分類が含まれています。
- クラス 0:
合率 0.96、再現率 0.88 → 一部誤分類が発生しているが、高い精度を維持。 - クラス 1:
再現率 1.00 → すべてのクラス 1 のデータを正しく分類できており、非常に高い予測精度を示している。 - クラス 2:
適合率 0.94、再現率 0.92 → モデルはバランスよく分類できているが、わずかに誤分類が見られるため、さらなる最適化の余地がある。 - クラス 3:
適合率 0.88、再現率 0.92 → 一部の誤分類はあるものの、全体として良好な分類性能を維持している。 - マクロ平均(Macro Avg):
適合率 0.93、再現率 0.93、F1スコア 0.93 → 各クラスの分類性能が均等に評価されており、モデルのバランスが良い。 - 加重平均(Weighted Avg):
適合率 0.93、再現率 0.93、F1スコア 0.93 → データの偏りが少なく、全体の分類精度が安定していることを示している。
スタッキングによる回帰問題の解き方
スタッキングで分回帰問題を解く場合、ベースモデルとメタモデルの組み合わせは下記一覧の通りです。
今回のサンプルプログラムは、ベースモデルにCatBoostRegressor+RandomForestRegressor+GradientBoostingRegressor、メタモデルにLinearRegressionを採用しています。
| モデルの役割 | よく使われるモデル例 | 特徴 |
|---|---|---|
| ベースモデル | RandomForestRegressor | 汎用的で頑健、過学習しにくい |
GradientBoostingRegressor(例:XGBoost, LightGBM) | 精度が高く、チューニングしやすい | |
CatBoostRegressor | カテゴリ変数対応、パラメータ調整が少なめ | |
SVR(Support Vector Regressor) | 非線形に強い、特徴量が少ないときに有効 | |
KNeighborsRegressor | シンプル、局所的なパターンに強い | |
| メタモデル | LinearRegression | 解釈性が高い、過学習しにくい |
Ridge/Lasso | 過学習抑制、L1/L2正則化あり | |
GradientBoostingRegressor | 非線形関係をうまく補正できる |
事前準備(ライブラリ導入とデータ準備)
事前に下記3つのライブラリをインストールしてください。
pip install matplotlib
pip install pandas
pip install scikit-learn
pip install catboost
下記は今回の回帰に使うダミーデータの生成プログラムです。7つの特徴量のデータとなります。
import numpy as np
import pandas as pd
# 特徴量の数
n_features = 7
# 各特徴量の標準偏差
std_devs = [1, 1, 1, 1, 1, 1, 1]
# 相関行列の設定(例: 1番目と2番目の特徴量が強い相関を持つ)
correlation_matrix = np.array([
[1, 0.8, 0.2, 0.1, 0.1, 0.1, 0.1],
[0.8, 1, 0.3, 0.2, 0.2, 0.2, 0.2],
[0.2, 0.3, 1, 0.4, 0.3, 0.3, 0.3],
[0.1, 0.2, 0.4, 1, 0.5, 0.5, 0.5],
[0.1, 0.2, 0.3, 0.5, 1, 0.4, 0.4],
[0.1, 0.2, 0.3, 0.5, 0.4, 1, 0.3],
[0.1, 0.2, 0.3, 0.5, 0.4, 0.3, 1]
])
# 共分散行列の計算
covariance_matrix = np.outer(std_devs, std_devs) * correlation_matrix
# ダミーデータの生成
np.random.seed(42)
n_samples = 1000
data = np.random.multivariate_normal(np.zeros(n_features), covariance_matrix, size=n_samples)
# DataFrameに変換
df = pd.DataFrame(data, columns=[f'特徴量_{i+1}' for i in range(n_features)])
# 結果の確認
print(df.head())
# CSVファイルに保存
df.to_csv('regression_data.csv', index=False)下記のグラフは、分類モデル用データ生成で紹介したplot_features_with_histogramを使って描画しました。
スタッキングによる回帰モデルの学習と評価(サンプルコードと解説)
以下は、スタッキングを用いて回帰モデルの学習と評価を行うサンプルコードです。
実行すると学習が始まり、精度評価指標(統計情報、平均絶対誤差、平均二乗誤差、重要度など)が出力されます。
学習と評価の部分は、train_stacking_regressorという名前で関数化していますので、コピペでお使いいただけます。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import StackingRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score, mean_absolute_percentage_error
def train_stacking_regressor(df, target, columns, base_models, meta_model,
test_size=0.2, random_state=42):
"""
スタッキング回帰モデルを学習し、評価指標と特徴量重要度を出力する関数。
"""
columns = [col for col in columns if col != target]
X = df[columns]
y = df[target]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=test_size, random_state=random_state
)
model = StackingRegressor(
estimators=base_models,
final_estimator=meta_model,
passthrough=False,
n_jobs=-1
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 評価指標
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
mape = mean_absolute_percentage_error(y_test, y_pred)
print(f'{target}の統計情報:')
print(f'最小値(Min): {y.min()}')
print(f'最大値(Max): {y.max()}')
print(f'平均値(Mean): {y.mean()}')
print(f'標準偏差(Std): {y.std()}')
print(f'分散(Var): {y.var()}')
print('\n精度評価:')
print(f'平均絶対誤差 (MAE): {mae}')
print(f'平均二乗誤差 (MSE): {mse}')
print(f'ルート平均二乗誤差 (RMSE): {rmse}')
print(f'平均絶対パーセンテージ誤差 (MAPE): {mape}')
print(f'決定係数 (R^2): {r2}')
print("\nベースモデルの特徴量重要度:")
for name, estimator in model.named_estimators_.items():
print(f"\n{name} の特徴量重要度:")
try:
if hasattr(estimator, 'get_feature_importance'):
importances = estimator.get_feature_importance()
elif hasattr(estimator, 'feature_importances_'):
importances = estimator.feature_importances_
else:
print(" → このモデルは特徴量重要度をサポートしていません。")
continue
importance_df = pd.DataFrame({
'特徴量': columns,
'重要度': importances
}).sort_values(by='重要度', ascending=False)
print(importance_df)
except Exception as e:
print(f" → 取得できませんでした: {e}")
return model, y_test, y_pred
if __name__ == "__main__":
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.linear_model import LinearRegression
from catboost import CatBoostRegressor
import pandas as pd
# ベースモデル定義
base_models = [
('catboost', CatBoostRegressor(iterations=100, learning_rate=0.1, depth=6, verbose=0)),
('rf', RandomForestRegressor(n_estimators=100, random_state=42)),
('gb', GradientBoostingRegressor(n_estimators=100, random_state=42))
]
# メタモデル定義
meta_model = LinearRegression()
# データ読み込みと学習
df = pd.read_csv('regression_data.csv')
model, y_test, y_pred = train_stacking_regressor(
df,
target='特徴量_1',
columns=df.columns,
base_models=base_models,
meta_model=meta_model
)特徴量_1の統計情報:
最小値(Min): -3.4181790752853725
最大値(Max): 2.967258816333585
平均値(Mean): -0.018768452256335492
標準偏差(Std): 0.9893707041157269
分散(Var): 0.9788543901624494
精度評価:
平均絶対誤差 (MAE): 0.4940161571746727
平均二乗誤差 (MSE): 0.39083785025245993
ルート平均二乗誤差 (RMSE): 0.6251702570120078
平均絶対パーセンテージ誤差 (MAPE): 2.4204901514147275
決定係数 (R^2): 0.6547601006084105
ベースモデルの特徴量重要度:
catboost の特徴量重要度:
特徴量 重要度
0 特徴量_2 66.085266
1 特徴量_3 7.694162
2 特徴量_4 7.217019
3 特徴量_5 6.702456
5 特徴量_7 6.456585
4 特徴量_6 5.844511
rf の特徴量重要度:
特徴量 重要度
0 特徴量_2 0.705594
4 特徴量_6 0.066200
5 特徴量_7 0.061491
3 特徴量_5 0.056713
1 特徴量_3 0.056181
2 特徴量_4 0.053821
gb の特徴量重要度:
特徴量 重要度
0 特徴量_2 0.837562
5 特徴量_7 0.042185
1 特徴量_3 0.035135
4 特徴量_6 0.031959
3 特徴量_5 0.026935
2 特徴量_4 0.026225
回帰結果の可視化
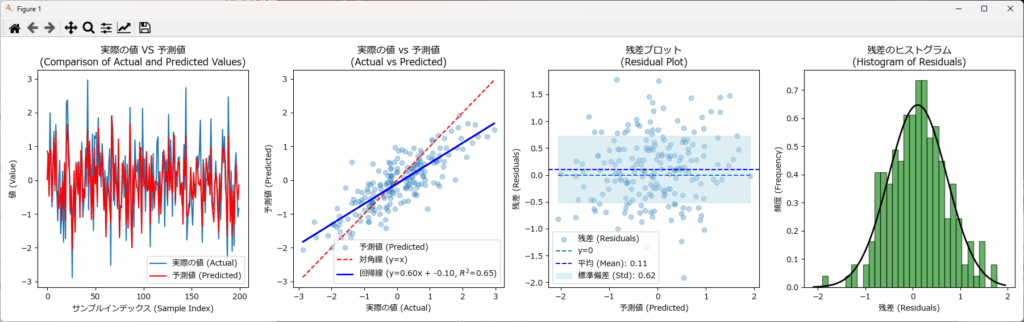
回帰結果を可視化することで、実際の値と予測値との差、残差のバラつき、残差の分布状態が直感的に把握できます。下記がそのサンプルです。 plot_figuresという関数名にしていますので、コピペで利用可能です。
#------------------------------------------------------------------------
# この部分に、前述した train_stacking_regressor関数 を張り付けて下さい
#------------------------------------------------------------------------
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rcParams
import pandas as pd
import catboost as cb
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from scipy.stats import norm
import numpy as np
rcParams['font.family'] = 'Meiryo'
def plot_figures(y_test, y_pred):
residuals = y_test - y_pred
fig, axs = plt.subplots(1, 4, figsize=(18, 5))
axs[0].plot(y_test.values, label='実際の値 (Actual)', linestyle='-', marker=None)
axs[0].plot(y_pred, label='予測値 (Predicted)', color='red', linestyle='-', marker=None)
axs[0].set_xlabel('サンプルインデックス (Sample Index)')
axs[0].set_ylabel('値 (Value)')
axs[0].set_title('実際の値 VS 予測値\n(Comparison of Actual and Predicted Values)')
axs[0].legend()
axs[1].scatter(y_test, y_pred, alpha=0.3, label='予測値 (Predicted)')
axs[1].plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', label='対角線 (y=x)')
slope, intercept = np.polyfit(y_test, y_pred, 1)
r2 = r2_score(y_test, y_pred)
axs[1].plot(y_test, slope * y_test + intercept, color='blue', linestyle='-', linewidth=2,
label=f'回帰線 (y={slope:.2f}x + {intercept:.2f}, $R^2$={r2:.2f})')
axs[1].set_xlabel('実際の値 (Actual)')
axs[1].set_ylabel('予測値 (Predicted)')
axs[1].set_title('実際の値 vs 予測値\n(Actual vs Predicted)')
axs[1].legend()
axs[2].scatter(y_pred, residuals, alpha=0.3, label='残差 (Residuals)')
axs[2].hlines(y=0, xmin=y_pred.min(), xmax=y_pred.max(), linestyles='dashed', label='y=0')
residuals_mean = np.mean(residuals)
residuals_std = np.std(residuals)
sorted_indices = np.argsort(y_pred)
sorted_y_pred = y_pred[sorted_indices]
sorted_upper = residuals_mean + residuals_std
sorted_lower = residuals_mean - residuals_std
axs[2].axhline(y=residuals_mean, color='blue', linestyle='--', label=f'平均 (Mean): {residuals_mean:.2f}')
axs[2].fill_between(sorted_y_pred, sorted_lower, sorted_upper, color='lightblue', alpha=0.4,
label=f'標準偏差 (Std): {residuals_std:.2f}')
axs[2].set_xlabel('予測値 (Predicted)')
axs[2].set_ylabel('残差 (Residuals)')
axs[2].set_title('残差プロット\n(Residual Plot)')
axs[2].legend()
axs[3].hist(residuals, bins=30, edgecolor='k', density=True, alpha=0.6, color='g')
xmin, xmax = axs[3].get_xlim()
x = np.linspace(xmin, xmax, 100)
p = norm.pdf(x, residuals_mean, residuals_std)
axs[3].plot(x, p, 'k', linewidth=2)
axs[3].set_xlabel('残差 (Residuals)')
axs[3].set_ylabel('頻度 (Frequency)')
axs[3].set_title('残差のヒストグラム\n(Histogram of Residuals)')
plt.tight_layout()
plt.show()
if __name__ == "__main__":
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.linear_model import LinearRegression
from catboost import CatBoostRegressor
import pandas as pd
# ベースモデル定義
base_models = [
('catboost', CatBoostRegressor(iterations=100, learning_rate=0.1, depth=6, verbose=0)),
('rf', RandomForestRegressor(n_estimators=100, random_state=42)),
('gb', GradientBoostingRegressor(n_estimators=100, random_state=42))
]
# メタモデル定義
meta_model = LinearRegression()
# データ読み込みと学習
df = pd.read_csv('regression_data.csv')
model, y_test, y_pred = train_stacking_regressor(
df,
target='特徴量_1',
columns=df.columns,
base_models=base_models,
meta_model=meta_model
)
plot_figures(y_test, y_pred)回帰結果の評価
精度の評価
| 指標 | 値 |
|---|---|
| 平均絶対誤差 (MAE) | 0.4940161571746727 |
| 平均二乗誤差 (MSE) | 0.39083785025245993 |
| ルート平均二乗誤差 (RMSE) | 0.6251702570120078 |
| 平均絶対パーセンテージ誤差 (MAPE) | 2.4204901514147275 |
| 決定係数 (R^2 Score) | 0.6547601006084105 |
MAE、MSE、RMSE、MAPEはそれぞれ誤差の指標です。これを評価する前に、予測対象となる特徴量_1の統計情報を確認しておきましょう。
| 最小値 | 最大値 | 平均値 | 標準偏差 | 分散 |
|---|---|---|---|---|
| -3.4182 | 2.9673 | -0.01877 | 0.9894 | 0.9789 |
本モデルの 平均値は -0.0187 であり、0に近い値を示しています。また、データの 約 67% が -0.989~+0.989 の範囲に分布 しており、標準偏差に沿った一般的な分布を持っています。しかし、最小値と最大値の差が大きいため、外れ値の影響を受けやすい可能性 が考えられます。
さらに、MAE・MSE・RMSE の値が比較的高い ことから、誤差が一定の大きさを持っていることが確認できます。特に MAPE(2.47%) は小さく見えますが、MAPE の性質上 0 に近い値が多い場合は誤差が過小評価される可能性 があります。
したがって、この結果だけでモデルの精度を判断するのは危険であり、さらなる評価と改善が必要 です。
決定係数 (R² Score = 0.6517) は 一定の予測精度を示している ものの、実務利用の前にはさらなる調整が求められます。
精度向上のための改善策
次の3つ方法により、精度の改善を目指すべきです。
- ハイパーパラメータの調整:
各ベースモデル(例:CatBoost、ランダムフォレスト、ロジスティック回帰)のlearning_rateやdepthを最適化し、スタッキング全体の性能を向上。 - 特徴量の選択とエンジニアリング:
各ベースモデルが異なる特徴を学習できるように調整し、最終的なメタモデルが高精度な統合を行えるようにする。 - データの前処理:
標準化・スケーリングを行い、すべてのベースモデルが適切なデータを学習できるよう最適化する。
また、可視化の結果からも、誤差があり精度が改善の余地があることが確認できるため、さらに細かい分析を行い、改善策を検討することが必要です。

特徴量の重要度
| 特徴量 (Feature) | 重要度 (Importance) |
|---|---|
| 特徴量_2 | 63.949518 |
| 特徴量_6 | 7.735613 |
| 特徴量_7 | 57.575223 |
| 特徴量_4 | 7.160824 |
| 特徴量_5 | 4476.945596 |
| 特徴量_3 | 6.633226 |
スタッキングでは、各ベースモデルの特徴量重要度を分析し、それぞれのモデルが異なる特徴をどのように活用しているかを確認することが重要です。
各モデルの結果を見ると、特徴量_2 の重要度が高く、スタッキングにおいても この特徴が主要な予測要因 であることが確認できます。
- CatBoost: 特徴量_2 の重要度 66.08 と非常に高く、続いて 特徴量_3~7 が予測に影響を与えている。
- ランダムフォレスト: 特徴量_2 が 0.705 と最も重要であり、次いで 特徴量_6, 7, 5 が予測に寄与。
- GBDT: 特徴量_2 の重要度は 0.837 であり、他の特徴量と比較して圧倒的に影響力が大きい。
この結果から、異なるモデルが共通して特徴量_2を重要視しているため、スタッキングにおいてもこの特徴を適切に活用することが鍵 となります。一方で、特徴量_6 や 特徴量_7 など、モデルによって重要度のばらつきがある特徴も存在しており、これらの情報を活かしてより精度の高い統合モデルを構築できます。
スタッキングを用いることで、各モデルの予測傾向を総合的に評価し、単一モデルでは得られない視点から特徴量選択やモデル最適化を進めることが可能 です。このようなアプローチにより、誤分類を減らしながら、モデルの汎化性能を向上させることが期待できます。
ハイパーパラメータとパラメータチューニングについて
予測精度を向上させるには、ハイパーパラメータの調整が重要です。スタッキングの場合、ベースモデル、メタモデル合わせて複数のモデルを使用するため、モデルごとにハイパーパラメータの調整が必要です。
従って、パラメータチューニングも各モデルごとにグリッドサーチなどで探索する必要があります。
下記はグリッドサーチのサンプルプログラムです。実行するとかなり時間が掛かるため、これを参考に必要な部分だけ切り出すなどしてお使いください。
import pandas as pd
import numpy as np
from sklearn.ensemble import StackingClassifier, RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from catboost import CatBoostClassifier
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score
# ❶ データの読み込みと前処理
df = pd.read_csv("classification_data.csv")
# 目的変数(target)を分離し、特徴量(X)を抽出
X = df.drop(columns=["特徴量_1"]) # "特徴量_1" がターゲット変数
y = df["特徴量_1"]
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ❷ ベースモデルのグリッドサーチ
# 各モデルの最適なハイパーパラメータを探索し、ベストモデルを取得
param_grid_catboost = {'learning_rate': [0.01, 0.1], 'depth': [4, 6, 8]}
grid_catboost = GridSearchCV(CatBoostClassifier(verbose=False), param_grid_catboost, cv=5, n_jobs=-1)
grid_catboost.fit(X_train, y_train)
best_catboost = grid_catboost.best_estimator_
param_grid_rf = {'n_estimators': [100, 200], 'max_depth': [None, 10, 20]}
grid_rf = GridSearchCV(RandomForestClassifier(random_state=42), param_grid_rf, cv=5, n_jobs=-1)
grid_rf.fit(X_train, y_train)
best_rf = grid_rf.best_estimator_
param_grid_xgb = {'learning_rate': [0.01, 0.1], 'max_depth': [3, 6, 9]}
grid_xgb = GridSearchCV(XGBClassifier(use_label_encoder=False, eval_metric='logloss'), param_grid_xgb, cv=5, n_jobs=-1)
grid_xgb.fit(X_train, y_train)
best_xgb = grid_xgb.best_estimator_
# ❸ メタモデル(最終分類器)のグリッドサーチ
param_grid_meta = {'C': [0.1, 1, 10]}
grid_meta = GridSearchCV(LogisticRegression(), param_grid_meta, cv=5, n_jobs=-1)
grid_meta.fit(X_train, y_train)
best_meta_model = grid_meta.best_estimator_
# ❹ スタッキングの構築
stacking_model = StackingClassifier(estimators=[
('catboost', best_catboost),
('rf', best_rf),
('xgb', best_xgb)
], final_estimator=best_meta_model, n_jobs=-1)
# ❺ モデルの学習と評価
stacking_model.fit(X_train, y_train)
y_pred = stacking_model.predict(X_test)
# ❻ 結果の表示
accuracy = accuracy_score(y_test, y_pred)
print(f"スタッキングモデルの正解率: {accuracy:.4f}")スタッキングが簡単に使える自作クラス
CatBoostで分類と回帰のモデルを簡単に作成できるように、必要な機能をまとめたクラスを作りました。
下記に詳しい説明とソースコードを掲載しています。
コピペで使えるようになっていますので、是非ご活用下さい。
【コピペOK】ランダムフォレストやLightGBMを簡単に扱える自作クラスを紹介

まとめ
CatBoost(Categorical Boosting)は、分類問題や回帰問題において高い予測精度を発揮し、特にカテゴリ変数を扱うタスクに最適化された 機械学習アルゴリズムです。
本記事では、CatBoostの基本的な仕組みやメリット・デメリットを解説し、製造業での活用例や具体的な実装方法 について紹介しました。
また、分類や回帰における評価指標や特徴量の重要度解析、さらには効率的なハイパーパラメータチューニングの手法も取り上げました。これらを活用することで、実務においてCatBoostを最適な形で導入し、高精度なモデルを構築することが可能になります。
CatBoostは、順序ベースのブースティング(Ordered Boosting) や カテゴリ変数のエンコーディング不要な処理 を活用することで、従来のGBDTより安定した学習を実現し、複雑なパターンのデータにも強い のが特徴です。
本記事が、皆さんのプロジェクトにおいてCatBoostの導入や活用のヒント になれば幸いです!








コメント