管理人– Author –
-

【Python実践】異常は波の“影”に現れる!側波帯で見抜く異常検知
📡時系列データをフーリエ変換しても、スペクトルに異常は見つからない…。 そんなときは、波の奥にある“周波数の揺らぎ=側波帯”に注目してみましょう。 本記事では、FM変調と側波帯の原理をやさしく解説しながら、 Pythonを使って信号を生成・可視化し、異... -
【Python実践】高次元データをぎゅっと圧縮!代表的な5手法と使い方ガイド
高次元のデータを扱うとき、こんな悩みに遭遇したことはありませんか? 特徴量が多すぎて、モデルの学習がうまくいかない データの可視化が難しく、全体像がつかめない ノイズや冗長な情報が多くて、分析がブレやすい そんなときに役立つのが「次元圧縮(... -
【Python実践】オートエンコーダーで異常検知を行う(コピペで使えるサンプルコード付き)
オートエンコーダ(AutoEncoder)は、機械学習における異常検知手法の一つで、特に複雑な時系列データや高次元データの中から、再現しづらい=異常なパターンを検出できる点で注目されています。 このアルゴリズムは、データを一度圧縮(エンコード)し、... -
【Python実践】それ、分布のズレが原因かも?本番に弱いアンサンブル回帰はAdversarial Validationで改善!(コピペで使えるサンプルコード付き)
モデルの学習はうまくいったのに、本番データでは精度がガクッと落ちる…。 そんなとき、原因は「モデル」ではなく「データの分布のズレ」にあるかもしれません。 本記事では、学習データと本番データの違いを検出する手法「Adversarial Validation」を、ア... -
【Python実践】アンサンブル回帰で効く特徴量を自動選定!Forward/Backwardの実践ガイド(コピペで使えるサンプルコード付き)
アンサンブル回帰モデル(LightGBMやXGBoostなど)を使って高精度な予測を目指すとき、最大のカギとなるのが「どの特徴量を使うか?」という選定プロセスです。 本記事では、“効く特徴量”を自動で見つけるための手法として、Forward SelectionとBackward E... -
【Python実践】設備異常を早期に見抜く!代表的な5つのパターンと対処法
場やプラントの設備は、止まってしまえば生産性や安全性に直結する重要な存在です。しかし、故障や不具合は突然起こるのではなく、必ず小さな「予兆」を伴っています。振動、温度、電流、圧力――日々収集されるセンサーデータの中に、その兆しは隠れていま... -
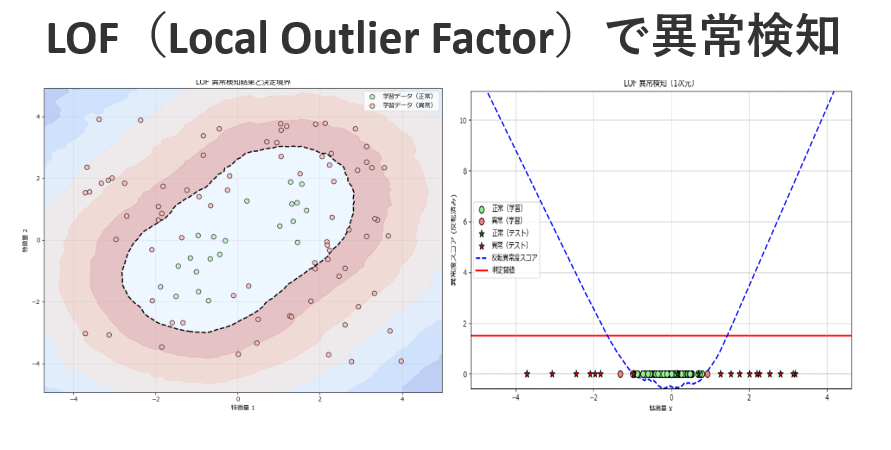
【Python実践】LOF(Local Outlier Factor)で異常検知を行う(コピペで使えるサンプルコード付き)
Local Outlier Factor(LOF)は、機械学習における異常検知手法の一つで、特に複雑なデータ分布の中から局所的に異常なデータポイントを検出できることで注目されています。 このアルゴリズムは、データの「局所的な密度」を基に異常を判定するユニークな... -
【Python実践】「本当に効く」変数はどれか? アンサンブル回帰モデルにおける特徴量の選定手順
センサーやログなど、膨大な時系列データを扱う現場では、「どの変数が予測に効いているのか?」を見極めることが、モデル精度を左右する最重要ポイントです。特にアンサンブル回帰モデル(LightGBMやXGBoostなど)を使う場合、単に相関の高い特徴量を選ぶ... -
【Python実践】大量データの軽量化&可視化実践ガイド
センサーデータやログデータなど、日々蓄積される大量の時系列データには、装置の異常兆候、環境の変化、ユーザー行動のパターンなど、重要な“傾向”が潜んでいます。しかし、何億・何十億行にも及ぶデータをそのまま可視化するのは現実的ではありません。... -
【実践事例】ResNet × PyTorchでロゴを含む画像を見分ける
大量にスキャンされた設計図や技術資料の中から、特定のマークやロゴが含まれているものだけを自動で選別したい。こうしたニーズは、古い図面の整理やドキュメントの分類など、現場業務でしばしば発生します。 このような「画像内に特定の要素が含まれてい...