モデル作成– category –
-

【Python実践】低サンプリングで予兆検知!FFTでリズムの乱れを捕捉しよう!
移動平均や標準偏差によるトレンド監視は、多くの現場で導入されている王道の予兆検知手法です。しかし、統計量が教えてくれるのは、主に値の大きさやばらつきの変化です。 一方で、制御系データ(車速やエンジン回転数など)に潜む異常は、数値の増減では... -
【Python実践】DBSCANの進化版「HDBSCAN」!密度の異なるデータも賢くクラスタリング
HDBSCANは、密度に基づいてデータをグループ化するアルゴリズムで、DBSCANをさらに進化させた手法です。ノイズに強いという特徴はそのままに、「データの密度の違いを自動で判別する」という非常に強力な機能を持っています。 製造業では、センサーから得... -
【Python実践】軸受け(回転系)の異常振動を見つけ出せ!実用エンベローブ解析4つの活用シーン
モーター、ポンプ、減速機——。あらゆる回転系設備のメンテナンスにおいて、避けて通れないのが「ベアリングやギアの異常診断」です。 しかし、初期の摩耗や傷が発する微細な衝撃音は、回転系特有の大きな低周波振動(軸の回転音など)に埋もれやすく、通常... -
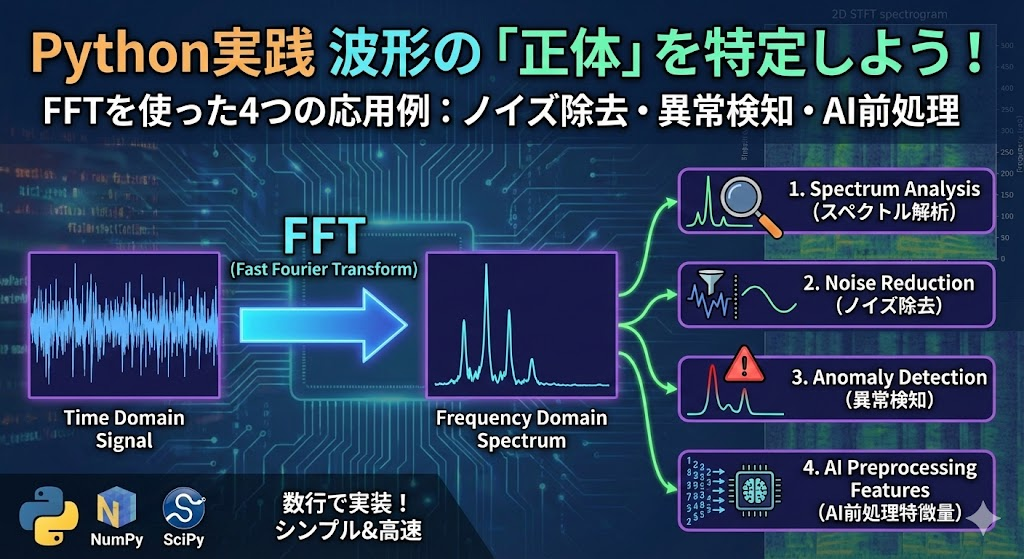
【Python実践】波形の「正体」を特定しよう! FFT(フーリエ変換)を使った4つの応用例~ノイズ除去・異常検知・時間周波数解析、AI前処理~
「STFT」や「ウェーブレット変換」は、「いつ、どんな変化が起きたか」という時間ごとの推移を捉えるには最強のツールです。 しかし、現場のデータ分析では、必ずしも「いつ」の情報が必要なケースばかりではありません。 むしろ、「データ全体に潜む周期... -
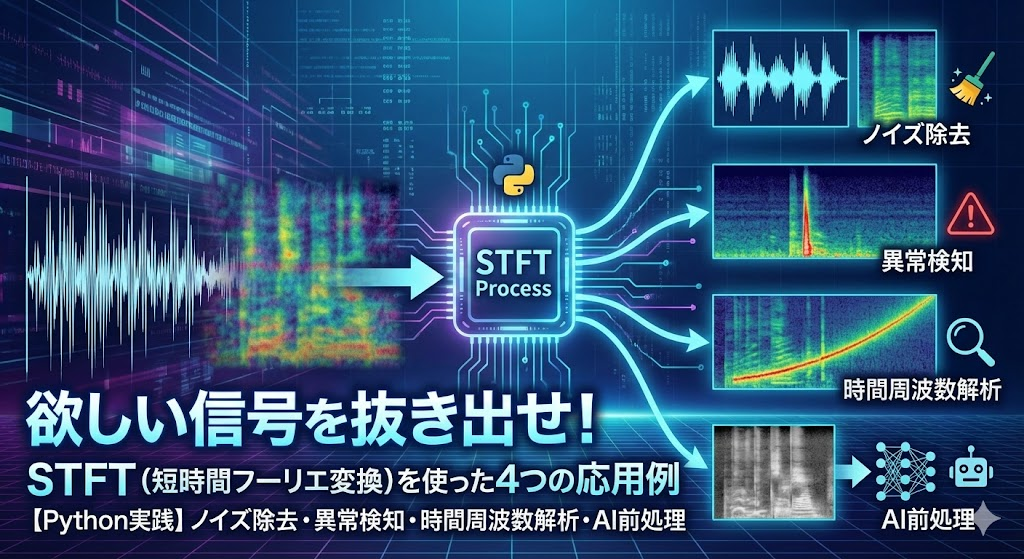
【Python実践】欲しい信号を抜き出せ! STFT(短時間フーリエ変換)を使った4つの応用例~ノイズ除去・異常検知・時間周波数解析、AI前処理~
前回の記事では、鋭い異常変化(スパイク)を捉えるための「ウェーブレット変換」を使って、異常検知・時間周波数解析を行う方法を解説しました。 https://analysis-in-manufacturing.resanaplaza.com/2026/01/17/%e3%80%90python%e5%ae%9f%e8%b7%b5%e3%80... -
【Python実践】ウェーブレット変換で実用「異常検知」~閾値設定から誤検知対策まで~」
「Python実践】欲しい信号を見つけ出せ! ウェーブレット変換を使った3つの応用例~ノイズ除去・異常検知・時間周波数解析~」の記事では、ウェーブレット変換の基礎と、スカログラム(ヒートマップ)を使った「目視による異常検知」のアプローチを紹介し... -
【Python実践】欲しい信号を見つけ出せ! ウェーブレット変換を使った3つの応用例~ノイズ除去・異常検知・時間周波数解析~
センサーデータや振動解析を行っていると、必ずぶつかる壁があります。 「ノイズが酷くて、肝心の信号が見えない」 「FFT(フーリエ変換)をかけたけれど、いつ異常が起きたのか時間がわからない」 そんな時こそ、ウェーブレット変換の出番です。 ウェーブ... -
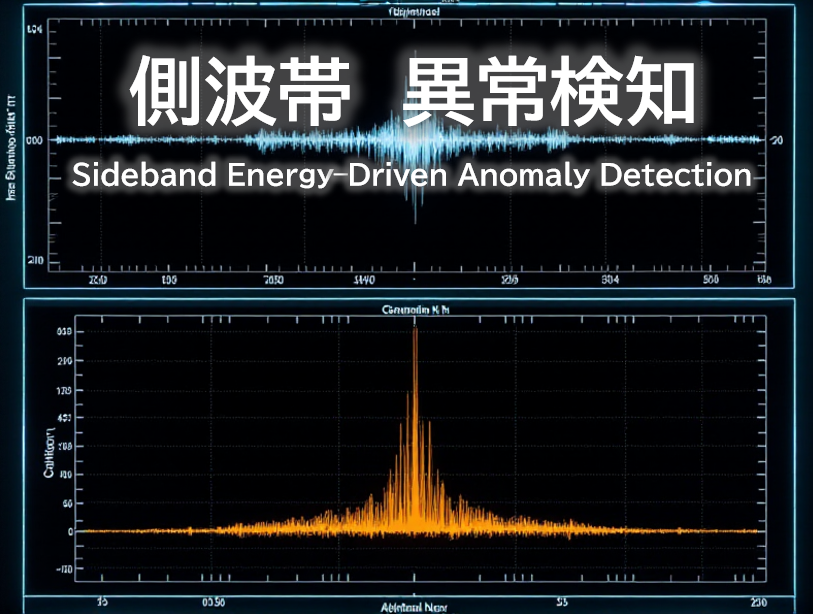
【Python実践】異常は波の“影”に現れる!側波帯で見抜く異常検知
📡時系列データをフーリエ変換しても、スペクトルに異常は見つからない…。 そんなときは、波の奥にある“周波数の揺らぎ=側波帯”に注目してみましょう。 本記事では、FM変調と側波帯の原理をやさしく解説しながら、 Pythonを使って信号を生成・可視化し、異... -
【Python実践】高次元データをぎゅっと圧縮!代表的な5手法と使い方ガイド
高次元のデータを扱うとき、こんな悩みに遭遇したことはありませんか? 特徴量が多すぎて、モデルの学習がうまくいかない データの可視化が難しく、全体像がつかめない ノイズや冗長な情報が多くて、分析がブレやすい そんなときに役立つのが「次元圧縮(... -
【Python実践】オートエンコーダーで異常検知を行う(コピペで使えるサンプルコード付き)
オートエンコーダ(AutoEncoder)は、機械学習における異常検知手法の一つで、特に複雑な時系列データや高次元データの中から、再現しづらい=異常なパターンを検出できる点で注目されています。 このアルゴリズムは、データを一度圧縮(エンコード)し、...